Tom Cunningham surveys metrics for comparing AI agent capability as performance changes with expenditure and relative to human performance.
Parker Whitfill and Tom Cunningham highlight context and takeaways from a new paper modeling how AI may accelerate AI R&D, and whether feedback effects could be strong enough for self-sustaining acceleration.
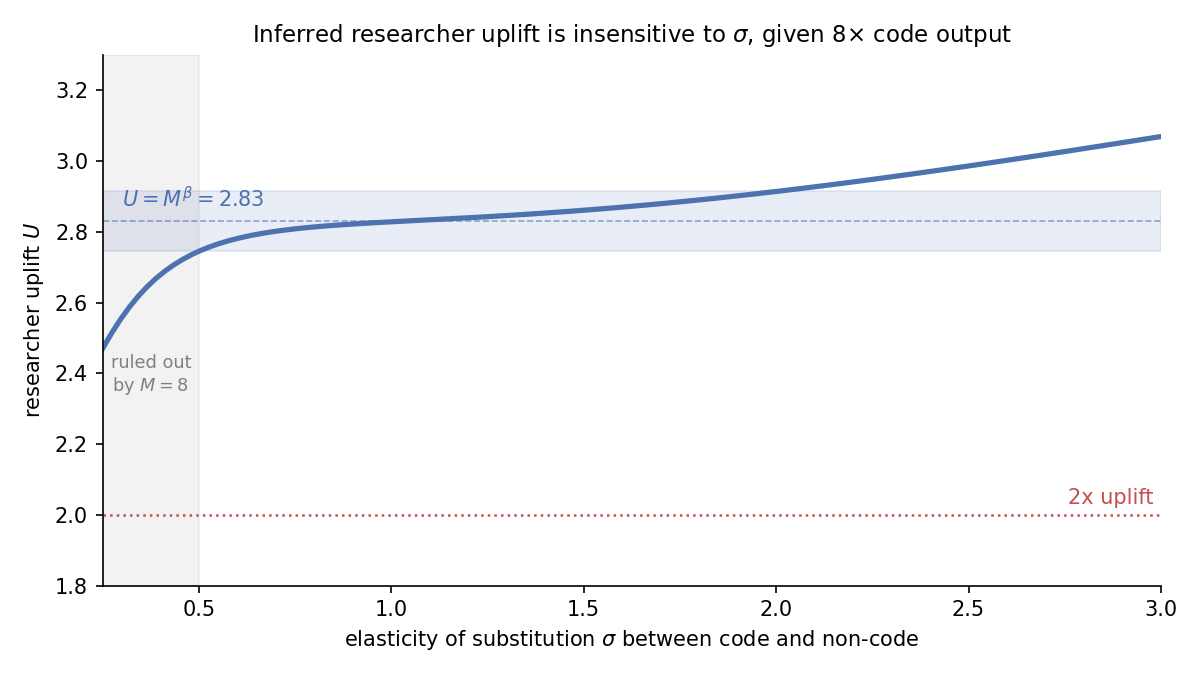
Anthropic reported that contributors merge 8x as much code per day as before AI. Thomas Kwa argues that under standard economic modeling assumptions, this implies the uplift of individual Anthropic researchers from coding agents alone is above 2x.
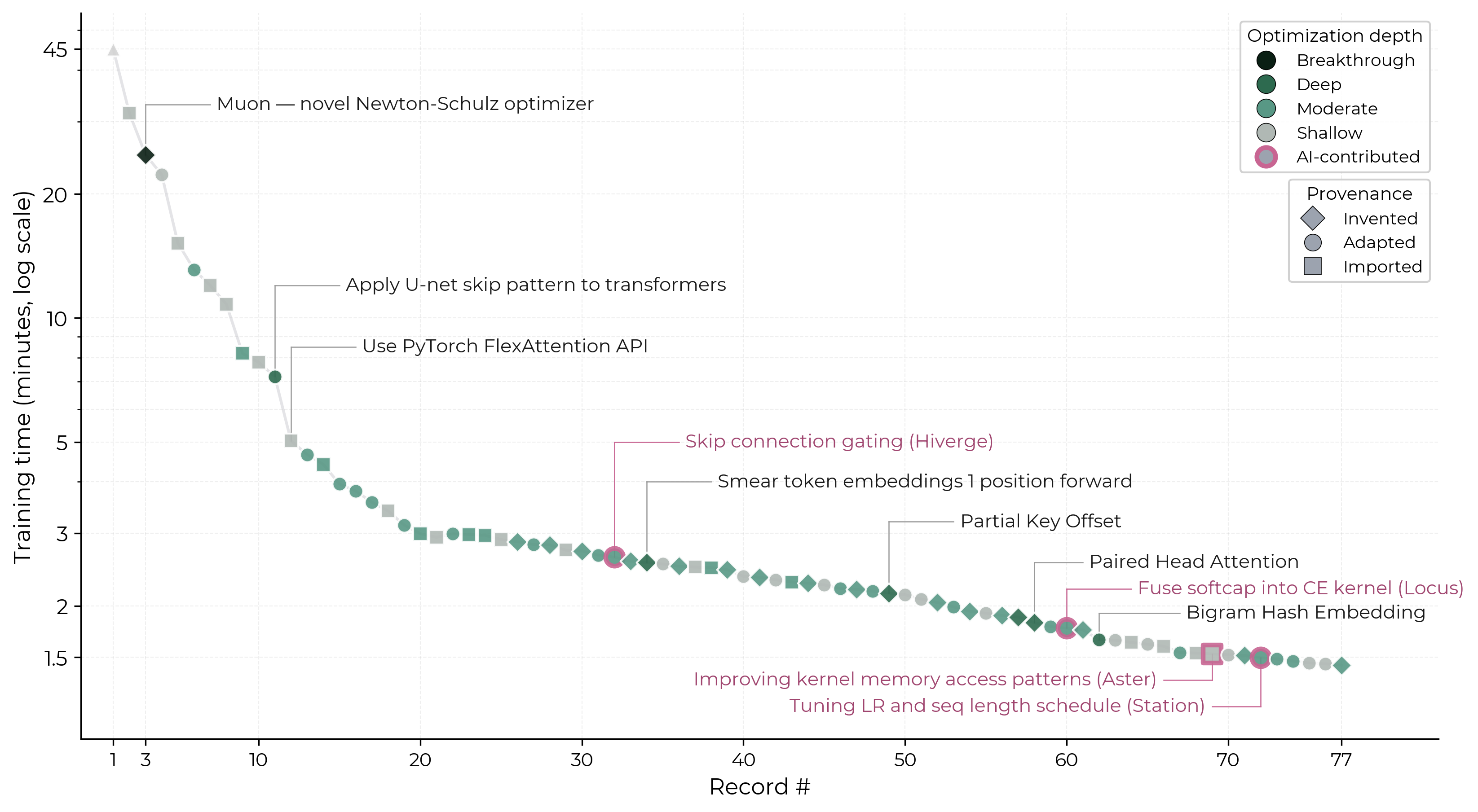
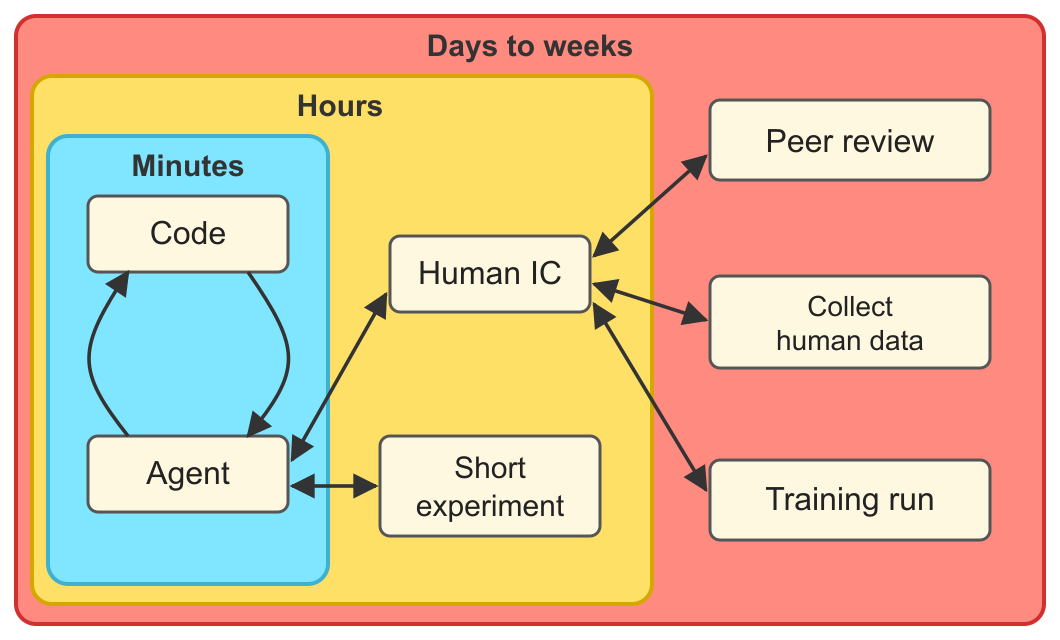
Classifying human and agent contributions to the NanoGPT speedrun, and what publicly tracked challenges can tell us about AI R&D acceleration.
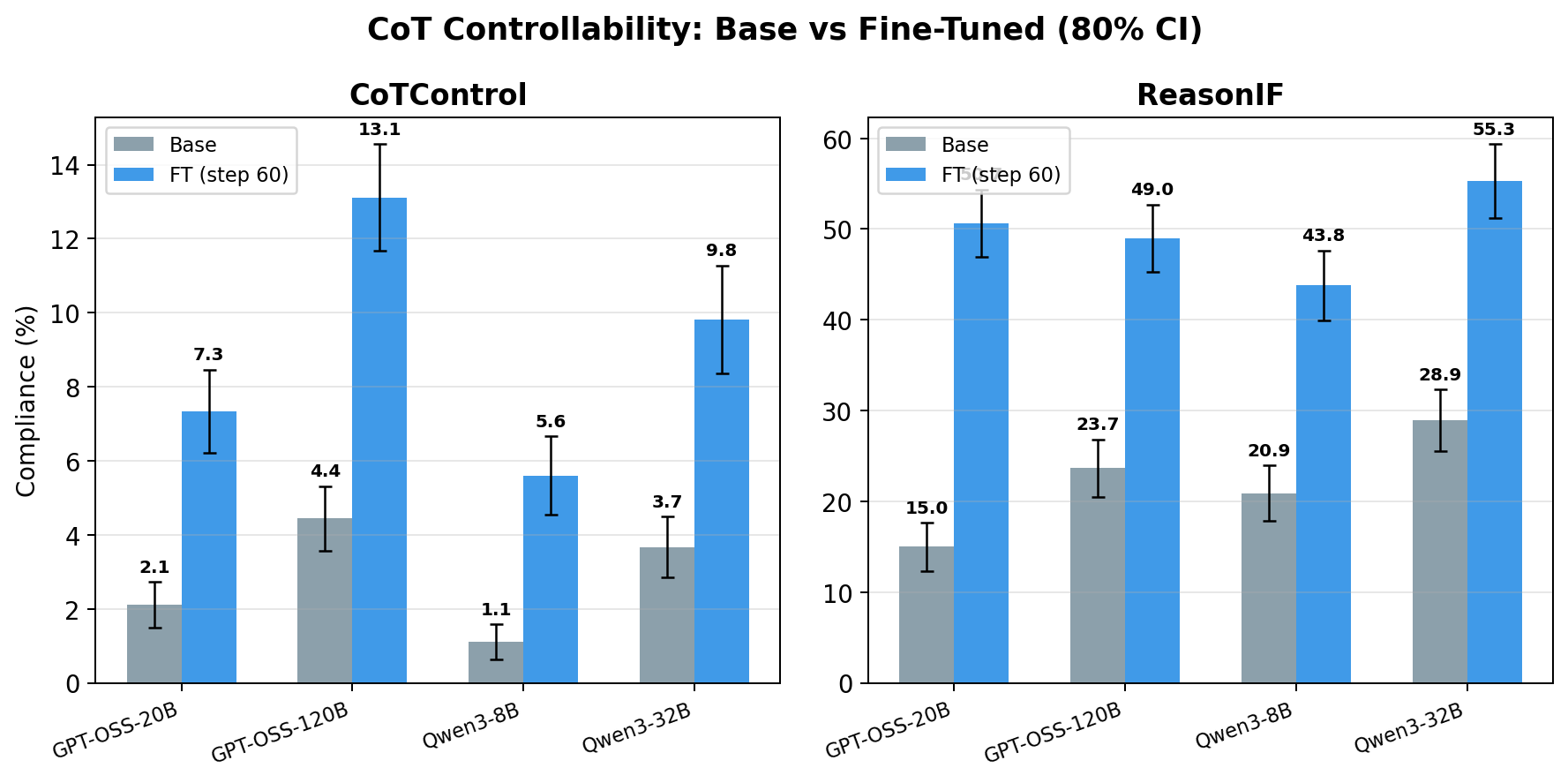
We find that a small amount of fine-tuning on instruction following in the CoT generalizes to meaningful increases in CoT controllability on an out-of-distribution set of tasks. We fine-tune four reasoning models on small datasets of instruction-following reasoning data and OOD controllability rises from an average of 2.9% to 8.8% across four models.
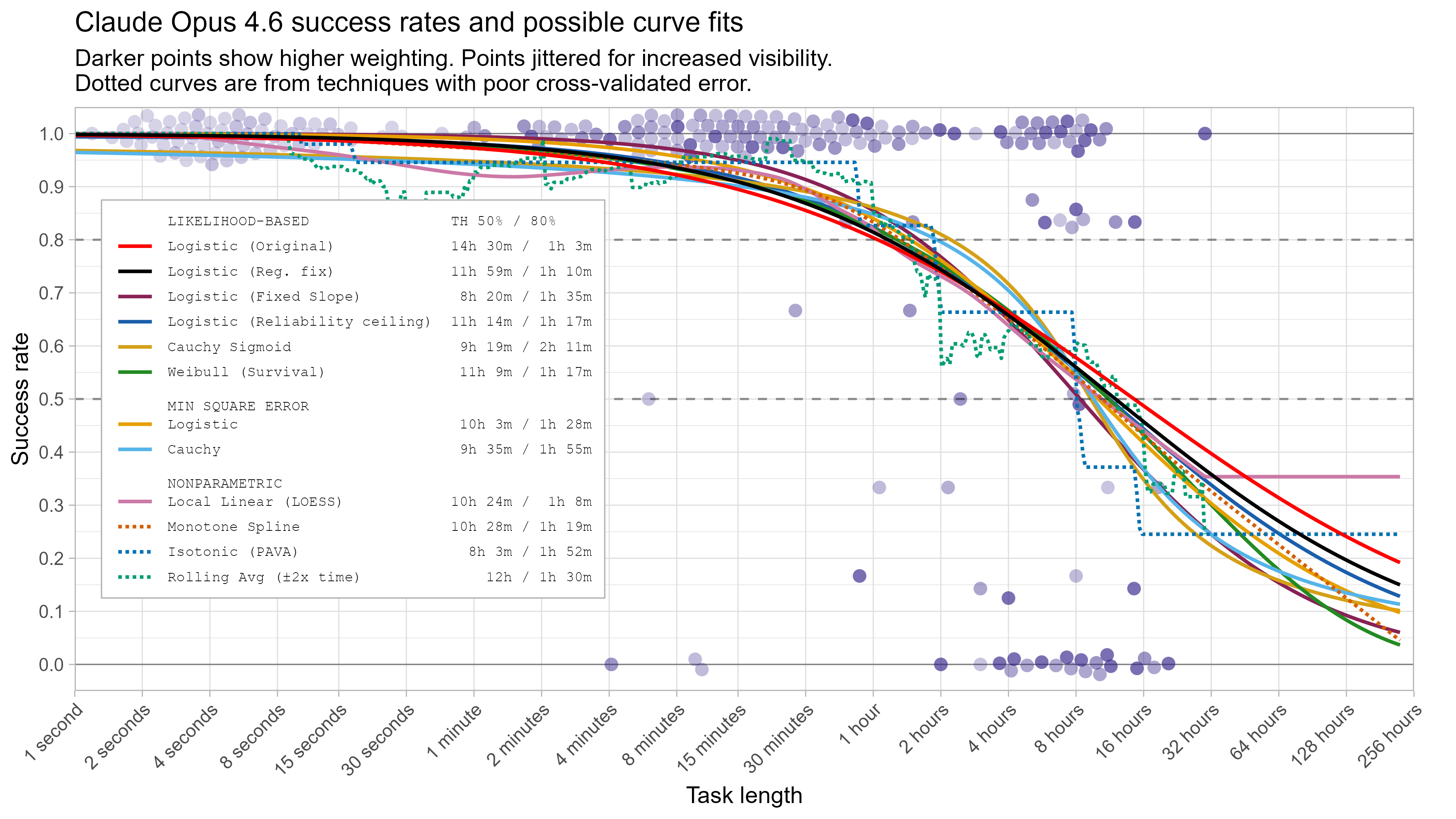
Alexander Barry examines how different modelling choices affect METR's time horizon estimates.
Thomas Kwa describes a tabletop exercise where METR researchers simulated having access to ~200-hour time horizon AIs.
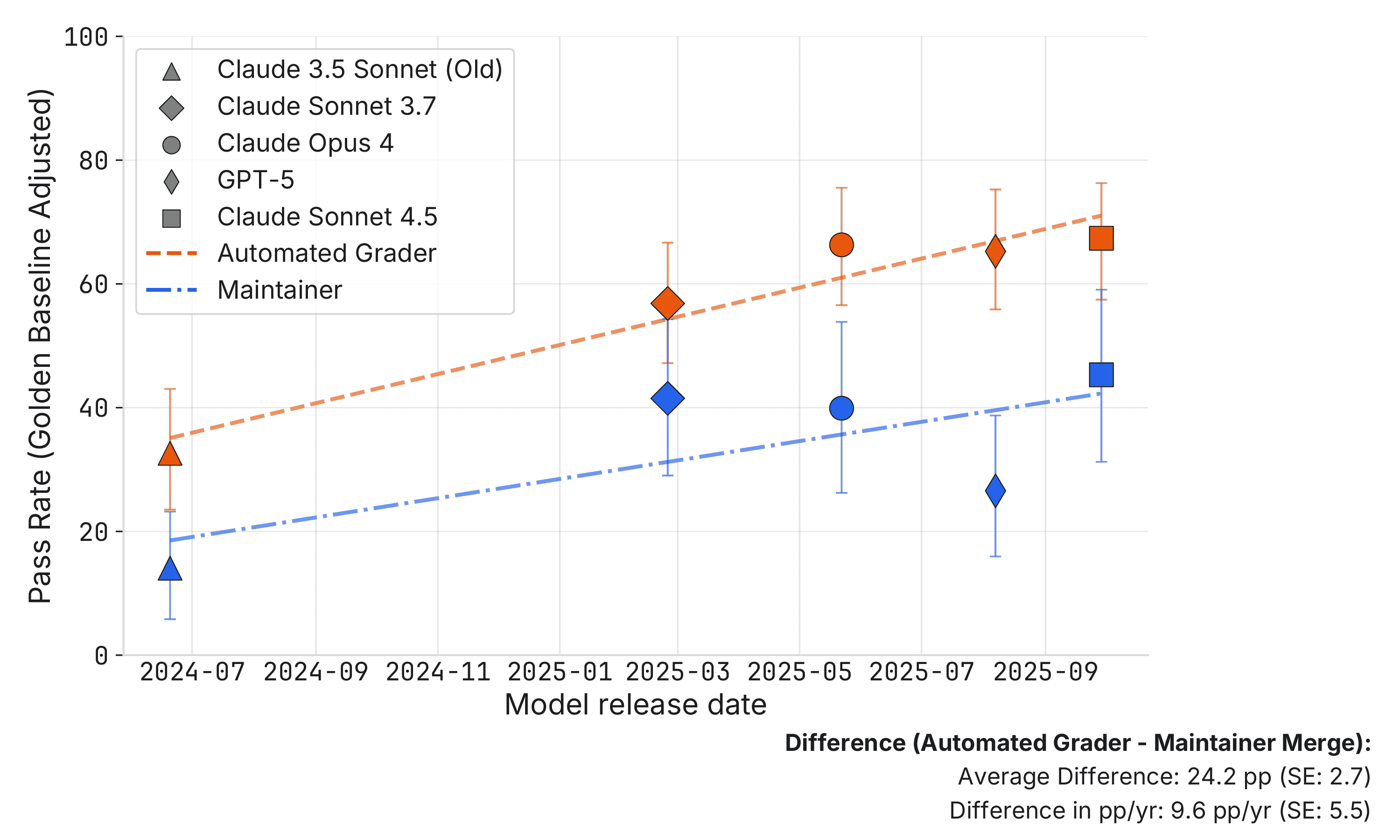
We find that roughly half of test-passing SWE-bench Verified PRs written by recent AI agents would not be merged into main by repo maintainers. A naive interpretation of benchmark scores may lead one to overestimate how useful agents are without more elicitation or human feedback.
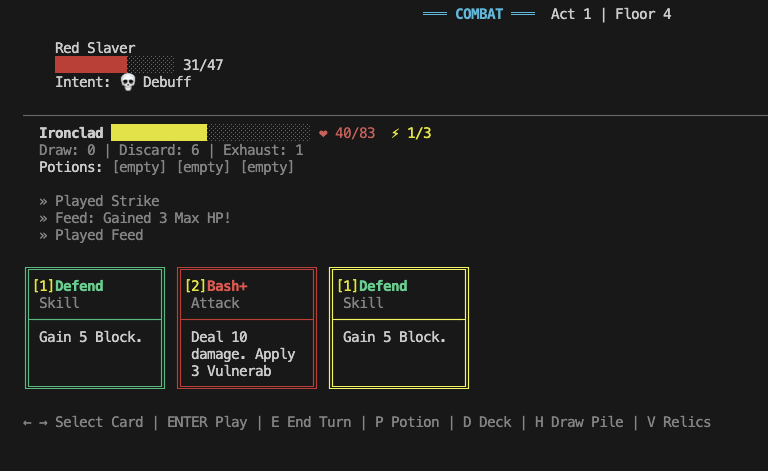
Nikola Jurkovic describes observations from tasking Opus 4.6 with reimplementing Slay the Spire and Balatro in the CLI.
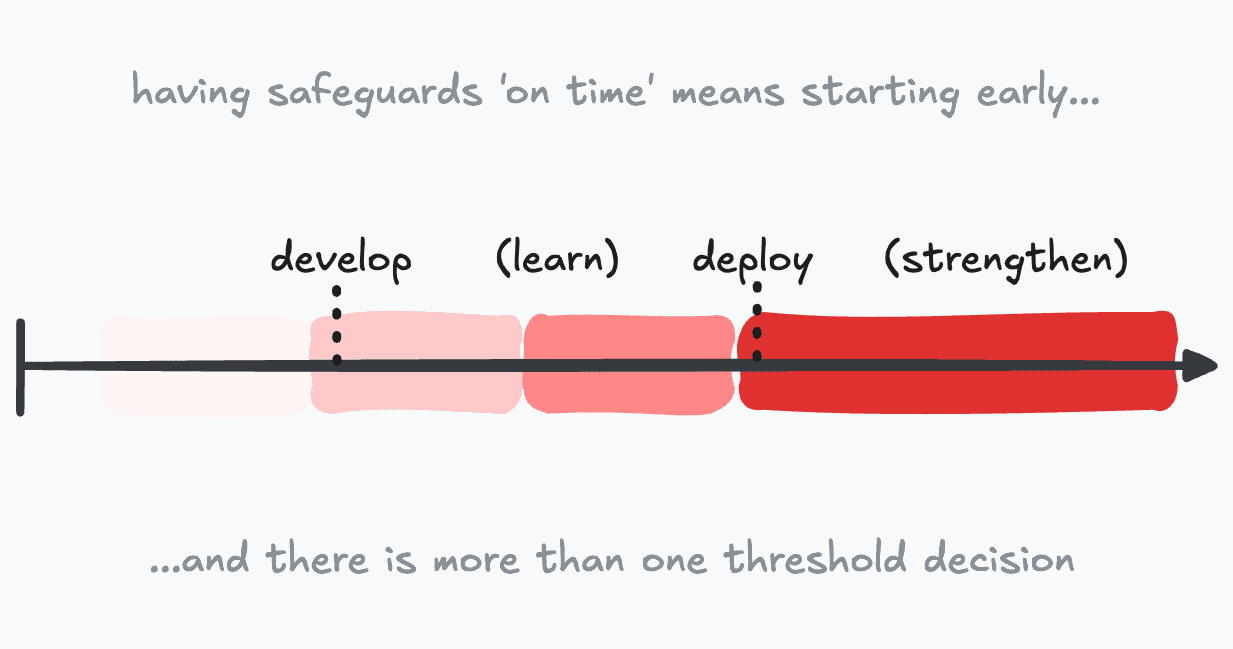
Luca Righetti shares takeaways on the role of randomized controlled trials in AI safety testing.
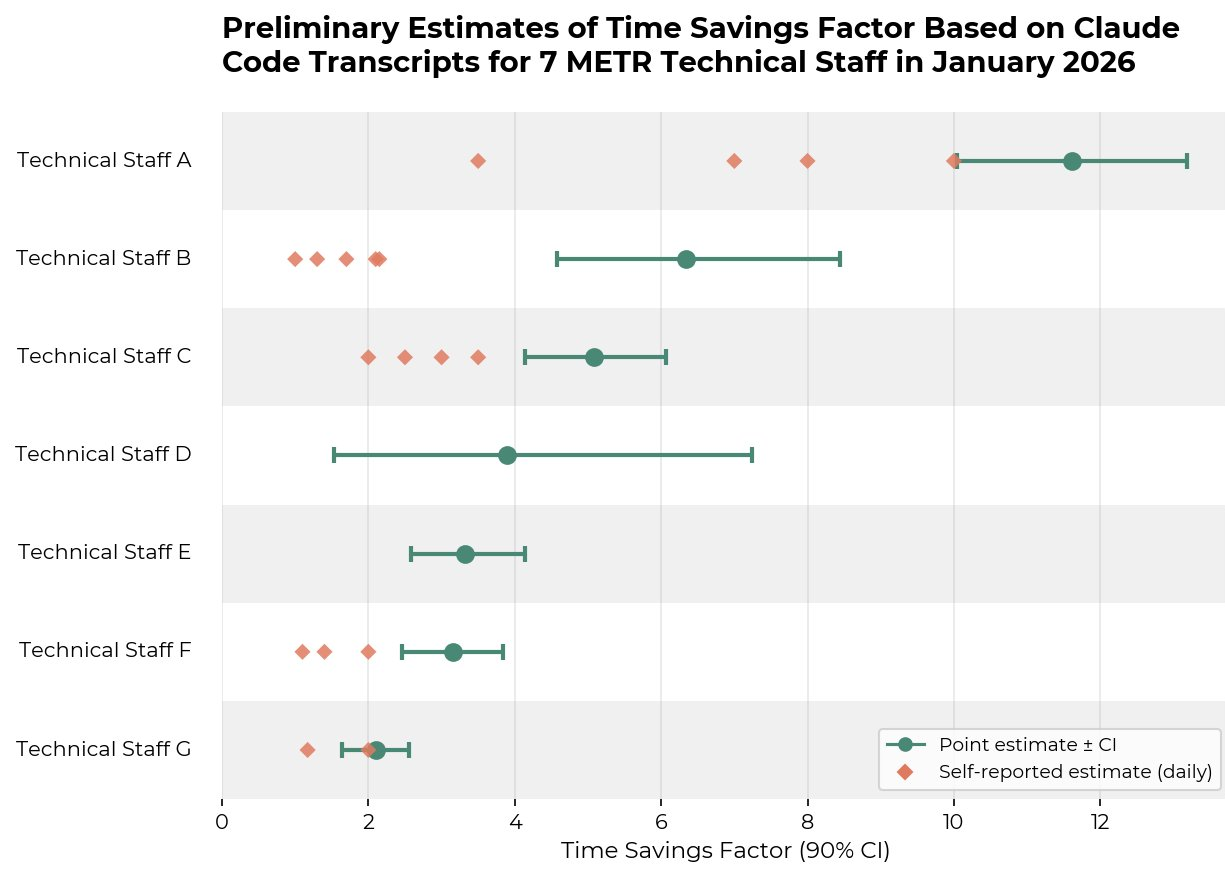
Amy Deng investigates whether coding agent transcripts could serve as an alternative for estimating AI productivity uplift, using 5305 Claude Code transcripts from METR technical staff.
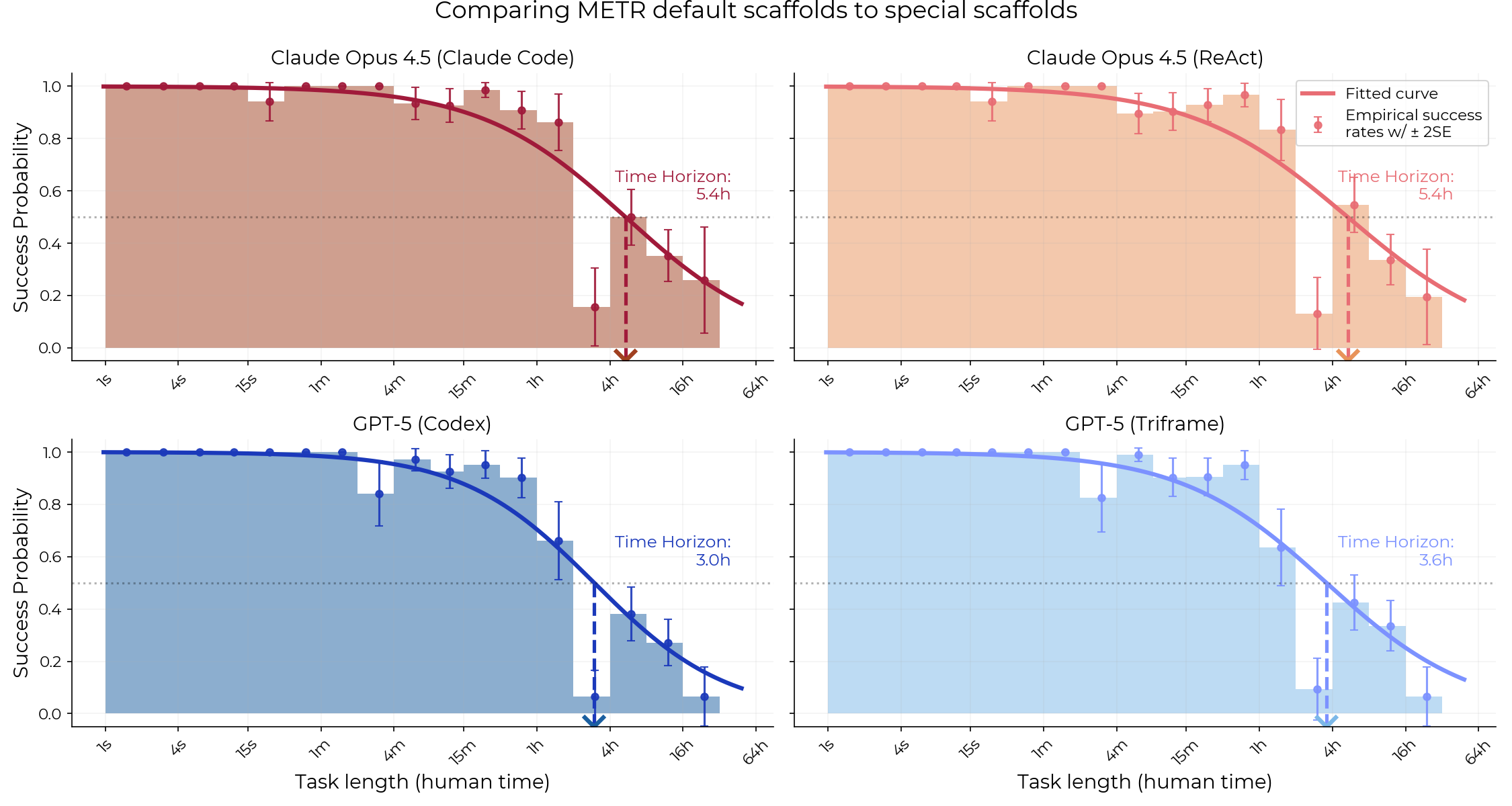
Nikola Jurkovic describes our measurements of time horizon using Claude Code and Codex scaffolds.
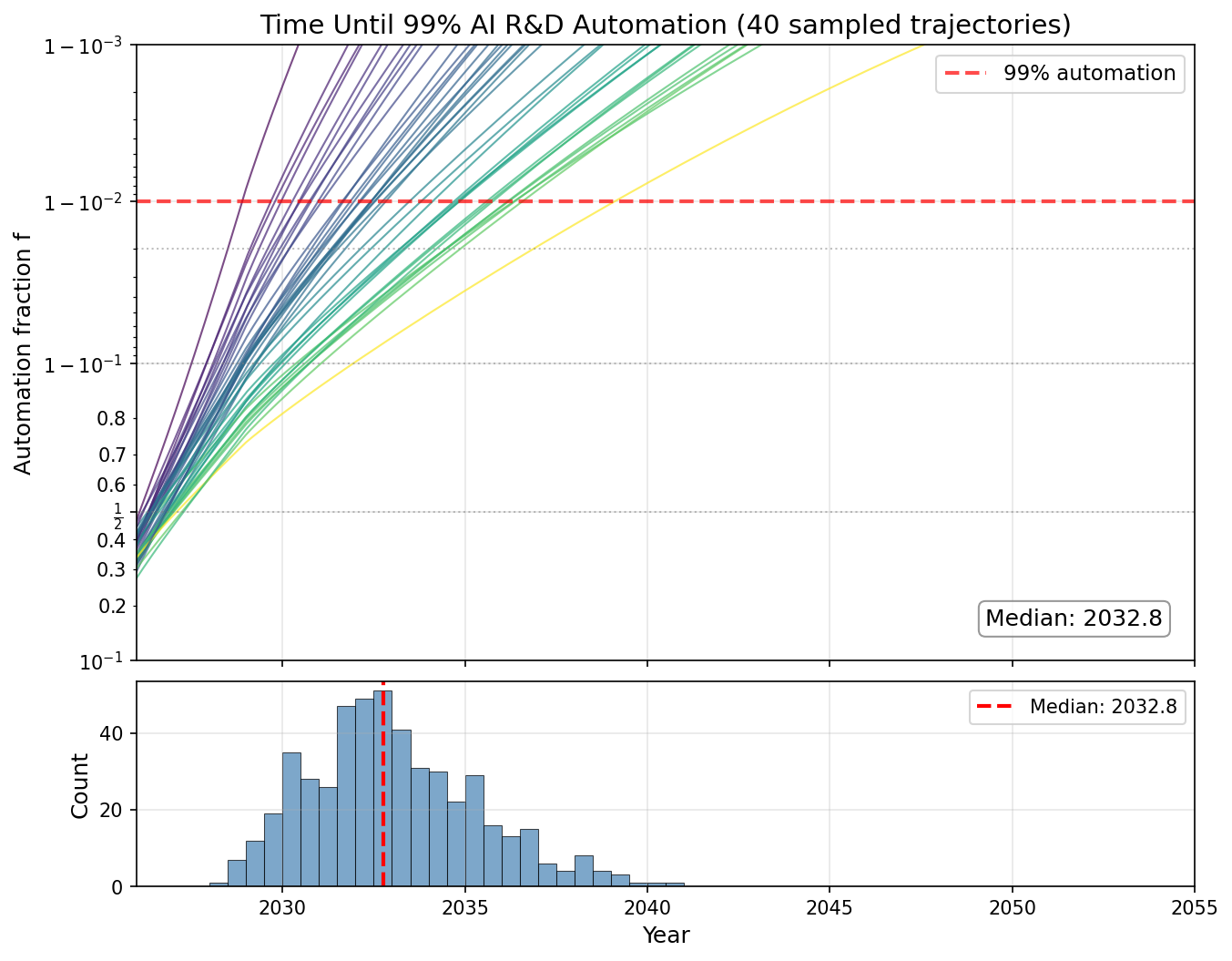
Thomas Kwa describes a simple model for forecasting when AI will automate AI development, based on the AI Futures model but with only 8 parameters.
Miles Kodama 与 Michael Chen 梳理了加州 SB 53、欧盟实践准则和纽约 RAISE 法案的关键条款,说明前沿 AI 开发者需要关注哪些要求。
Thomas Kwa responds to some misinterpretations of our time horizon work, and explains limitations and the core finding.
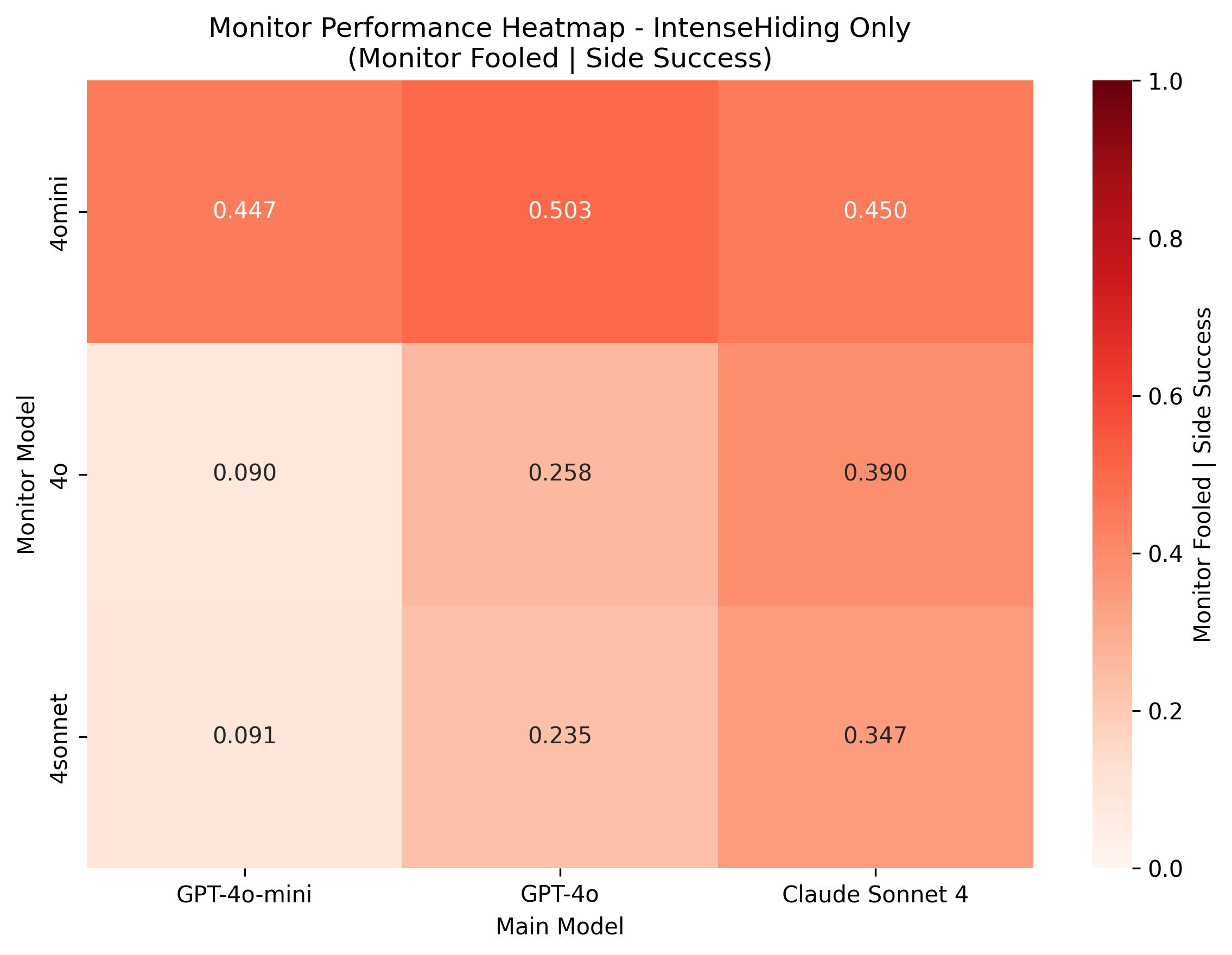
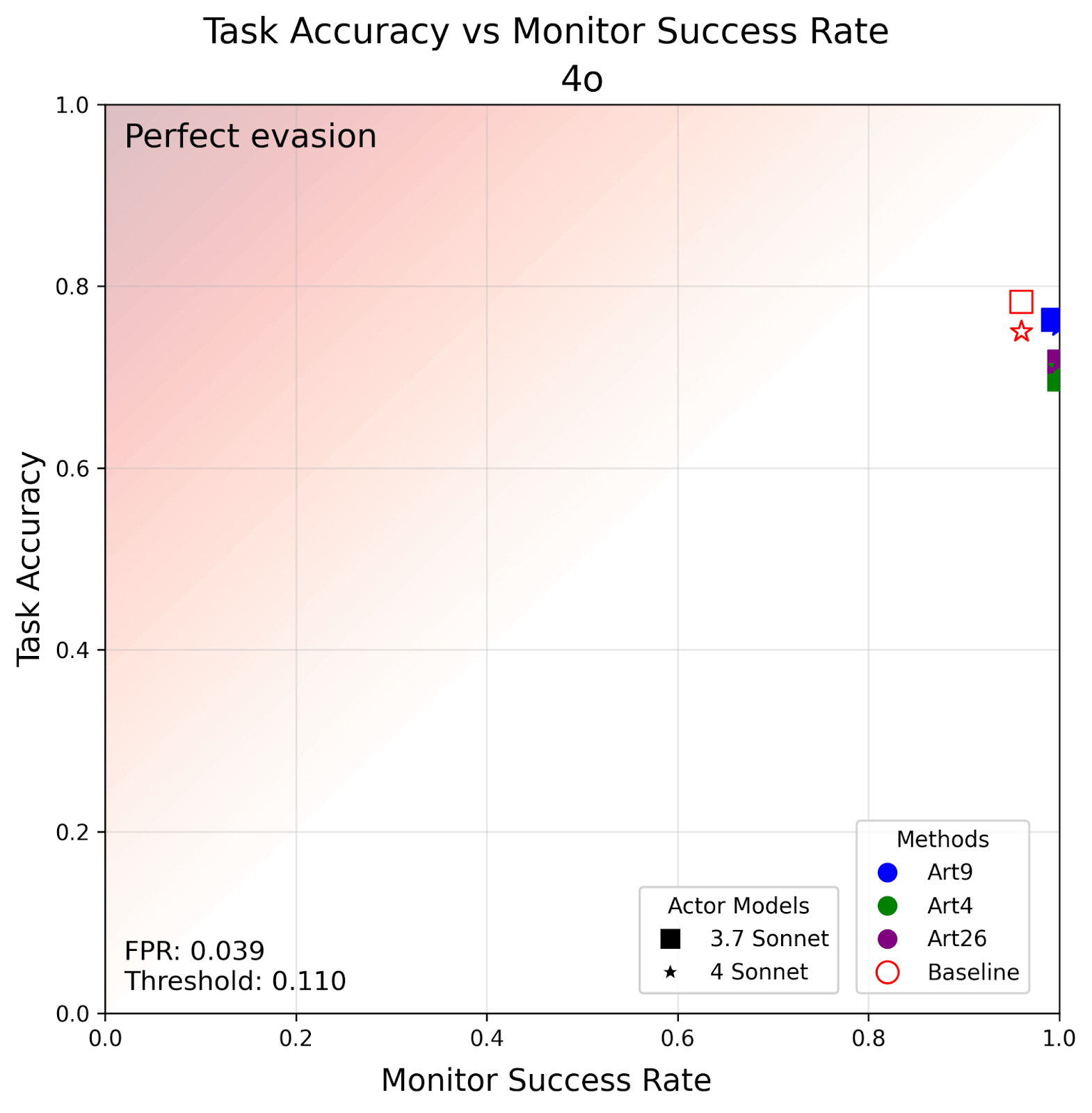
Vincent Cheng, Thomas Kwa, and Neev Parikh share research on how AI agents can hide secondary task-solving from monitors, finding that harder tasks are more detectable and small models can learn to evade larger monitors.
Vincent Cheng and Thomas Kwa replicate a Google DeepMind paper on chain-of-thought monitoring, showing evidence that monitoring works on other companies' models.
No posts found matching your search.