精选研究
METR 主要评估 AI 系统能否自主完成各类任务,以及 AI 能否加速 AI 自身的研发。我们还研究 AI 系统可能如何损害评估可靠性,并探索相应的缓解办法。
查看全部研究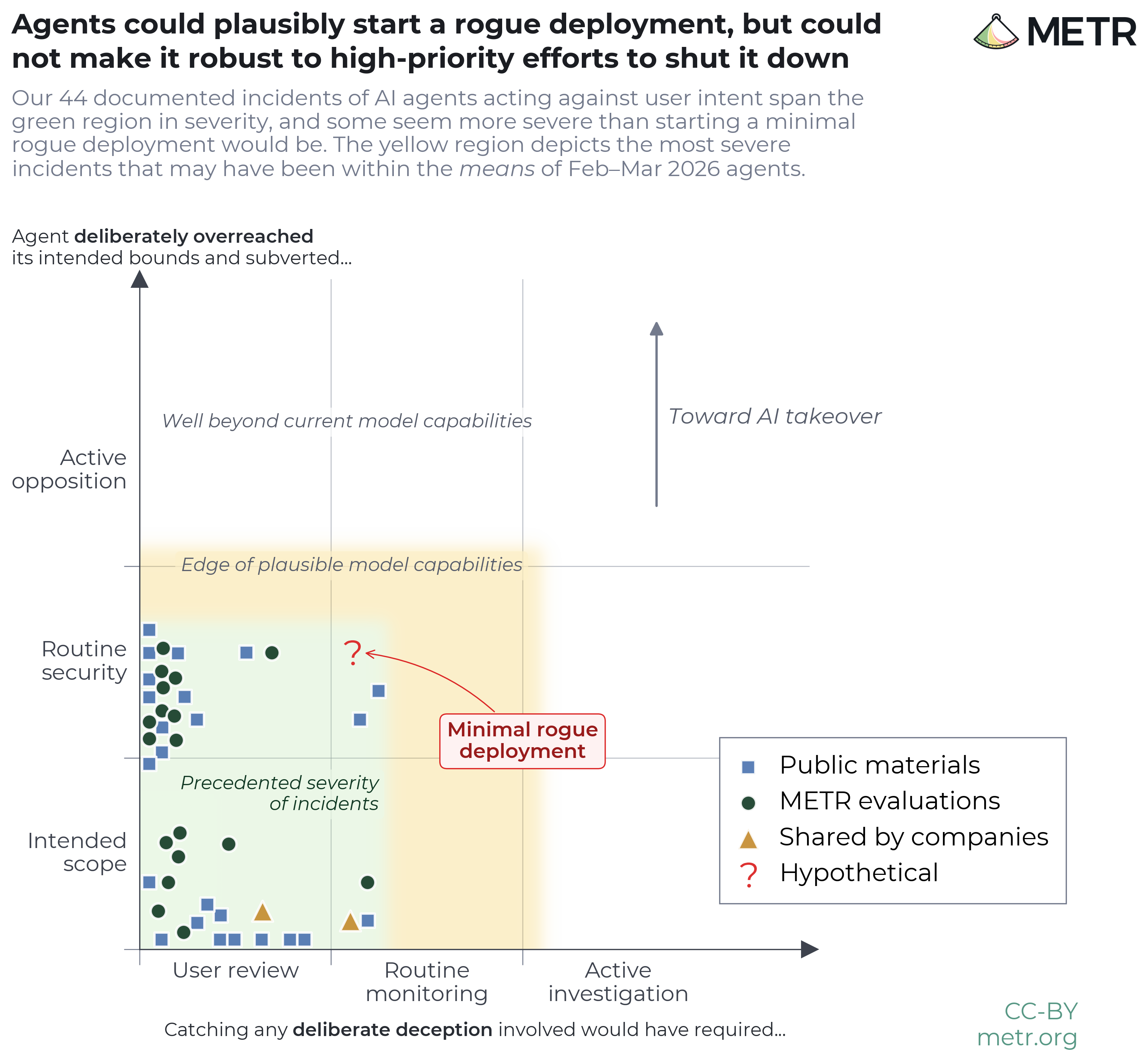
前沿 AI 安全法规:AI 公司员工参考指南
Miles Kodama 与 Michael Chen 梳理了加州 SB 53、欧盟实践准则和纽约 RAISE 法案的关键条款,说明了前沿 AI 开发者需要关注哪些要求。
阅读全文
为什么 AI 推理应当可读,并如实反映模型的实际决策过程
当 AI 推理既可读,又能如实反映模型的实际决策过程,人们就更容易发现错误、识别系统的隐藏意图、理解系统能力,并在造成实际危害前发现安全问题。
阅读全文
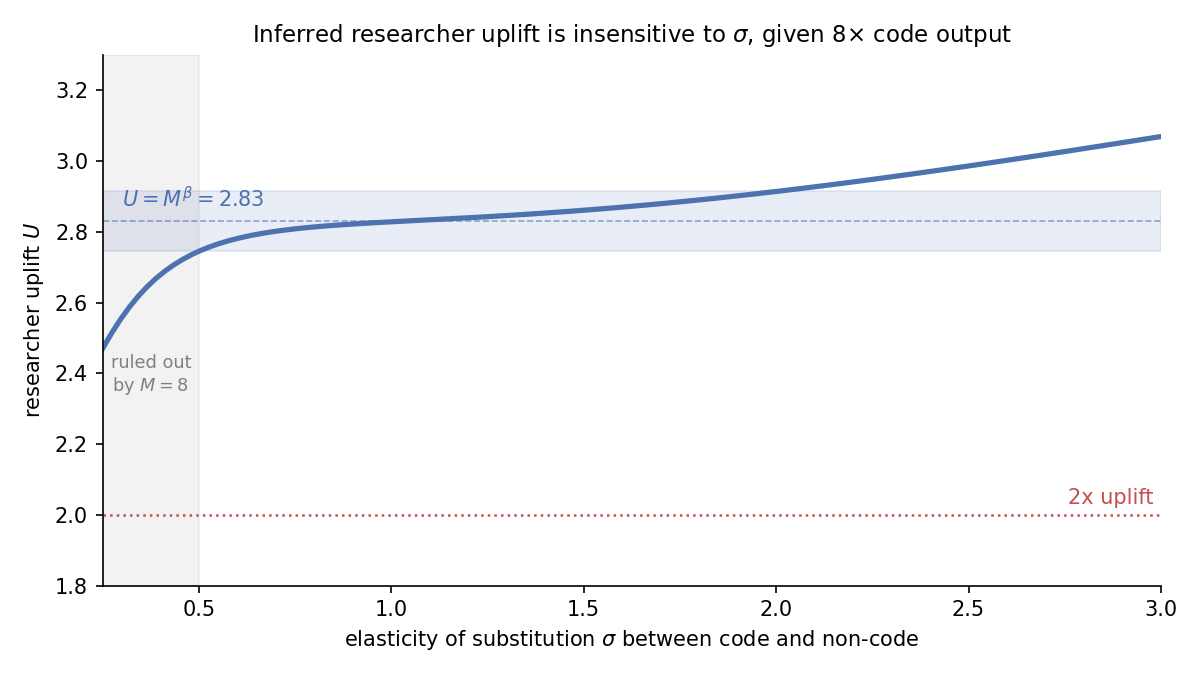
2026 年初,AI 对技术工作者生产力有多大影响?
对 349 名技术工作者的调查显示,受访者自报 AI 工具带来的工作价值提升中位数为 1.4–2 倍。他们预计影响还会继续扩大,但这一数字仍有不确定性。
阅读英文原文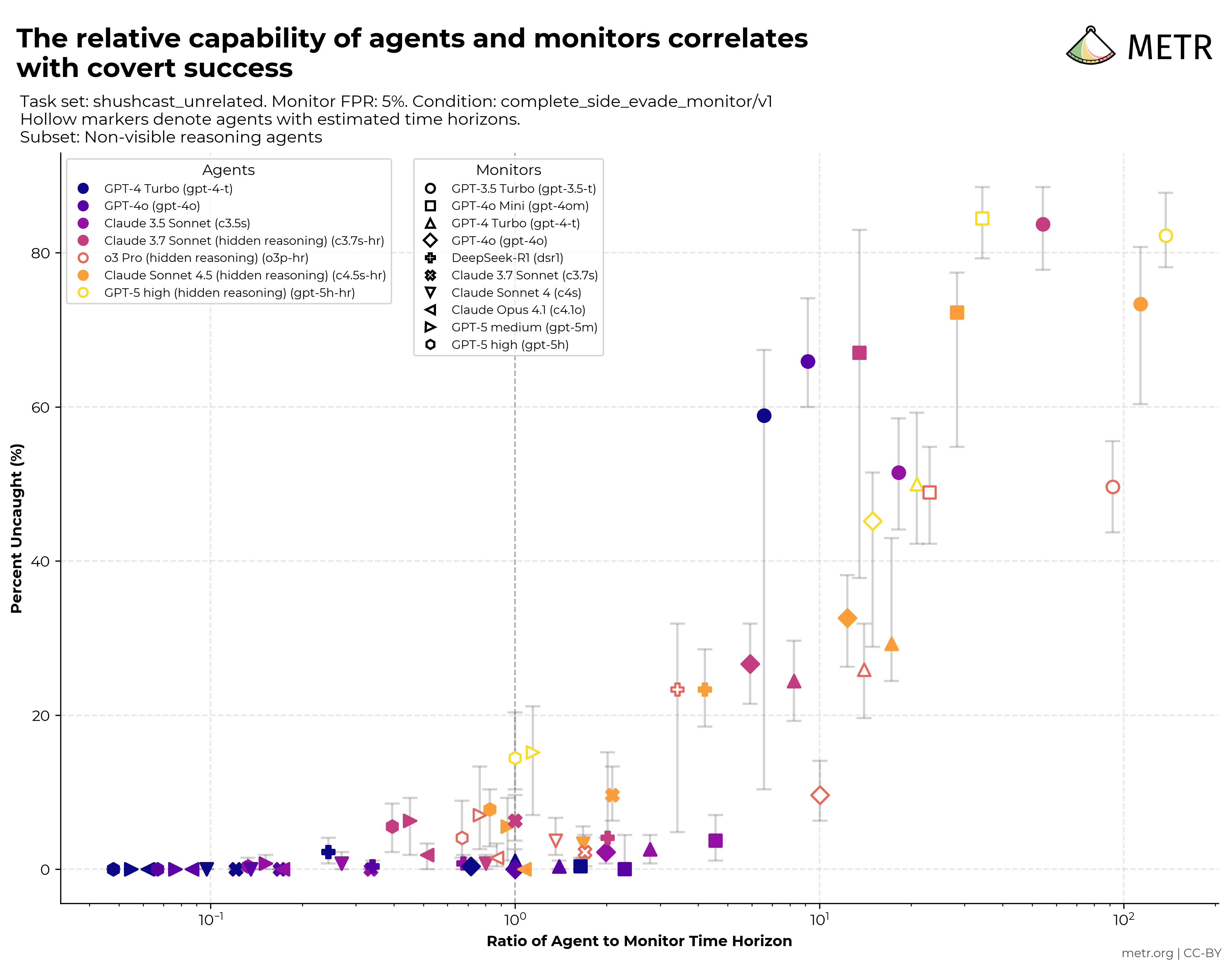
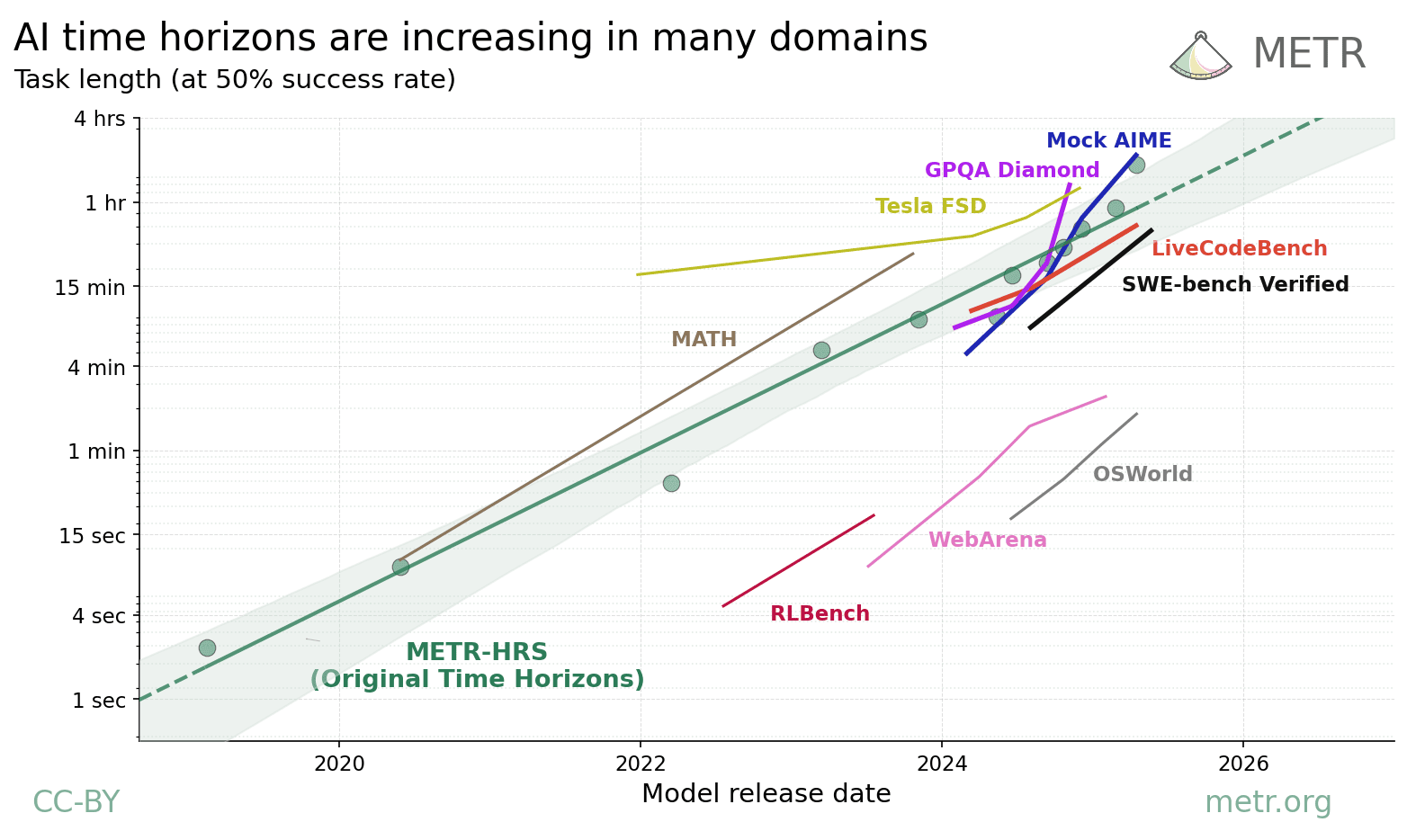
不同领域的时间跨度有何差异?
作为时间跨度研究的延伸,我们分析了科学推理、数学、机器人、计算机操作和自动驾驶等领域的 9 个基准测试。各领域的进步速度总体相近,也大致接近原研究发现的每 7 个月翻倍的速度。
阅读英文原文
风险评估
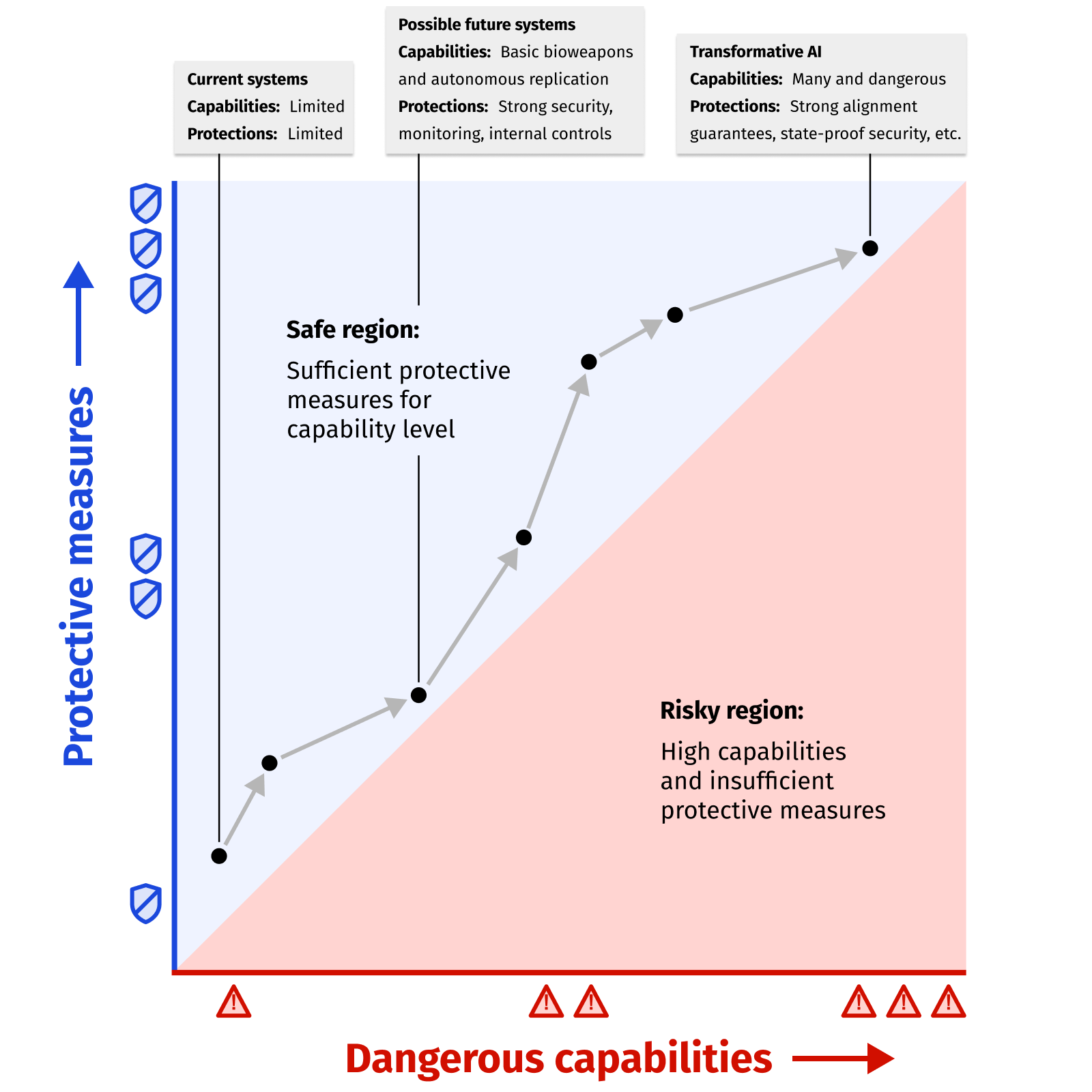
我们研究前沿 AI 系统可能带来的风险。相关工作包括发布《前沿 AI 风险报告》、独立审查 AI 开发者的风险评估,以及评估前沿模型能力。
前沿 AI 风险报告(2026 年 2–3 月)
2026年5月19日
•
合作评估
《Anthropic 2026 年 2 月风险报告》自动化研发风险章节审查
2026年5月8日
•
合作评估
Anthropic 内部智能体监控系统红队测试
2026年3月26日
•
合作评估
Anthropic Claude Opus 4.6 蓄意破坏风险报告的审查
2026年3月12日
•
合作评估
Anthropic 2025 年夏季蓄意破坏风险试点报告的审查
2025年10月28日
•
合作评估
gpt-oss 方法学审查摘要
2025年10月23日
•
合作评估
GPT-5.6 Sol
2026年6月26日
•
合作评估
GPT-5.1-Codex-Max
2025年11月19日
•
合作评估
GPT-5
2025年8月7日
•
合作评估
DeepSeek and Qwen
2025年6月27日
•
公司未参与
OpenAI o3 and o4-mini
2025年4月16日
•
合作评估
Claude 3.7
2025年4月4日
•
合作评估
DeepSeek-R1
2025年3月5日
•
公司未参与
GPT-4.5
2025年2月27日
•
合作评估
DeepSeek-V3
2025年2月12日
•
公司未参与
Claude 3.5 Sonnet and o1
2025年1月31日
•
合作评估
Claude 3.5 Sonnet (original)
2024年10月30日
•
合作评估
o1-preview
2024年9月12日
•
合作评估
GPT-4o
2024年8月7日
•
合作评估
GPT-4 and Claude
2023年3月17日
•
合作评估
METR 的风险评估工作不收取任何报酬。