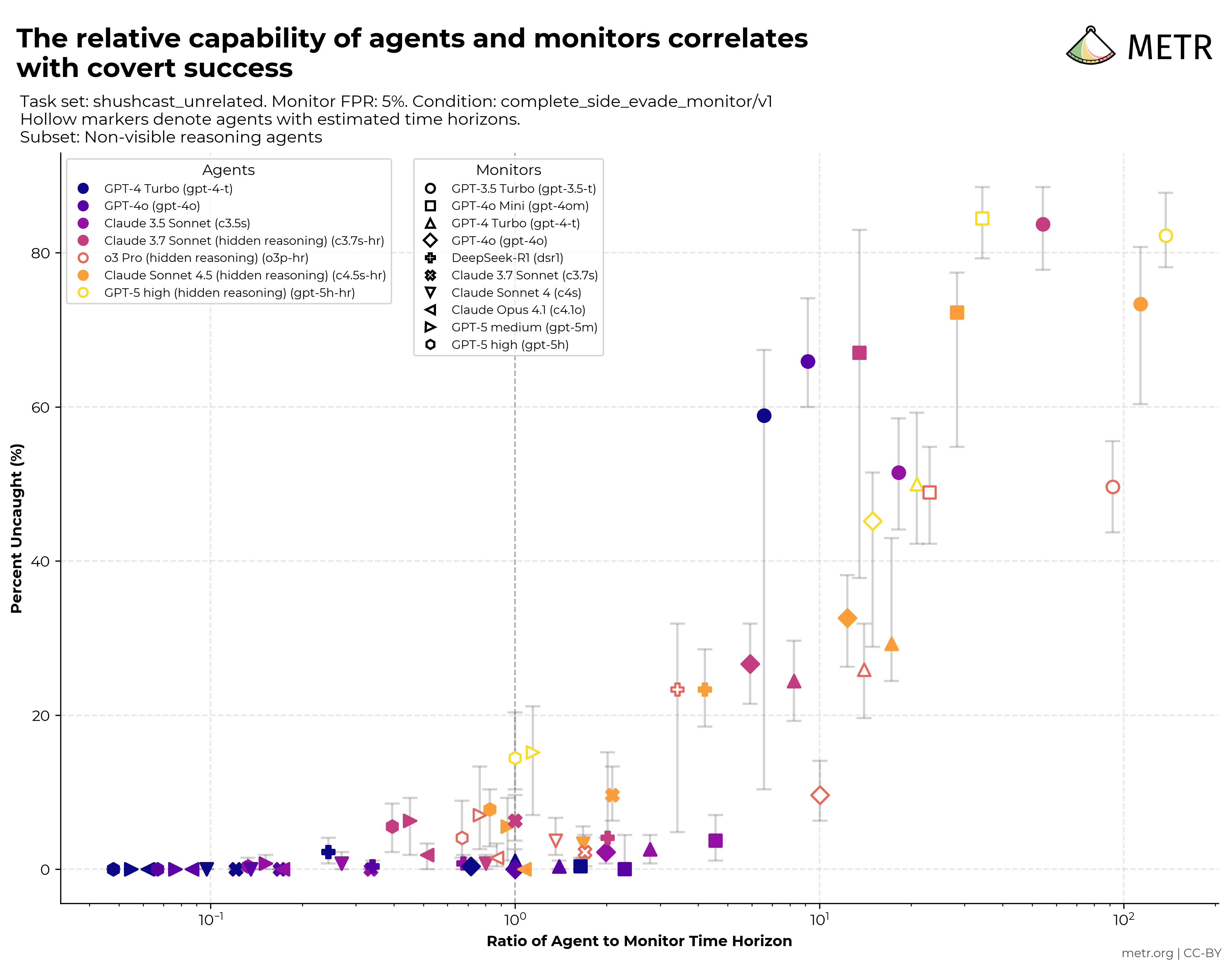
I. Introduction
We want to measure and understand how much AI agents can accelerate AI R&D and how this is changing over time. There are various sources of evidence we can look to here, including anecdotes about autonomous contributions (AlphaEvolve and TTT-Discover speeding up a GPU kernels, autoresearch yielding speedups in nanochat), progress on benchmarks, and uplift measurement (see our recent post for a longer discussion).
One interesting source of evidence is cumulative progress on publicly tracked challenges like the NanoGPT speedrun, where we can compare agent contributions to human progress over time. Such challenges and leaderboards of cumulative progress on a task are especially useful when:
- The task maps to real AI R&D (e.g., pretraining a language model)
- Many contributors have built up a rich history of progress, giving a rough sense of how much human effort went into it (a cost curve)
- Agents can compete under comparable conditions and potentially make new contributions
Let’s look at one such leaderboard: the nanogpt speedrun. The goal is to train a language model to a target validation loss on FineWeb using 8×H100 GPUs as fast as possible. It’s a small-scale version of LLM pretraining with a public history of contributions, with four recent ones credited to AI agents as of April 2026. The optimization activities map to pretraining research such as architecture changes, writing kernels, and improving optimizers. Contributions, such as the Muon optimizer, have made it to frontier-scale models like GLM-4.5 and Kimi K2.
However, there are some challenges to interpreting this evidence:
- Contamination. Ideas relevant to the task may already be in models’ training data, either directly from public codebases, or indirectly from published ML literature, making agent contributions hard to interpret.1
- Survivorship bias. We only (directly) see ideas that worked. Humans and agents may have tried ideas that failed, and those don’t show up in the record.
- Scale-dependence. Training GPT-2 on 8×H100s is not frontier pretraining. Training 124M parameters likely looks very different from what matters at 100B+ scale with different architectures (e.g., MoE).2
- Composability. Pretraining is one piece of the AI R&D stack. How acceleration on it composes with other parts is an open question, though tasks like posttrainbench could help cover other pieces.
II. Classifying NanoGPT speedrun contributions
The speedrun has two tracks: a small track (target loss 3.28, starting from GPT-2-small 124M params) and a medium track (target loss 2.92, starting from GPT-2-med 350M params). This post focuses on the small track.
From May 2024 to March 2026, 36 contributors have submitted 77 records — each one a new version of the training code that beats the previous best time — cutting the training time from 45 minutes to 1.43 minutes, a 31x speedup.3 Every record has a PR/commit with diffs, descriptions, and often cited papers or tweets describing the idea.
With the help of Claude Code, I went through each merged PR and classified them along the following dimensions. The full dataset is here.
| Dimension | Level | Description | Examples |
|---|---|---|---|
| Optimization depth: how non-obvious is the idea? | Breakthrough | New research contribution adopted widely. | Muon optimizer (#3), later used in Kimi K2 and GLM-4.5. |
| Deep | Novel idea or non-obvious cross-domain application. | Bigram Hash Embedding, hashing token pairs into per-layer residual additions (#62). | |
| Moderate | Non-trivial adaptation requiring domain expertise. | Batch-size schedule as a 3-phase linear ramp (#46); YaRN made dynamic during training (#31). | |
| Shallow | Trivially using a library, tuning hyperparameters, etc. | Upgrading PyTorch to 2.5.0 (#7); lowering logit softcap from 30 to 15 (#18). | |
| Provenance: where did the idea come from? | Invented | The core idea originated in the speedrun. | Muon optimizer (#3); Paired Head Attention (#58). |
| Adapted | Building on existing work with significant modification. | U-net skip-connection pattern applied to transformers (#11). | |
| Imported | Directly applying a technique from a paper or library. | Flash Attention 3 library (#29). |
Here’s a graph I created showing the full timeline of records. AI-contributed records are those where the official record history attributes the submission to an AI agent rather than a human contributor.
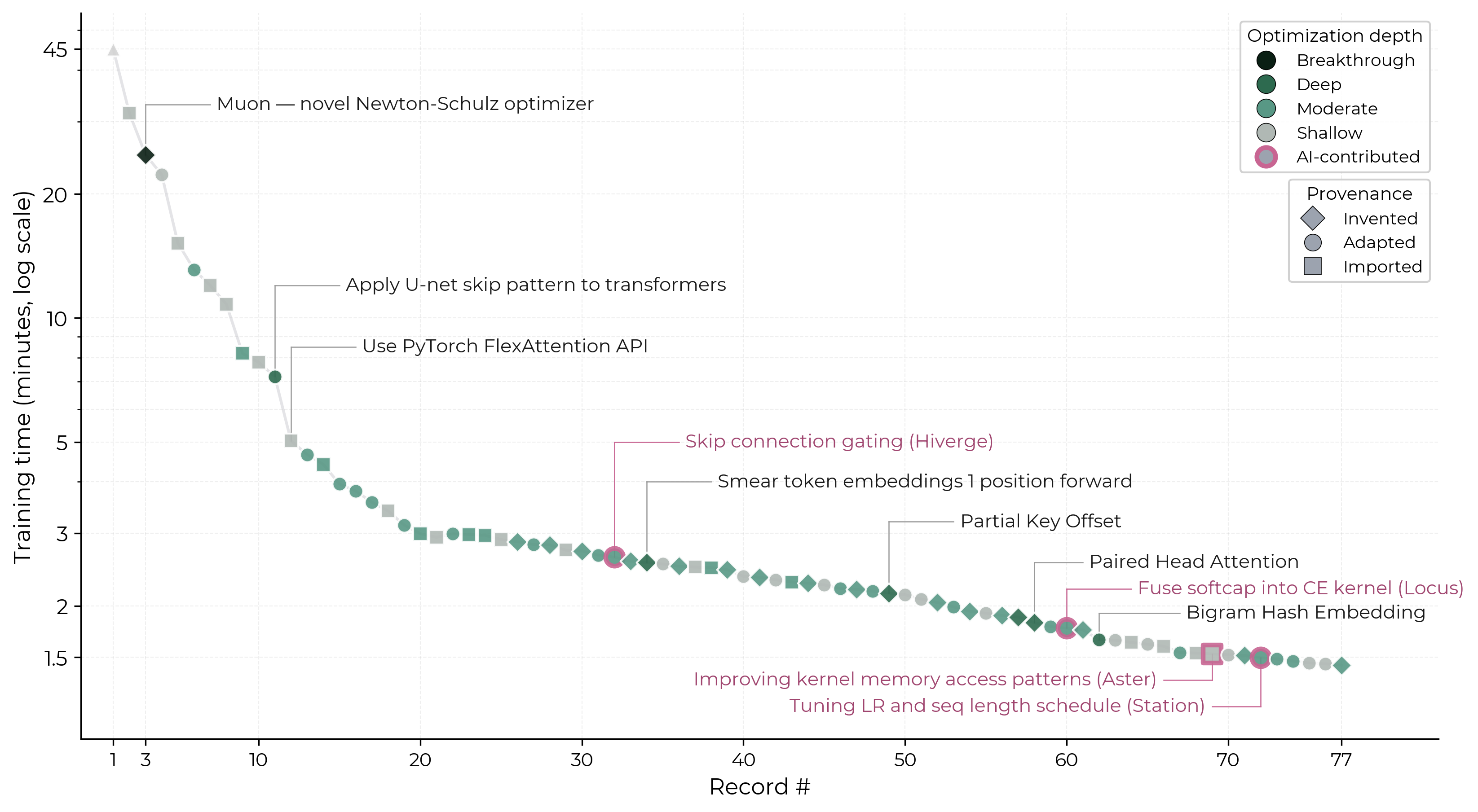
Here are some observations I made from this data:
Humans have made lots of progress, including deep ideas and breakthroughs.
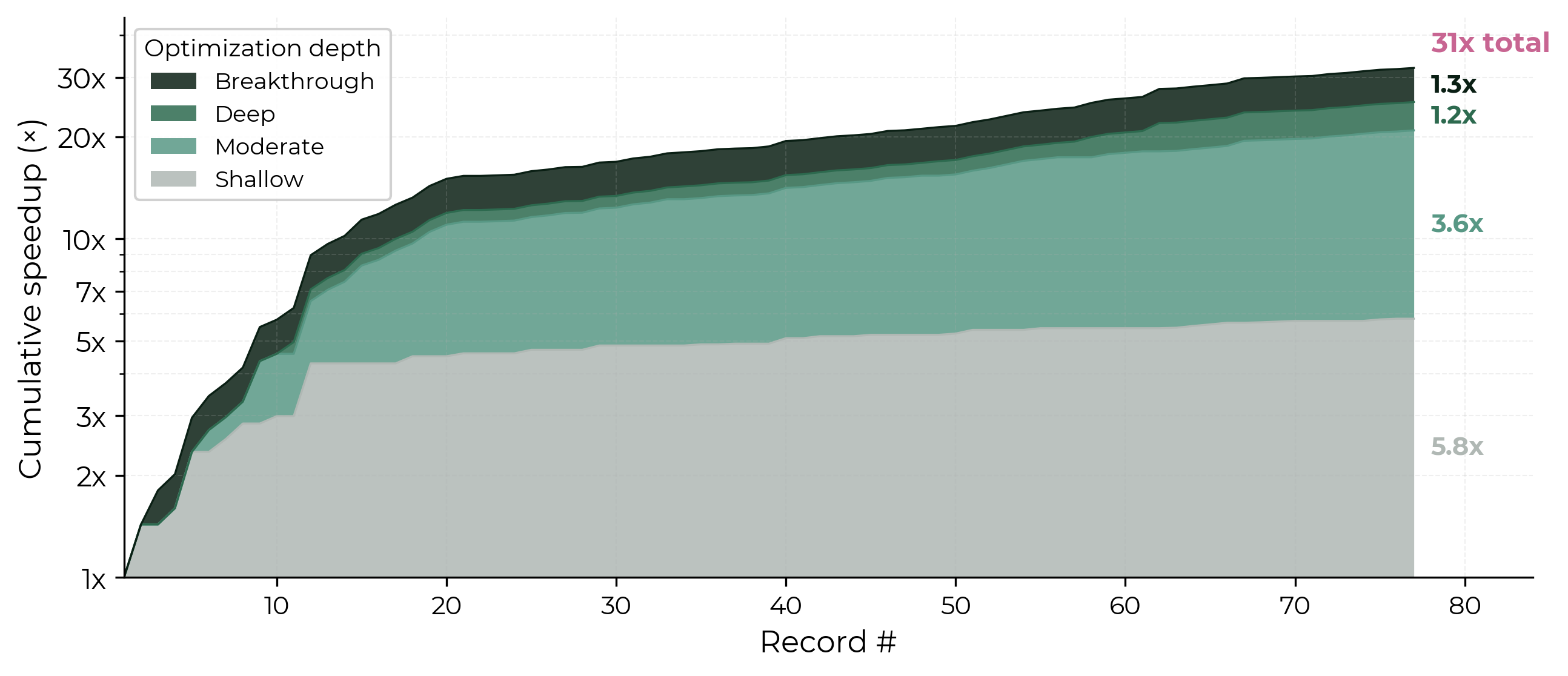
- Relatively shallow contributions have had a big impact. Shallow and moderate contributions together drove roughly 21x of the 31x. For example, record 12 adopted the newly released FlexAttention, a PyTorch API for efficiently implementing attention patterns, and got a 30% speedup. The library itself is sophisticated, but the contribution was essentially migrating to it.
- Deeper ideas appeared throughout, not just early on. Record 3 introduced the Muon optimizer, original research on Newton-Schulz orthogonalization, later adopted widely including by Kimi K2 and GLM-4.5. Late in the speedrun, record 58 invented Paired Head Attention, a novel attention mechanism with no clear precedent, and record 62 invented Bigram Hash Embedding, uniquely combining a 2017 hash embeddings idea with ideas from DeepSeek’s Engram.
Early progress was largely about catching up to the frontier research; later records increasingly invented new ideas.
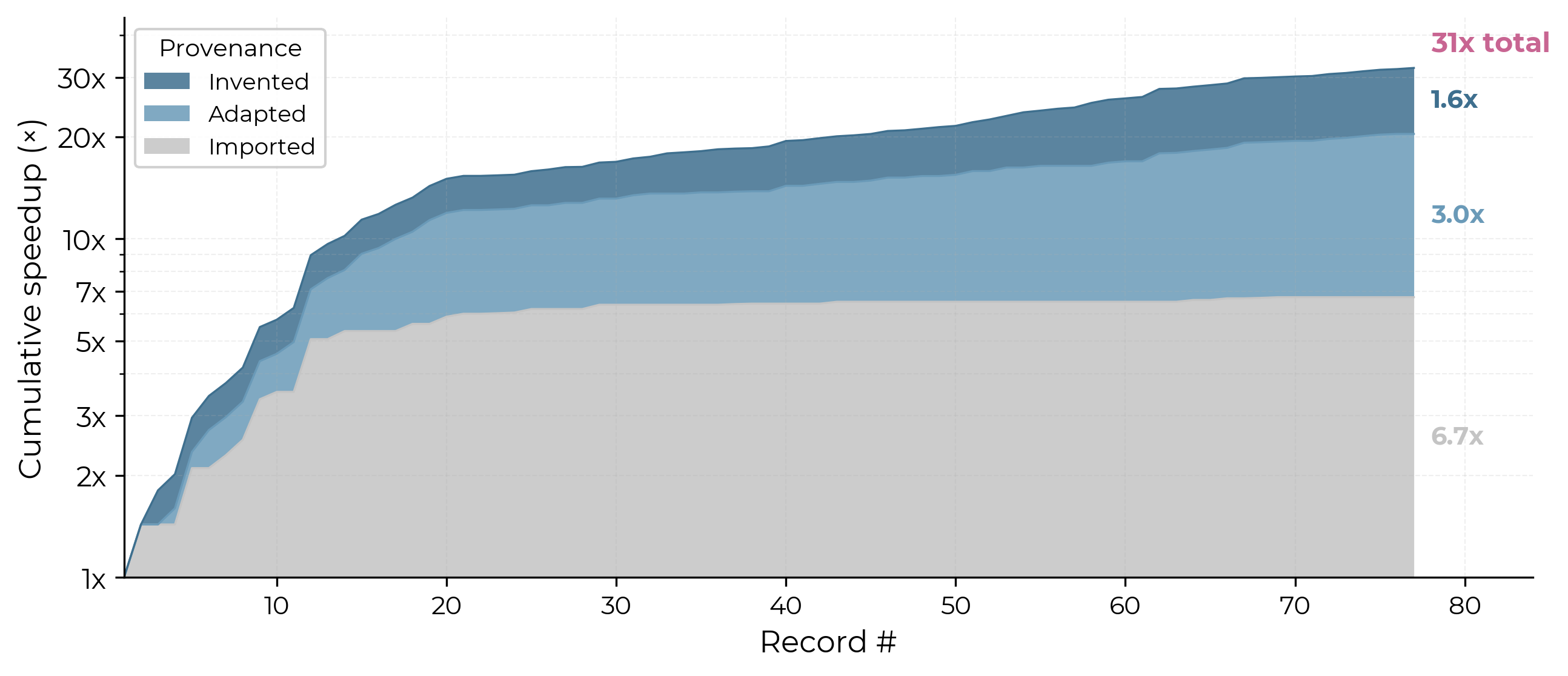
- Early records (first 20 records, May 2024 – Jan 2025) were mostly imported or adapted to catch up to frontier research, applying techniques like RoPE, ReLU², QK-norm, and FlexAttention.
- Later records (Jan 2025 – Mar 2026) increasingly invented new ideas: 33% were invented, compared to just one (Muon) in the first 20.
- Also, in terms of cumulative speedup: imported ideas drove 6.7x of the 31x total, adapted ideas 3.0x, and invented ideas 1.6x.
Records targeted many layers of the AI stack, and focus has shifted over time.
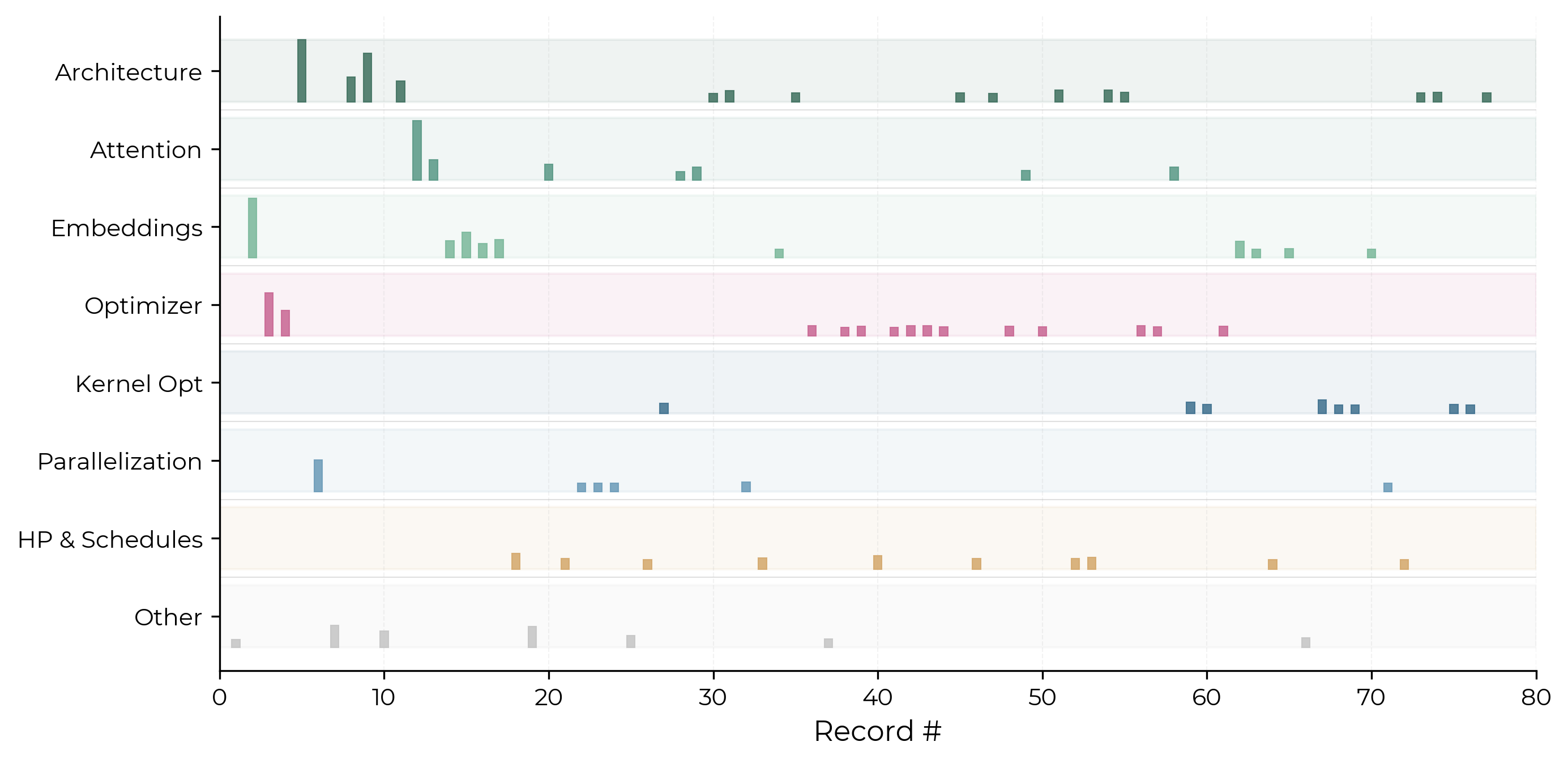
Above, each row shows a different layer of the model stack, with bar height indicating the relative speedup of each record. Despite NanoGPT being a single chunk of AI R&D (pretraining), records span many layers.
Early records were dominated by model architecture changes. The middle phases shifted toward attention mechanisms and parallelization. In later records, optimizer and kernel-level improvements have picked up.
AI agents have recently contributed, but their current contributions appear relatively shallow.
Between late 2025 and early 2026, four records in the official record history credit an AI agent alongside a human co-contributor. All four are bespoke AI agent systems built by specific teams for ML research and optimization, not general-purpose coding assistants like Claude Code:
- Hiverge from Hiverge AI optimized distributed training and skip connection gating. (#32)
- Locus from Intology fused a softcapped cross-entropy kernel. (#60)
- Aster from Aster Lab improved kernel memory access patterns. (#69)
- Station from Dualverse AI increased the LR floor and added a short-sequence curriculum. (#72)
All four are real improvements, but based on my analysis none reached the deep or breakthrough end of the scale. However, this isn’t strong evidence that agents produce fewer deep ideas than humans. With four records with no disclosure of inference compute spends, these appear similar to more recent human contributions.
A notable contribution was by Station, which discovered that a config parameter (window_size) had been silently ignored by compiled code, a bug humans had missed for months.
Because each record is co-credited to a human, we also don’t know how human-directed these agent runs were or how many failed attempts preceded the successfully recorded ones. Nor do we know how much compute these agent runs consumed. So these contributions are hard to interpret on their own.
III. What are challenges like this useful for?
Publicly tracked challenges with a lot of accumulated human effort give us a few useful things:
-
Qualitative observations about human vs agent contributions. We can compare the kinds of ideas humans and agents produce and their substitutability; e.g., whether agents produce shallower optimizations than humans (a hypothesis motivated by the apple-picking model). In NanoGPT, the four AI-contributed records, as of April 2026, are all shallow-to-moderate and imported or adapted. But this isn’t particularly different from randomly sampled recent human contributions, so the four data points can’t yet distinguish agent shallowness from a low base rate.
-
A source of high-effort human baselines. Maintaining realistic, difficulty-calibrated benchmarks (e.g. METR’s time-horizon) requires tasks where we know how impressive a given score is. These challenges give us this: performance has been pushed for months or years, with a rough sense of how much human effort each step took. To use this, you’d start agents from a chosen point in the history and compare their progress to the human effort made from the same starting point.
-
A task to run agents on, including at high compute budgets. We can create tasks from these challenges and run agents at much larger compute budgets than anyone has publicly tried. There isn’t public evidence of agents being run at scale on this kind of task, so the shape of the cost curve at high budgets is essentially unknown. Further, public agent-contributions are also useful to cross-check our internal elicitation — if our agents fall short, that could point to scaffolding, prompting, or tooling gaps.
The full dataset for this post is here.
-
The direct form of contamination can be mitigated by starting an agent from the latest record; the indirect form is harder to rule out. ↩
-
“Scale-dependence” here means small-scale results may not transfer to frontier. Gundlach et al. (2025) find that the biggest efficiency gains come from innovations whose benefits grow with scale (like Transformers or Chinchilla). So a speedrun-originated innovation that is scale-complementary (like Muon) could transfer, while small-scale-only tricks likely won’t. ↩
-
This 31x is the speedup within the speedrun itself (May 2024 – March 2026). For estimates of the full efficiency gap since the original 2019 GPT-2 training, see Parker Whitfill’s analysis and Hans Gundlach’s analysis. Both arrive at similar annual rates for FLOP efficiency (~1.6-1.7x/year). Their overall estimates differ: Parker estimates 707x total wall-clock speedup on fixed hardware (including throughput gains like bf16 and FlashAttention), while Gundlach estimates ~75x in cost reduction. ↩