Summary
In February–April 2026, we ran a survey of 349 technical workers (including 87 software engineers, 71 researchers, 129 academics and PhD students, and 48 founders and managers) about their usage of AI tools. Compared to previous work, our survey is one of the more detailed surveys of technical workers’ self-reported gains from frontier AI tools.1
We attempt to capture gains due to AI in terms of ‘value’ (how much more value are you creating with AI), rather than ‘speed’ (how long would it have taken you to do these tasks without AI). These can give different answers in principle, in particular if using AI changes the distribution of tasks you work on. For example, researchers could use AI to quickly build an interactive dashboard for their data, which would have taken significantly longer without AI but isn’t that important for their project. We provide more detail on the distinction between value and speed gains in our previous research.
We think that the distinction between ‘value’ and ‘speed’ gains is important because value is closer to the idea that survey designers typically care about, whereas our sense is that it is common for respondents to think in terms of speed, and we expect that speed changes would typically overstate value changes. See methodological details here.

- Participants self-reported a median 1.4–2x change in the value in their work due to AI tools. The median self-reported speed change (which we expect to be higher than value change) is 3x.
- Using the same question wording, respondents retrospectively estimate 1.3x value of work in March 2025, estimate 2x in March 2026, and forecast 2.5x for March 2027.
- Responses are broadly internally consistent – correlations between different value change measures are moderate, only 3% of respondents showed anomalies in their answers that we feel is sufficient to remove them.
- There are tentative reasons to be skeptical of the magnitude of responses.
- METR staff give the lowest change in value answers of any subgroup we study. We expect that this might be due to METR staff having in mind past findings of gaps between perceived and actual AI-driven productivity.
- Early qualitative investigation of public outputs plausibly suggests that especially high change in value estimates are overstated.
See detailed results here.
Importantly, survey results are not necessarily grounded in reality. There are reasons to be skeptical of people’s responses to counterfactual questions such as about AI’s effect on productivity — for instance, our study in early 2025 found that people overestimated AI’s effect on their time spent on tasks by 40 percentage points on average.
More broadly, public estimates of productivity impacts from surveys have tended to be greater than those from field experiments or quasi-experiments. However, it is difficult to determine the extent to which surveys overestimate productivity gains relative to experimental data.2
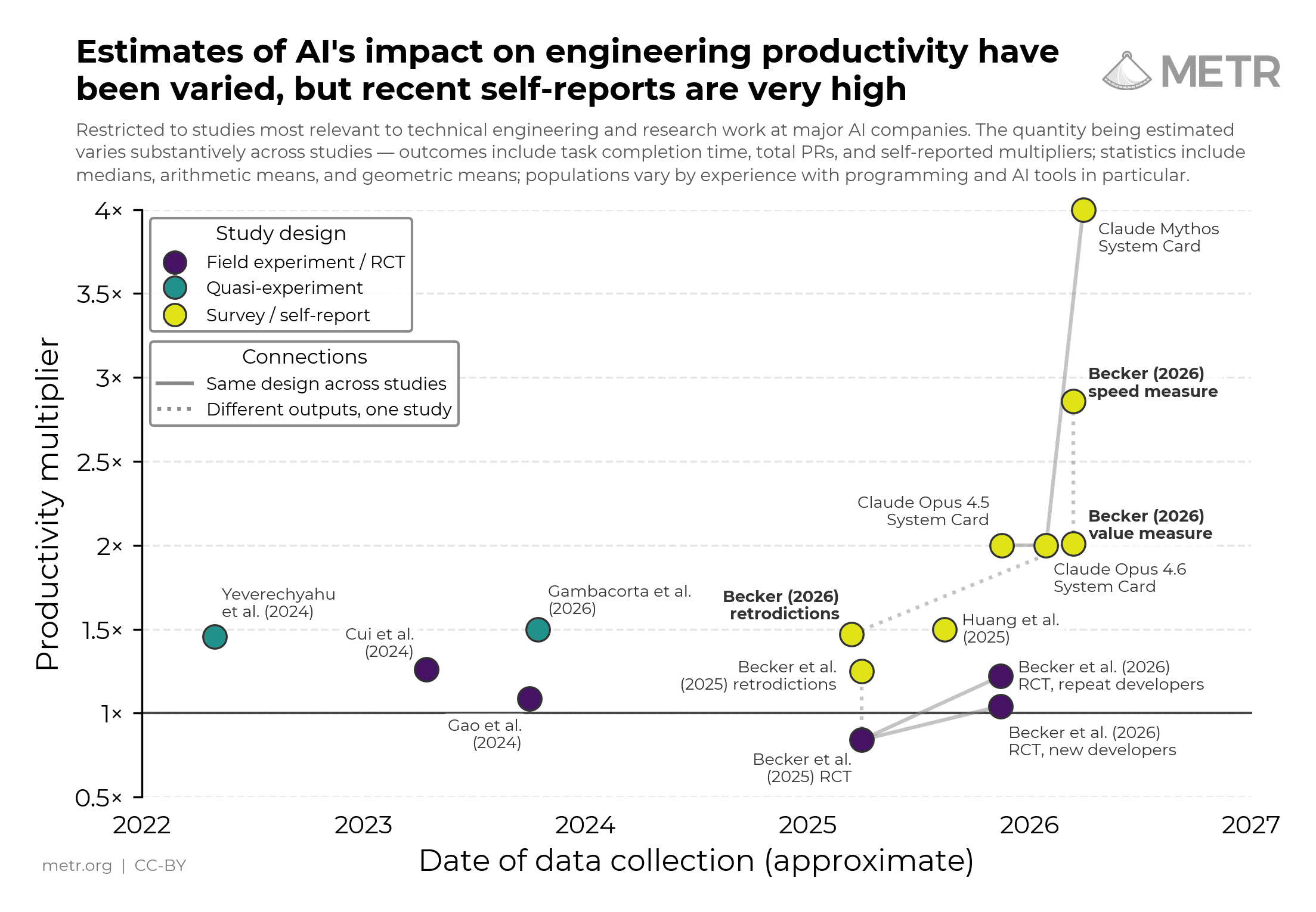
Nevertheless, we think that surveys provide a useful source of information about the true impact of AI on productivity. Surveys complement other evidence on AI capabilities – benchmarks, RCTs, data from wide deployment – each with different blind spots (more detail here). Surveys are cheap, broad, and straightforward to run inside major AI companies. Surveys can also obtain information about some types of questions that would be otherwise intractable (e.g. qualitative questions).
We would like to see those interested in tracking the potential automation of AI R&D, such as frontier AI companies, run high-quality surveys building on this work. We particularly recommend carefully defining the metric to be estimated, such as by building on the survey questions discussed here. We also suggest prioritizing surveying managers or productivity researchers over individual contributors. See more detailed recommendations here.
How surveys complement other evidence
Different sources of evidence on AI capabilities come with different pros and cons. For example:
- Benchmarks are standardized and highly replicable. They’re relatively expensive to make and then somewhat cheap to use once built, and can be cheaply rerun with modifications to understand the impact of methodological choices. On the other hand, there are often concerns about external validity (in particular, that benchmark results are an overestimate of capabilities observed in the wild); it’s challenging to think about how to map estimates to downstream quantities we care about; and they might capture a narrow slice of some larger distribution of tasks (in particular, those that are easier to cheaply evaluate).
- RCTs are carefully controlled and perhaps highly externally valid. On the other hand, they too produce an estimate that can be somewhat hard to map to downstream quantities we care about3, and they’re very expensive.4
- Observational evidence from broad deployment is very large, relatively cheap to collect, and far-reaching in terms of task distribution. However, it typically suffers from selection effects and is often hard to reason about.
We think of surveys as a flawed but useful complement to other forms of evidence on AI capabilities. As discussed in the summary, surveys have problems – most severely, that respondents have difficulty answering complex quantitative questions accurately – but they are cheap to run and can be used to study some types of questions that would be otherwise intractable.
Methodology
Here is the survey. Take it if you want! The key questions are:
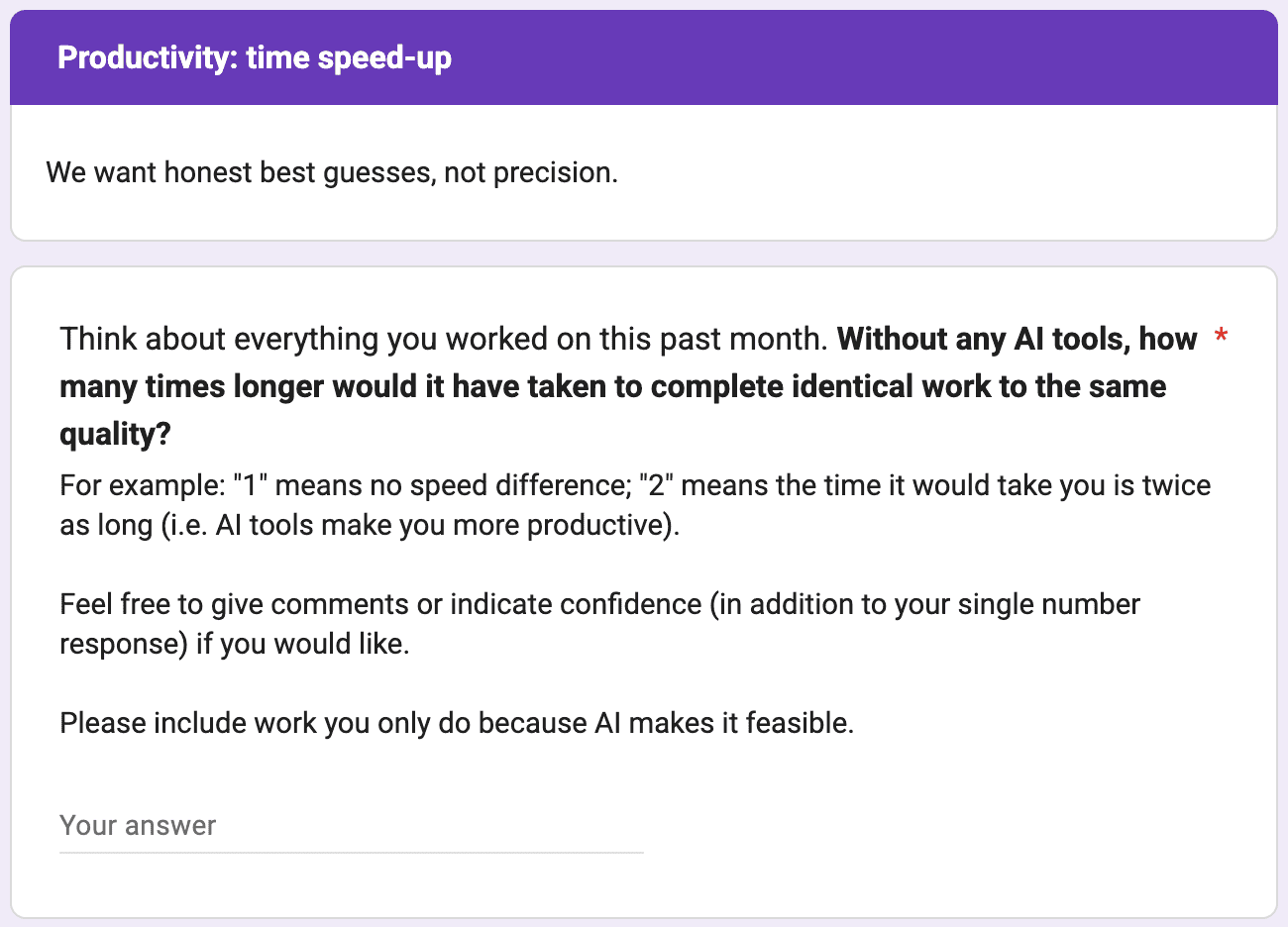
- One question conceptualizing increase in speed due to access to AI tools around March 2026.
- Three questions conceptualizing increase in value produced due to access to AI tools around March 2026, with estimates for March 2025 and March 2027 requested for one of these.
The full questions details are in the appendices.
The survey additionally asks of respondents:
- Their type of work, primary development environment, examples of use and non-use of AI, allocation of work time by activity, and how much the respondent uses AI by activity.
- Their duration of experience programming, using LLM-based tools for programming, and using AI agents for programming.
- Hypothetical willingness-to-accept for AI tools and actual spending on AI tools.
- Other questions to gain a broader understanding of respondents’ work and experience with AI tools.
This survey is larger-scale and more detailed than past surveys of frontier AI tool usage like those used by Anthropic.
One innovation in our survey is attempting to distinguish between ‘value’ and ‘speed’ uplift. Value is defined holistically, in terms of what “you, your team or your leadership would find valuable”. Speed is instead the raw difference in how long tasks take.5 We elaborate on the distinction between value and speed gains in previous research.
Speed measures may differ from value measures by, for example:
- Being inflated by individuals doing additional tasks which AI can do well or quickly but which would otherwise not have been worth prioritizing (substitution).
- Failing to capture ways in which AI makes higher-value tasks possible.
- Not accounting for decreasing or increasing returns to completing tasks.
We think value as defined in this survey is materially closer to what we care about – a multiplier on employee contribution to AI R&D progress. Speed measures are likely biased upwards with respect to value measures; however, value is also more opaque and harder for respondents to think about.67
Another innovation is attempting to triangulate the truth using measures of internal consistency. We use multiple measures and check for consistency.8 However, these checks are not decisive, and, more fundamentally, even when reporting on the internal consistency of perceptions we have little means to test whether perceptions match reality.
Participants come from a convenience sample. They were largely sourced from GitHub, academics via institutional or conference directories, METR, METR staff’s professional networks, and X (formerly twitter). Response rates are typically low – approximately 2% for respondents we email, although very significantly higher among METR staff and their networks – so our results plausibly suffer from significant selection bias.9 Approximately 70% of participants were paid to take the survey (per-hour or fixed payment); of participants who were paid, average pay is $200.
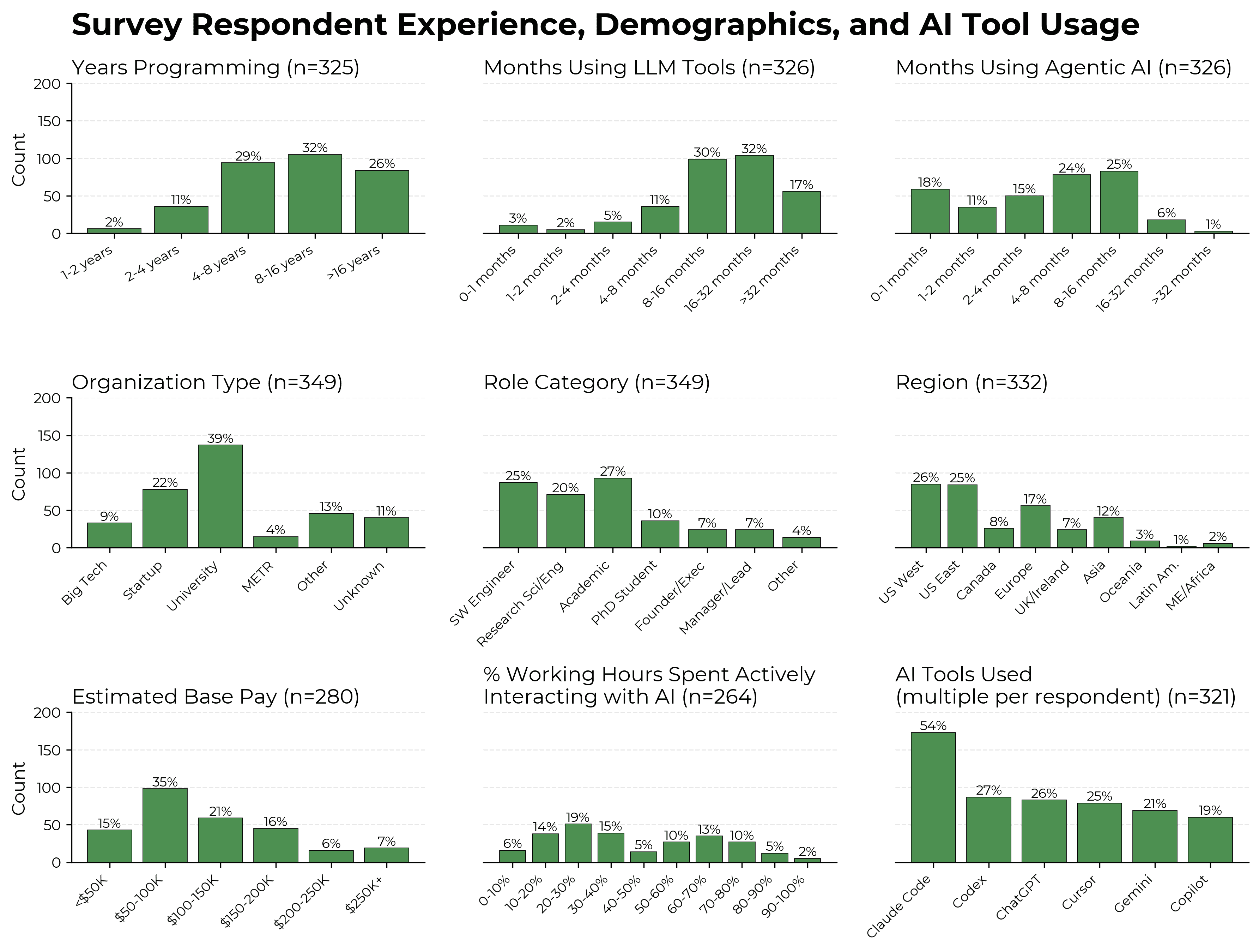
Respondents averaged 12 years programming, 19 months using AI for programming, and 7 months using agentic AI coding tools. 48% are US-based. 50% regularly use Claude Code. Academics and PhD students represent 37% of the sample. Around half of respondents are based in the US and one-quarter in Europe.
In a later section, we display some evidence for higher perceived uplift among people who currently use AI more, are more experienced using AI tools, or work at startups; we see lower perceived uplift among METR employees.
We flag answers that suggest poor data quality (extreme inconsistencies between questions, logical impossibilities, etc.) and filter out 10 respondents who have many flagged responses. See anomalies section for more information.
Results
Productivity gains around March 2026
Key questions
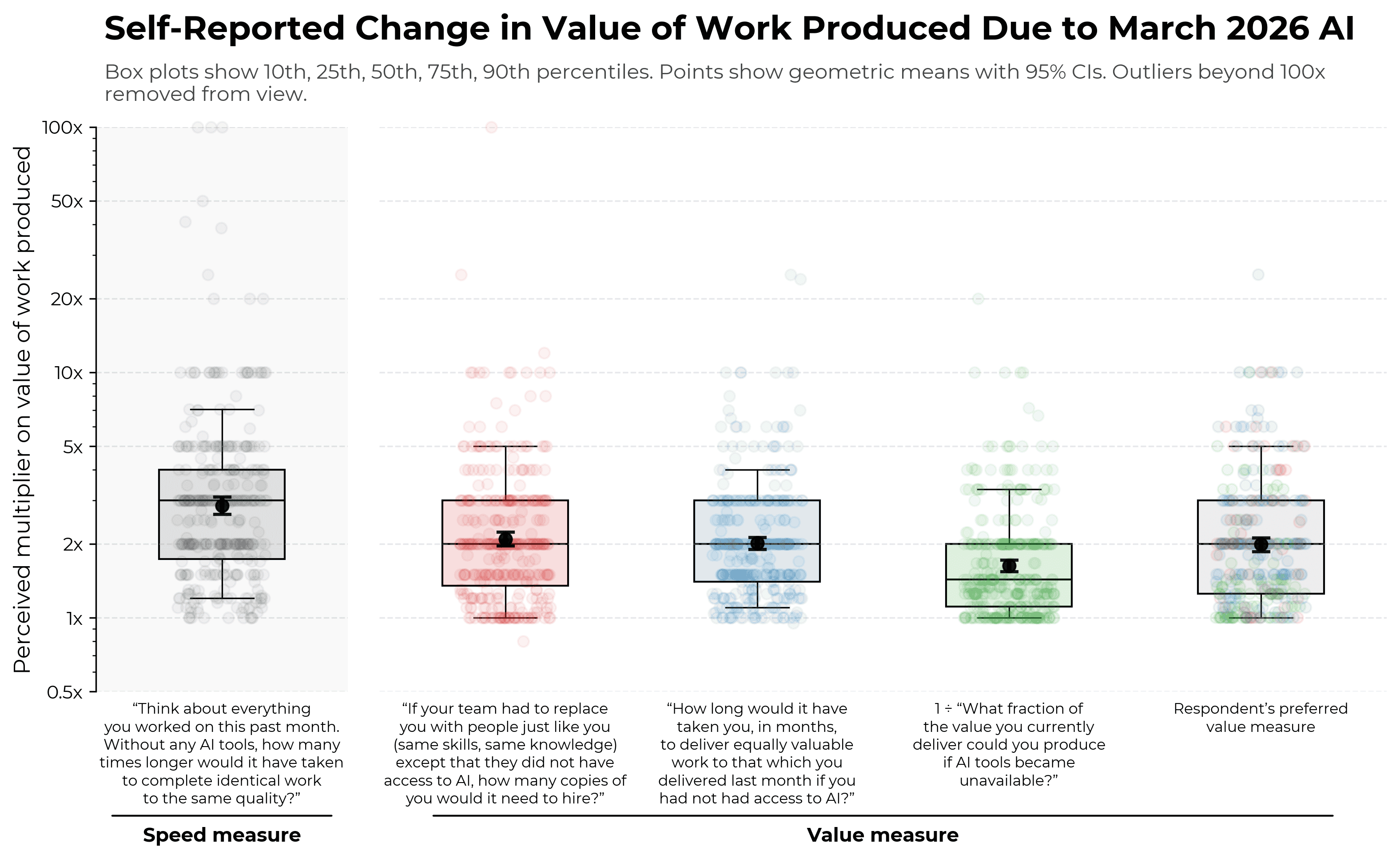
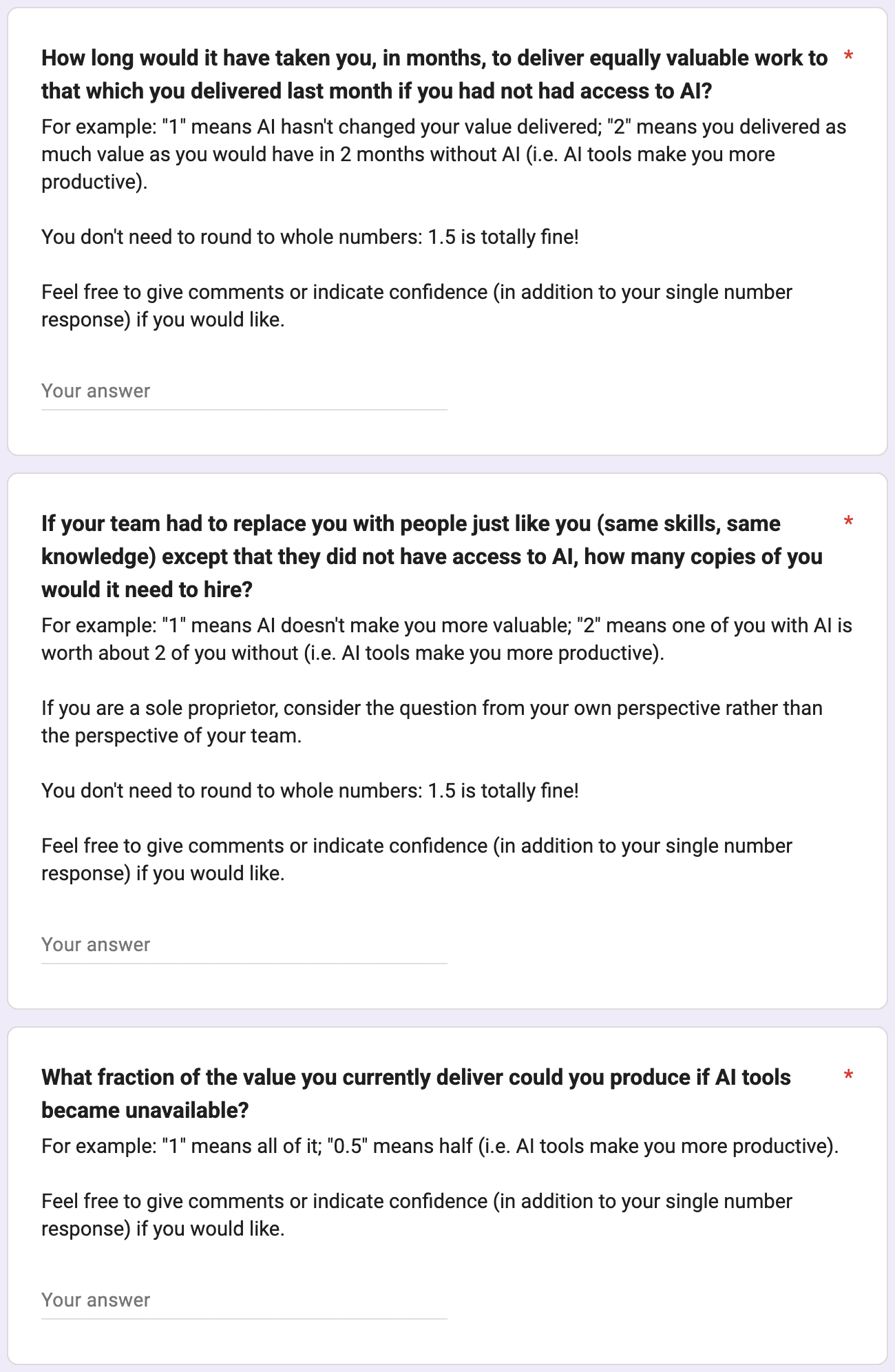
Our 3 measures of value uplift have medians between 1.4x and 2x.10
We are surprised by the ordering of value uplift results. The “fraction of the value” question was intended to be specified so that answers should be approximately equivalent to the reciprocal of the “how long would it have taken you” question, but we see a meaningful discrepancy between answers to each question. On the other hand, we anticipated that answers to the “how many copies” question would naturally be larger than answers to the “how long would it have taken you” question due to costs of parallelizing across people, but we do not find this to obviously be the case in respondents’ answers.
We find it less surprising that answers to the speed measure, which considers the change in time it takes to complete tasks after AI is available, are larger in magnitude. We had hypothesized (following our earlier research differentiating speed and value uplift) that AI users were substituting into lower-value tasks which had become much ‘cheaper’ as a result of AI, causing them to get less value out of AI usage than one might naively expect before accounting for changes in the task distribution.11
Note that different respondents find different versions of the value uplift question most intuitive; results are broadly similar if we use whichever answer they gave to their preferred question.
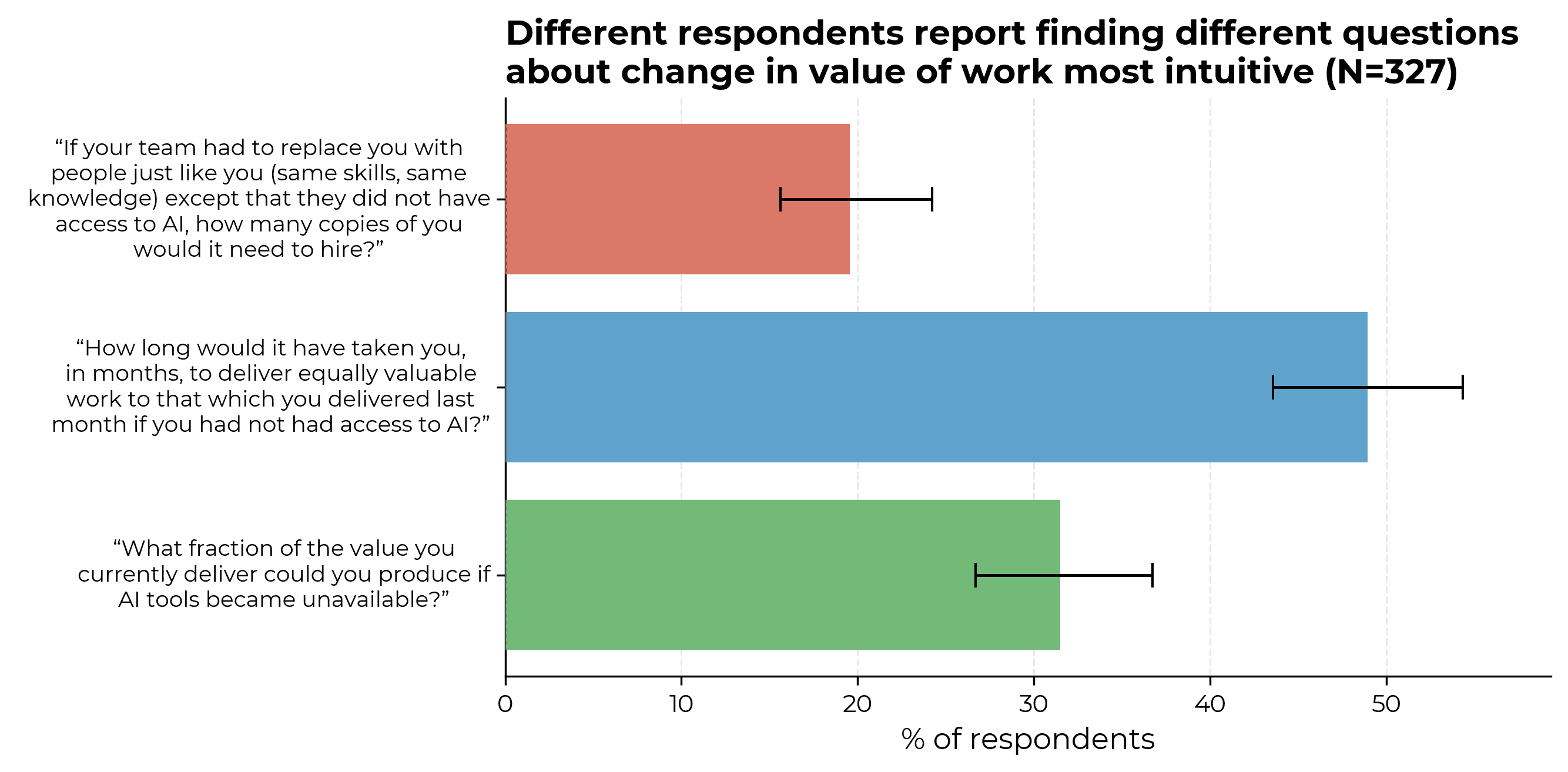
Validation/consistency checks between measures
We asked value uplift questions in several different ways partly for imperfect consistency checks, and partly because we found early on that, as above, different respondents find different versions of the value uplift question most intuitive.
Note that it’s not necessarily straightforward to interpret differences in answers between questions as a consistency check (although we do largely have this interpretation):
- Respondents could anticipate that we are running these checks, which means they might incorporate this fact into their answers.
- The questions are asking about slightly different quantities. For example, differences between the questions “How long would it have taken you, in months, to deliver equally valuable work to that which you delivered last month if you had not had access to AI?” and “If your team had to replace you with people just like you (same skills, same knowledge) except that they did not have access to AI, how many copies of you would it need to hire?” might reflect diminishing returns to copies of yourself.
Given the above, we should expect different value measures to be correlated but not perfectly so, which is what we see in the data.
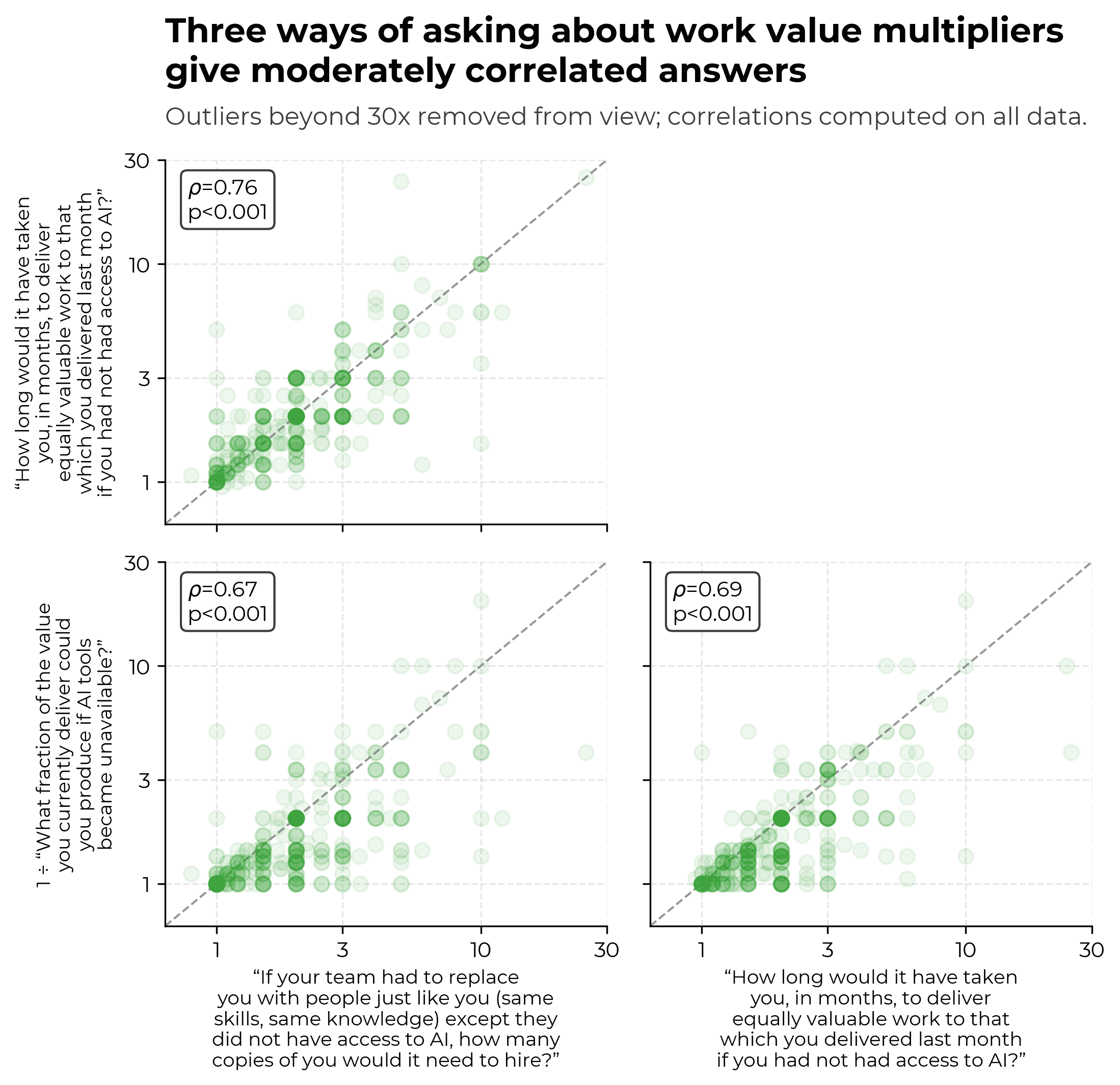
Productivity gains over time
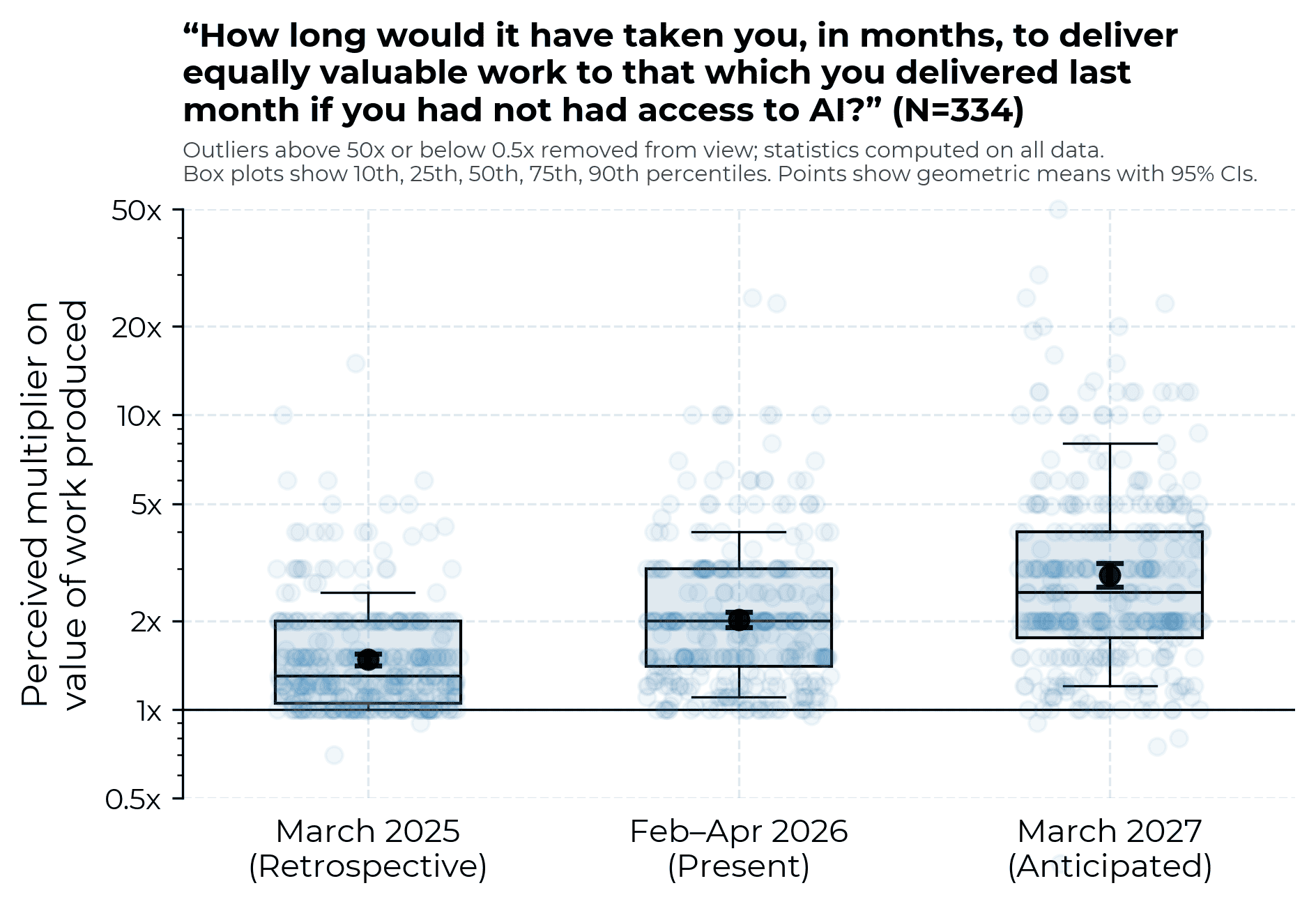
The median respondent retrospectively claims that their uplift was around 1.3x in March 2025; they expect 2.5x in 2027.
We think that averages this high are plausible estimates of typical participant beliefs. The values for March 202512 and today13 are consistent with past self-reports in public research, and we find that participants are at least moderately self-consistent in their survey answers.
Productivity gains by subgroups
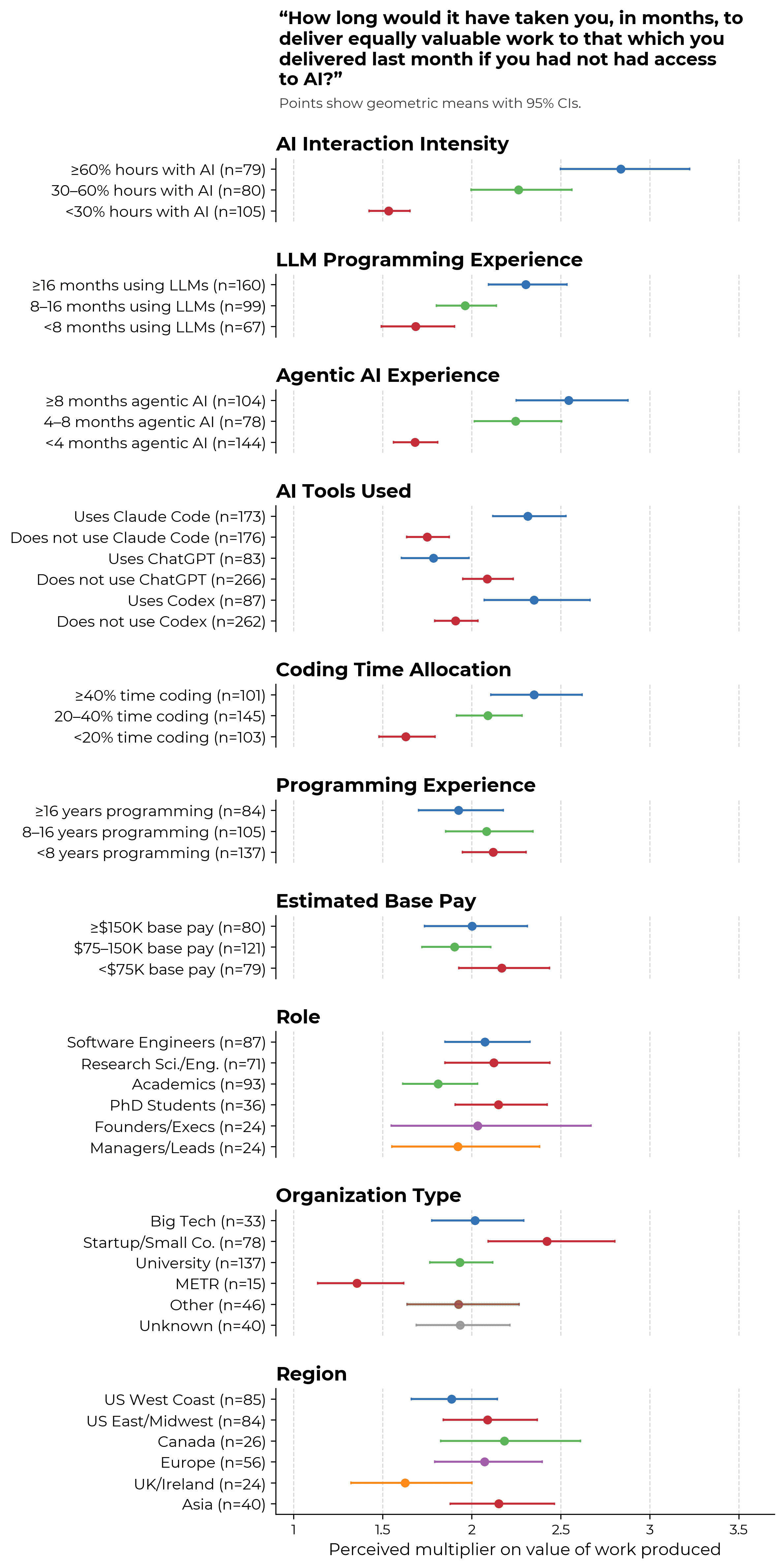
As would be expected, we find higher perceived value gains among respondents who use AI more, who have more experience using AI tools, or who use Claude Code or Codex.
On the other hand, METR employees tend to report lower value gains. We think that there are many possible hypotheses which could explain this result, including but not limited to:
- METR staff are more familiar with METR’s previous findings on gaps between perceived and actual AI-driven uplift, which causes them to downgrade their estimates closer to the ‘true’ value.
- METR staff overindex on METR’s previous findings on gaps between perceived and actual AI-driven uplift.
- METR staff face a different task distribution to other respondents.
- METR staff are less able to substitute their work towards tasks where they might get especially large value gains.
Our intuition weakly points towards the first explanation, although it is challenging to make this explicit beyond documenting the differences in reported value multipliers.
Qualitative impressions
In addition to collecting participants’ quantitative estimates, our survey prompts participants for their qualitative sense of the currently most impressive AI capabilities, where AI has been most helpful in their work, and so on. This gives us some information we can use to sense-check the quantitative estimates, albeit in an ad hoc manner with much room for researcher bias.
Overall, whilst we believe that averages as high as we observe are not implausible estimates of ‘true’ value multipliers, it does seem like a live possibility to us that respondents are giving larger answers than they would if they thought about the question for longer.
We reviewed in detail the 7 responses in our data for which at least two value measures have values greater than or equal to 10x. Our main impressions were:
- In 2 of these 7 cases we were able to view public outputs from the work completed using AI. We are confident that in both cases the participants are overstating their change in value produced as we understand it; at least, the enormously more valuable work is not externally visible.
- In 2 other cases, we are somewhat suspicious of large changes in the value of work produced because qualitative claims do not match our intuitive sense of agent capabilities.
- There is 1 instance where our best sense is that the respondent does indeed have agents doing an impressive quantity of productive work, although we suspect that this work is better captured by improved speed or quantity of output, not improved value of output.
- In the remaining 2 cases we lack sufficient qualitative information to meaningfully interpret.
Recommendations for AI companies tracking AI R&D acceleration, and other future work
This work suggests key improvements for surveys tracking the acceleration of AI R&D by AI tools, as compared to existing surveys such as those used by Anthropic. The core issue is eliciting calibrated estimates of a proxy for the acceleration of AI R&D. Two particularly promising improvements might be:
- More careful definition of the central question. As discussed previously, estimating an individual’s value multiplier rather than speed multiplier brings us materially closer to what really matters (while still being a proxy). We believe that our value-focused questions would be considerably more informative than historical speed-focused surveys.
- Asking managers or productivity researchers about the increase in value among employees at their company. These groups are closer to experts making decisions concerning the productivity impact of spending on AI tools. We might expect that they could give more grounded, unbiased answers to questions about value gains.
It is also important to ensure a sufficient sample size.
These are our highest-confidence recommendations. If you plan to run such a survey, please consider getting in touch to discuss in more detail. We would be glad to help.
Relative to our own survey, the top improvements we would make are:
- Reducing the survey length. (Many participants report survey fatigue.)
- Although we asked respondents about their hypothetical willingness-to-accept for losing access to AI tools, the evidence we were able to extract from these questions is weak. (See the relevant appendix section for more information.) We think it might be valuable to redo the willingness-to-accept questions to (a) in fact take away respondents’ AI access for 1 month with some probability, (b) ask for employer willingness-to-accept to get around the problem where respondents do not capture the value of AI tools directly, and (c) ask for respondents’ willingness-to-accept for other tools that enhance work productivity.
- The same as #2 in the recommendations above (asking managers or productivity researchers about the increase in value).
Regardless of these lessons learned, we feel there is more information that could be obtained even from a survey exactly like this one:
- Our dataset is richer than we had capacity to analyze here – containing detailed information about the most impressive AI capabilities participants have seen, participant work time allocation, the permissions and review processes participants subject AIs to, instances where AIs have taken harmful actions and attempted to hide evidence of this fact, and much more besides.
- We think it would be valuable to repeat a similar exercise inside of major AI companies, to better understand differences in self-reports using a consistent methodology.
- We also want to repeat this survey over time with the same participants. Not only would this help us learn about how AI capabilities are evolving, it would provide another means of enforcing discipline on respondent answers – by understanding how self-reported anticipated future value uplift compares with self-reported present value uplift in future.
Appendix
Exact phrasings of key questions

Willingness-to-accept analysis
If real in some sense, perceived changes in value of work due to AI on the order of 2x would appear to have major implications for revealed preferences. For instance, naively it seems like workers should be willing to make large sacrifices to retain access to AI tools.
Indeed, the median participant claims that they would sacrifice 29% of their salary to keep access to AI tools for 1 month.
Although we interpret this finding as suggesting broad consistency between average answers among our survey participants, we consider the evidence to be weak.
First, we have many uncertainties about data quality. Our salary estimates come from Claude Opus 4.6 making a best estimate of base pay given the participants’ employer and location; we have done some validation of these numbers, but not nearly enough to feel confident about their accuracy. Additionally, the willingness-to-accept (WTA) data has surprisingly high variance (including people who would pay >100% of their estimated wage); apparent consistency between averages hides a lot of variation between participants.
Second, our comparison between WTA measures and ‘value’ multipliers is not straightforward to interpret. Asking people how much they would personally pay to retain access to AI tools at work is plausibly very flawed as a measure of the value they get out of AI, principally because employed workers aren’t the party capturing value (their employers are).14 Diminishing returns to income and consumption pose a further challenge.
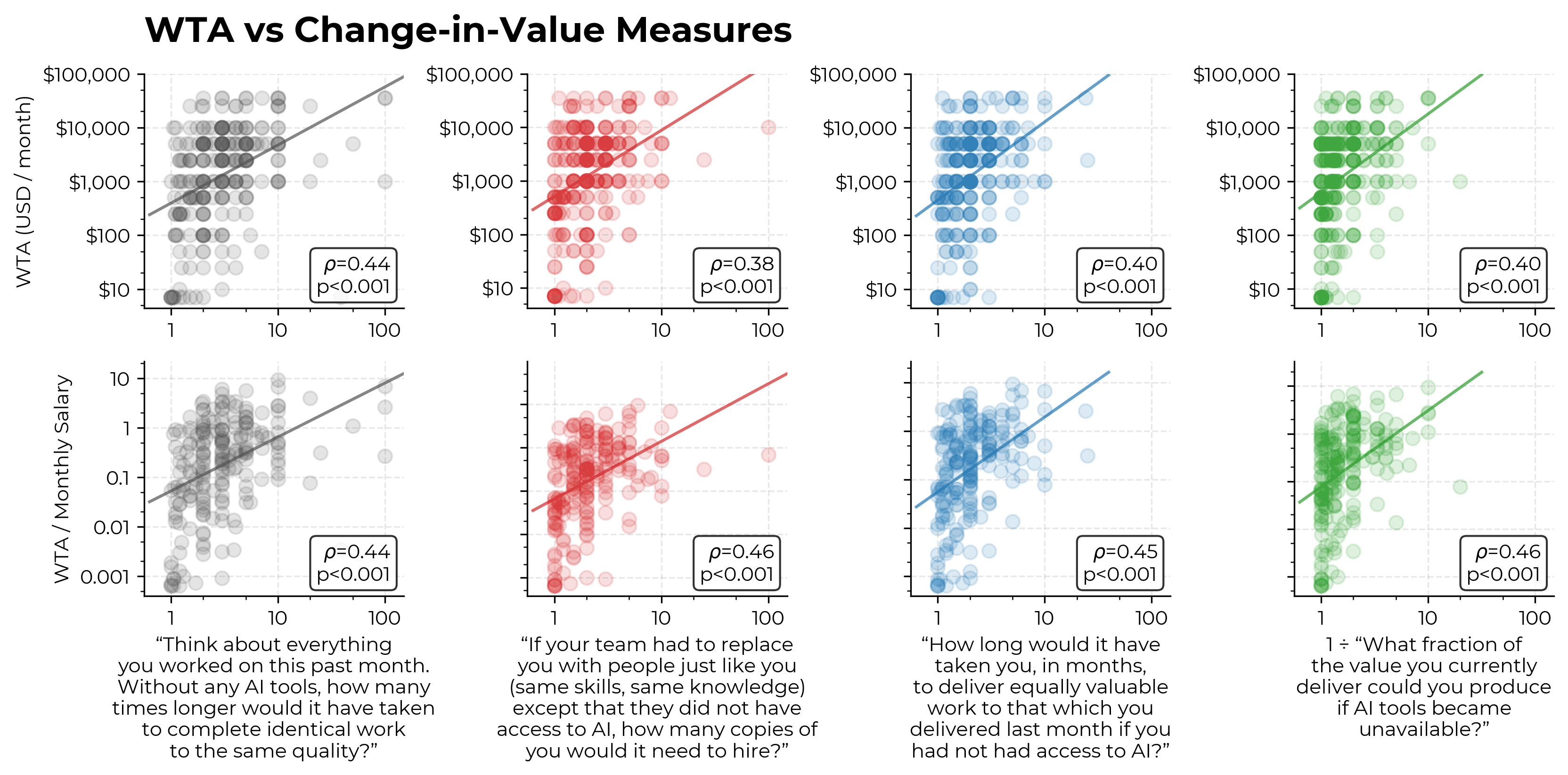
Data quality
We filter out 10 responses from the 359 unique respondents in our raw data (3% of sample) due to a pattern of quality issues with their answers.
To determine which responses to filter out, we tally up points for possible data quality issues, then remove responses above a cut-off of 5 points.
Anomalous response flags and associated points are listed below. If responses are flagged as severe by some data quality criteria, they receive points for both moderate and severe tiers.
| Flag | Moderate | Severe | Points per tier |
|---|---|---|---|
| All work time allocation values identical (and >=3 filled) | - | - | 2 |
| All AI intensity ratings identical (and >=3 filled) | - | - | 2 |
| Agentic tool experience exceeds LLM tool experience | - | - | 3 |
| Skipped agent permissions question entirely | - | - | 1 |
| Skipped review practices question entirely | - | - | 1 |
| Work time lower-bound sum exceeds threshold | >= 150% | >= 300% | 1 |
| Value/speedup metrics disagree on direction | low=0.8, high=1.25 | low=0.6, high=1.67 | 3 |
| Q2 (months) and Q3 (copies) diverge | >= 3x | >= 10x | 1 |
| Q2 (months) and 1/Q4 diverge | >= 2x | >= 4x | 1 |
| Q3 (copies) and 1/Q4 diverge | >= 3x | >= 10x | 1 |
| Value estimate declines from 2025 to present | >= 1.1x | >= 2x | 1 |
| Value estimate declines from present to 2027 | >= 1.1x | >= 2x | 1 |
| Value estimate declines from 2025 to 2027 | >= 1.1x | >= 2x | 1 |
| Value trajectory timepoints not parsed | 2 not parsed | 3 not parsed | 1 |
| Willingness-to-accept far exceeds salary | >= 5x | >= 20x | 1 |
Respondents with >5 points are then filtered from the clean output. Approximately one third of respondents have 0 anomalous data flags.
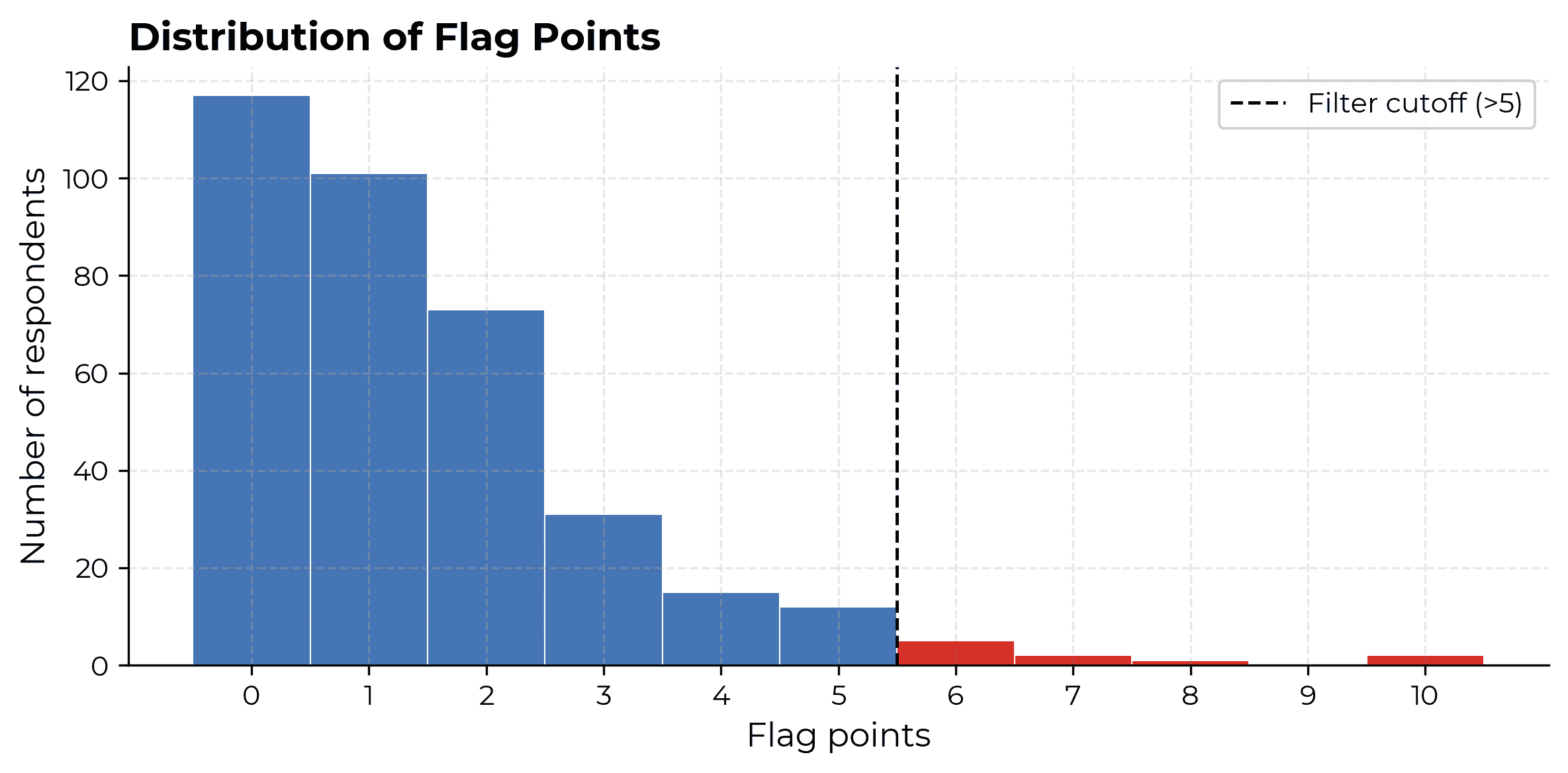
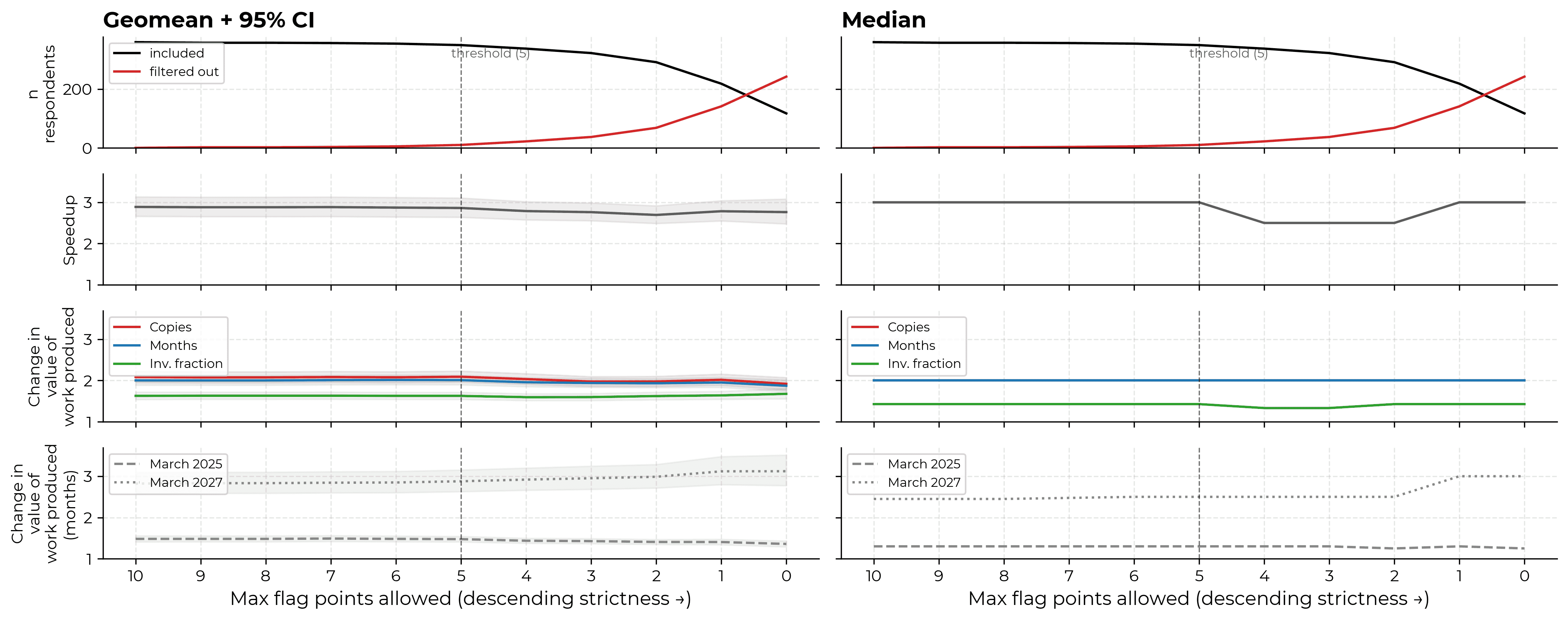
Having a logically impossible work allocation is by far the most common bad data flag. Significantly declining uplift is next most common. That said, conditional on being filtered out for having plausibly bad data, potential data quality issues are fairly diverse.
The majority of our central claims are not sensitive to the level at which we set our filter. The median answer to our speed measure is close to the boundary and so can be sensitive. The March 2027 value multiplier increases somewhat with very tight filters.
-
Previous surveys of the quantitative impact of AI on the productivity of engineers or researchers similar to those at major AI companies have typically had smaller sample sizes. The Claude Opus 4.5 and 4.6 system cards have N<20 surveys; the Mythos system card reports results from a 130-person slack poll; Huang et al. (2025) conducts a 132-person survey; Becker et al. (2025) survey all N=16 developers after completion of their experiment. ↩
-
The most relevant experimental data was typically conducted in 2024 or earlier (except for METR RCTs covering early and late 2025 respectively), while the most relevant surveys were typically run in 2025 or later, by which time autonomous AI capabilities had significantly advanced. To our knowledge, only one study gathered survey and field experiment results on the same population and metric – Becker et al. (2025), which finds that developers overestimate productivity gains by over 40 percentage points. Further, the quantities being estimated in previous literature varies substantially across studies, adding to difficulties comparing estimates. ↩
-
For instance, our early and late 2025 developer productivity RCTs plausibly involve tasks selected in-between pre-AI and post-AI ‘prices’ (in the language of our recent research distinguishing value and speed uplift), posing a challenge for interpretation. ↩
-
In fact, RCTs might become increasingly expensive, as the extra effort required to complete tasks without AI increases over time. ↩
-
The choice of tasks to consider leads to at least two ways of answering this question: (i) the time it would take to do tasks you would have done if you did not have access to AI but now with AI; (ii) the time it would take to do tasks you would have done if you did have access to AI. We guess that respondents to Anthropic surveys might be interpreting productivity improvements under (ii), which leads them to overestimate productivity improvements (after they substitute into higher-uplift, lower-value tasks). ↩
-
Hopefully our survey also gets people thinking more concretely about their work and uses measures that better track what we care about , but our work to validate this is limited, and in feedback people report survey fatigue, which pushes against this. ↩
-
Further, even if we did succeed in capturing value gains, this still is only a proxy answer for the question we really care about, which is whether AI capabilities are causing additional AI progress overall, not just for individual AI researchers (e.g. incorporating change in organizational structure, and autonomous AI research contributions). ↩
-
There are other consistency analyses we could perform with existing survey materials, for example mapping plausible ranges of uplift given work time allocation and AI usage intensity by work time category. ↩
-
In particular, selection for people who start and finish surveys, perhaps because they have thought a lot about the topic in question, or have unusual views on AI usage. ↩
-
Note that it is not obvious which summary statistic is most appropriate. One justification for geometric mean as a summary statistic for our data might be that participants have multiplicative response errors, which seems plausible. The deeper problem is that we do not know how to map respondent-level data to the larger question we care about – how much faster AI capabilities progress is going as a result of AI capabilities. ↩
-
In fact, we are surprised that the gap between speed and value measures is not larger. We expected many cases where people were substituting into very different tasks (e.g. academics using AI web development capabilities to make small websites) which would provide small increases in value but naively suggest dramatic time savings (e.g. the website might have taken 30x as long, which would mean that if you later spent 4 hours of your working week on the website you have at least a 1*(90% of work week) + 30*(10% of work week) = 3.9x speed uplift). ↩
-
1.3x median March 2025 value uplift appears broadly consistent with the approximately 32% perceived time uplift for our previous experiment centered in March 2025. In this experiment, value gains more plausibly coincided with speed gains because people did not seem to change which tasks they were doing in response to having AI. ↩
-
As in the survey discussed in Anthropic’s Claude Opus 4.6 system card. ↩
-
In hindsight, we might have asked respondents how much their employer values their access to AI tools. We also could have asked about how respondents value the internet, their calendar system, and so on. ↩