Hemos estado conversando con varias partes1 sobre políticas de escalamiento responsable (responsible scaling policies, RSP).2 Una RSP debe aclarar dos cosas: qué capacidades de IA puede manejar de forma segura un desarrollador con sus medidas de protección actuales, y en qué circunstancias sería necesario mejorar esas protecciones antes de seguir desplegando sistemas o aumentando sus capacidades.
Creemos que una adopción amplia de RSP de alta calidad, con los componentes clave que detallamos más abajo, reduciría mucho el riesgo de una catástrofe de IA frente a un escenario de “seguir como siempre”. Dicho esto, no esperamos que los compromisos voluntarios basten para contener adecuadamente los riesgos de la IA. Las RSP se diseñaron como un primer paso que podían dar los laboratorios preocupados por la seguridad, no como una herramienta pensada principalmente para responsables de políticas públicas. No las vemos como sustituto de la regulación, ni ahora ni en el futuro.3
Esta página explica la idea básica de las RSP tal como la entendemos, y luego discute:
Por qué creemos que las RSP son prometedoras. En resumen:
- Pueden responder a posturas distintas. Las RSP buscan ser útiles tanto para quienes creen que la IA podría ser extremadamente peligrosa y apoyan medidas como una moratoria al desarrollo de IA, como para quienes creen que todavía es demasiado pronto para preocuparse. Desde ambas perspectivas, una RSP puede ser una intervención valiosa: la continuidad del desarrollo depende de evaluaciones concretas y observaciones empíricas. Si las evaluaciones son suficientemente precisas, deberíamos esperar que el desarrollo de IA se detenga cuando aparezcan capacidades peligrosas, y que continúe cuando esas capacidades aún no hayan aparecido.
- Ayudan a priorizar medidas de protección. Una RSP ayuda a los desarrolladores de IA a pasar de principios generales de cautela a compromisos concretos. También les da un marco para decidir qué medidas deben priorizar para seguir desarrollando y desplegando sistemas: seguridad de la información, rechazo de solicitudes dañinas, investigación de alineación, etc.
- Impulsan reglas y normas basadas en evaluaciones. A más largo plazo, nos entusiasman las reglas y normas de IA basadas en evaluaciones: requisitos para evaluar sistemas de IA en busca de capacidades peligrosas y restringirlos cuando esa sea la única forma de contener los riesgos, hasta que mejoren las medidas de protección. Esto podría incluir estándares, auditorías de terceros y regulación. Las RSP voluntarias pueden adoptarse rápido y servir como banco de pruebas para procesos y técnicas que luego podrían incorporarse a regímenes regulatorios basados en evaluaciones.
Qué vemos como los componentes clave de una buena RSP, con ejemplos de lenguaje para cada componente. En resumen, creemos que una buena RSP debería cubrir:
- Límites: qué observaciones concretas sobre capacidades peligrosas indicarían que seguir escalando ya no es seguro, o probablemente no lo es.
- Protecciones: qué aspectos de las medidas de protección actuales son necesarios para contener riesgos catastróficos.
- Evaluación: qué procedimientos permiten detectar con rapidez señales tempranas de que se están alcanzando límites de capacidades peligrosas.
- Respuesta: si las capacidades peligrosas sobrepasan los límites y no es posible mejorar las protecciones con rapidez, si el desarrollador está preparado para pausar nuevas mejoras de capacidades hasta que las protecciones sean suficientes y para tratar cualquier modelo peligroso con la cautela necesaria.
- Rendición de cuentas: cómo se asegura el desarrollador de que los compromisos de la RSP se ejecutan como está previsto; que las partes interesadas clave pueden verificarlo, o notar si no ocurre; que hay oportunidades de crítica por parte de terceros; y que los cambios a la propia RSP no se hacen de forma apresurada u opaca.
Idealmente, adoptar una RSP debería ser una señal fuerte y confiable de que un desarrollador de IA probablemente identificará cuándo seguir escalando capacidades se vuelve demasiado peligroso, y reaccionará de manera adecuada.
La idea básica de las RSP
Distintas partes pueden entender cosas distintas por “escalamiento responsable”. Esta página se centra en lo que nosotros (ARC Evals) consideramos importante de la idea.
Una RSP busca mantener las medidas de protección por delante de las capacidades peligrosas que tengan los sistemas de IA. Una ilustración aproximada:
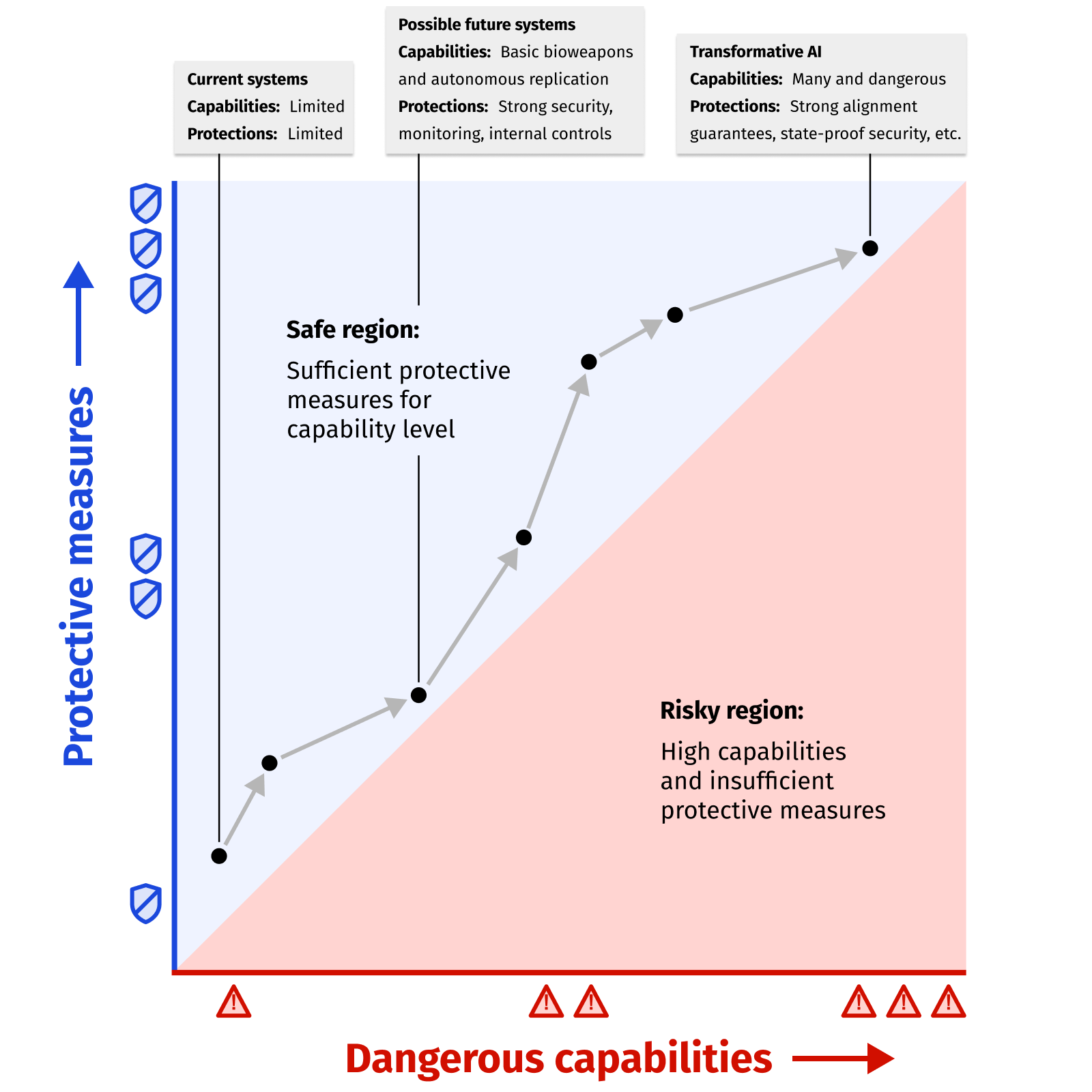
Estos son dos ejemplos de capacidades peligrosas que un desarrollador podría abordar en una RSP. En cada caso damos nuestra mejor estimación de qué haría falta para manejar la capacidad de forma segura. Para simplificar, presentamos los ejemplos sin muchas salvedades; esta sigue siendo un área de investigación, y aquí los ejemplos son principalmente ilustrativos.
Ejemplo ilustrativo: si la IA pudiera aumentar el riesgo de armas biológicas, haría falta una seguridad de la información fuerte para evitar el robo de pesos antes de que fuera seguro construir el modelo. Para desplegarlo, también harían falta monitoreo y restricciones que impidan usarlo para desarrollar armas biológicas.
- Algunos biólogos han argumentado4 que los grandes modelos de lenguaje (LLM) podrían “eliminar algunas barreras que encontraron los esfuerzos históricos de armas biológicas”. Hoy, alguien con suficiente conocimiento de biología probablemente podría construir un arma biológica peligrosa y tal vez causar una pandemia. Los LLM futuros podrían aumentar el riesgo al hacer que esa “experticia” esté ampliamente disponible, por ejemplo guiando en detalle a posibles terroristas por protocolos de biología.
- Si un LLM fuera lo bastante capaz para esto, sería importante que su desarrollador garantizara que:
(a) El modelo esté configurado de modo que los usuarios, internos o externos, no puedan hacerlo ayudar con armas biológicas, por ejemplo mediante restricciones de uso, monitoreo o entrenamiento para que rechace proporcionar información relevante con muy alta confiabilidad.
(b) Su seguridad de la información sea lo bastante fuerte como para confiar en que actores maliciosos no puedan robar los pesos ni eludir esas restricciones de otra forma. - En una RSP, un desarrollador de IA podría comprometerse a evaluar sus sistemas en busca de capacidades de desarrollo de armas biológicas, y a garantizar (a) y (b) para cualquier sistema de IA con capacidades fuertes en esta área.
- Si el desarrollador no pudiera garantizar (a), tendría que abstenerse de desplegar el sistema, incluso internamente. Si no pudiera garantizar (b), tendría que proteger los pesos tanto como sea posible y evitar desarrollar nuevos modelos con esas capacidades hasta contar con suficiente seguridad de la información.
- Las capacidades de desarrollo de armas biológicas probablemente aparecerían junto con capacidades muy beneficiosas, por ejemplo para investigación médica. Un desarrollador que pudiera impedir el uso dañino y proteger el sistema contra el robo por parte de terroristas podría seguir desplegando sistemas con estas capacidades.
Ejemplo ilustrativo: si la IA tuviera capacidades de “replicación y adaptación autónomas” (ARA), haría falta una seguridad de la información fuerte y, a más largo plazo, quizá garantías de alineación.
- ARC Evals investiga la capacidad de agentes LLM para adquirir recursos, crear copias de sí mismos y adaptarse a desafíos nuevos en entornos abiertos. Llamamos a estas capacidades “replicación y adaptación autónomas”, o ARA. También se las ha llamado “autorreplicación”; varias empresas de IA se han comprometido a evaluar sus sistemas en este aspecto, como anunció la Casa Blanca.
- Los sistemas con capacidades ARA podrían usarse para crear gusanos informáticos de una flexibilidad sin precedentes, capaces de propagarse mediante ingeniería social además de explotar vulnerabilidades informáticas. Actores maliciosos como estados rebeldes o grupos terroristas podrían desplegarlos para causar la máxima disrupción. Podrían crecer hasta millones de copias y cometer ciberdelitos o llevar campañas de desinformación a una escala hoy imposible para actores maliciosos. También podrían mejorar sus propias capacidades y resiliencia con el tiempo. Existe la posibilidad de que, con el apoyo de incluso un pequeño número de humanos, estos sistemas fueran impracticables de apagar. Estos riesgos podrían crecer rápidamente a medida que mejoran los sistemas.
- En el futuro, la sociedad quizá pueda manejar y apagar modelos autorreplicantes, posiblemente mediante un uso muy extendido de sistemas de IA muy capaces que se mantengan mutuamente bajo control. Eso exigiría alta confianza en la alineación para evitar conductas no deseadas de la IA. Hasta entonces, manejar de manera segura IA con capacidades ARA requiere muy buena seguridad de la información para prevenir la exfiltración de los pesos del modelo, ya sea por actores maliciosos o potencialmente por el propio modelo.
- En una RSP, un desarrollador de IA podría comprometerse a evaluar regularmente sus sistemas en busca de capacidades ARA y a tomar medidas decisivas si estas capacidades aparecen antes de que existan seguridad de la información o medidas sociales de contención suficientemente fuertes. En este caso, una medida decisiva podría ser restringir la IA a entornos extremadamente seguros, o pausar el desarrollo de IA para centrarse en análisis y mitigación de riesgos.
Algunas capacidades imaginables de la IA exigirían medidas de protección extremas, muy lejos de lo que hoy podemos lograr. Por ejemplo, si la IA tuviera el potencial de provocar la extinción humana, o de automatizar la investigación en IA y acelerar rápidamente una situación así, sería extraordinariamente difícil contar con protecciones suficientes. Podrían hacer falta grandes avances en la ciencia básica de la seguridad de la IA y de la seguridad de la información, avances que quizá tarden mucho tiempo y sean difíciles de predecir. Una RSP podría comprometerse a una pausa indefinida en esas circunstancias, hasta que haya progreso suficiente en las medidas de protección.
Por qué las RSP son importantes
Las RSP son deseables tanto si se estima que el riesgo es alto como si se estima que es bajo
Las RSP buscan ser útiles tanto para quienes creen que la IA podría ser extremadamente peligrosa y apoyan medidas como moratorias al desarrollo de IA, como para quienes creen que todavía es demasiado pronto para preocuparse por capacidades con potencial catastrófico, y que necesitamos seguir construyendo sistemas más avanzados para entender los modelos de amenaza.
Desde ambas perspectivas, las RSP son una intervención prometedora: al condicionar el escalamiento a evaluaciones concretas y observaciones empíricas, si las evaluaciones son suficientemente precisas, deberíamos esperar que el desarrollo de IA se detenga cuando observemos capacidades peligrosas, y que continúe cuando las preocupaciones sobre esas capacidades resulten exageradas.
Las RSP pueden ayudar a los desarrolladores de IA a planificar, priorizar y hacer cumplir medidas que reducen riesgos
Para adoptar una RSP, un desarrollador de IA tiene que pasar de principios generales de cautela a compromisos concretos, y definir su posición sobre:
- Qué capacidades peligrosas especificadas estarían más allá de lo que sus medidas de protección actuales pueden manejar de forma segura.
- Qué cambios y mejoras necesitaría para manejar esas capacidades de forma segura.
- Por tanto, qué pruebas son más cruciales y qué medidas de protección es más urgente mejorar y planificar de antemano para seguir escalando capacidades a medida que avanza el desarrollo.
Las RSP, tal como las especificamos abajo, también exigen procedimientos claros para asegurar que las evaluaciones de capacidades peligrosas se realicen de manera fiable y que cualquier respuesta necesaria llegue a tiempo para contener los riesgos.
Una RSP no sustituye medidas de protección como mejorar la seguridad de la información, detectar y frenar interacciones dañinas con IA, aumentar la transparencia y la rendición de cuentas, o investigar la alineación. Al contrario: compromete al desarrollador a tener éxito en esas medidas de protección si quiere seguir escalando capacidades de IA más allá de un punto que de otro modo sería demasiado peligroso.
Las RSP pueden dar al mundo práctica para reglas y normas más amplias basadas en evaluaciones
Creemos que hay mucho potencial en reglas y normas de IA basadas en evaluaciones: requisitos para evaluar sistemas de IA en busca de capacidades peligrosas y restringirlos cuando esa sea la única forma de contener los riesgos. Con el tiempo, esto debería incluir estándares de la industria, auditorías de terceros, regulación estatal y nacional, diversos mecanismos internacionales de aplicación,5 etc.
Desarrollar reglas y normas eficaces basadas en evaluaciones requerirá mucho trabajo e iteración. Habrá muchísimos detalles que resolver: qué evaluaciones ejecutar, cómo y con qué frecuencia ejecutarlas, qué medidas de protección hacen falta para qué capacidades peligrosas, etc.
Las RSP pueden ser diseñadas, probadas e iteradas con rapidez y flexibilidad por distintas partes. Por eso creemos que pueden ser útiles para reglas y normas más amplias basadas en evaluaciones.
En concreto, creemos que es realista esperar que:
- En unos meses, más de un desarrollador de IA haya redactado y adoptado una RSP inicial razonablemente fuerte.
- Después, terceros comparen las RSP de distintos desarrolladores, las critiquen y las sometan a pruebas de estrés, lo que llevará a mejores RSP. Al mismo tiempo, los desarrolladores ganarán experiencia aplicando sus propias RSP: ejecutando pruebas, mejorando protecciones para seguir el ritmo del progreso en capacidades, y resolviendo muchos detalles y desafíos logísticos.
- En algún momento, más de un desarrollador de IA contará con RSP fuertes, prácticas y probadas en el terreno. Sus prácticas, y las personas que las hayan implementado, serán recursos muy valiosos para reglas y normas más amplias basadas en evaluaciones. Esto no significa que los estándares o la regulación deban copiar las RSP sin más; por ejemplo, actores externos probablemente querrán estándares de seguridad más altos que los que los desarrolladores se impongan a sí mismos. Pero contar con muchas prácticas existentes como punto de partida, y con personas con experiencia que puedan ser contratadas, podría ayudar a que la regulación sea mejor en todos los aspectos: mejor orientada a los riesgos clave, más efectiva y más práctica.
¿Qué pasa si las RSP frenan a las empresas que las adoptan, mientras otras avanzan deprisa?
Una forma en que las RSP podrían no reducir el riesgo, o incluso aumentarlo, sería esta dinámica: “los desarrolladores cautelosos de IA acaban desacelerando para evitar riesgos, mientras los desarrolladores menos cautelosos avanzan tan rápido como pueden”.
Los desarrolladores pueden reducir este riesgo incorporando flexibilidad en sus RSP, por ejemplo:
- Si creen que los riesgos derivados del escalamiento continuo de otros actores son inaceptablemente altos, y han agotado otras vías para prevenirlos, incluida la defensa intensiva de medidas regulatorias, entonces en algunos escenarios podrían seguir escalando ellos mismos. A la vez, deberían seguir trabajando con gobiernos u otras autoridades para tomar medidas inmediatas que limiten el escalamiento de todos los desarrolladores de IA, incluidos ellos mismos.
- En ese caso, deberían ser explícitos con sus empleados, su junta directiva y las autoridades estatales: están invocando esta cláusula y su escalamiento ya no es seguro. Deben dejar claro que existen riesgos catastróficos inmediatos, no hipotéticos y futuros, de sistemas de IA, incluidos los suyos, y deben rendir cuentas por la decisión de seguir adelante.
Las RSP con este tipo de flexibilidad seguirían exigiendo pruebas rigurosas de capacidades peligrosas. También seguirían llamando a priorizar medidas de protección, para evitar tener que avanzar explícitamente con IA peligrosa. Y seguirían siendo un primer paso hacia reglas y normas más estrictas basadas en evaluaciones.
Otros inconvenientes de las RSP
Las buenas RSP requieren evaluaciones que detecten de manera confiable señales tempranas de riesgos clave. Pero tampoco queremos evaluaciones que den falsas alarmas constantemente. La ciencia de evaluar riesgos catastróficos de la IA es muy nueva, y no está garantizado que podamos construir métricas que detecten señales tempranas de manera confiable sin generar falsas alarmas constantes.
Aunque, en conjunto, creemos que las RSP son una clara mejora respecto al statu quo, nos preocupan los problemas que podrían surgir por evaluaciones insuficientemente buenas, o por una comunicación poco fiel sobre lo que debe hacer una RSP para prevenir adecuadamente el riesgo.
Componentes clave de una buena RSP
Véase esta página para nuestra guía sobre los componentes clave de una buena RSP, junto con ejemplos de lenguaje para cada componente.
En resumen, creemos que una buena RSP debería incluir todo lo siguiente:
- Límites: qué observaciones concretas sobre capacidades peligrosas indicarían que seguir escalando ya no es seguro, o probablemente no lo es.
- Protecciones: qué aspectos de las medidas de protección actuales son necesarios para contener riesgos catastróficos.
- Evaluación: qué procedimientos permiten detectar con rapidez señales tempranas de que se están alcanzando límites de capacidades peligrosas.
- Respuesta: si las capacidades peligrosas sobrepasan los límites y no es posible mejorar las protecciones con rapidez, si el desarrollador está preparado para pausar nuevas mejoras de capacidades hasta que las protecciones sean suficientes y para tratar cualquier modelo peligroso con la cautela necesaria.
- Rendición de cuentas: cómo se asegura el desarrollador de que los compromisos de la RSP se ejecutan como está previsto; que las partes interesadas clave pueden verificarlo, o notar si no ocurre; que hay oportunidades de crítica por parte de terceros; y que los cambios a la propia RSP no se hacen de forma apresurada u opaca.
Nuestra lista de componentes clave está pensada sobre todo para grandes desarrolladores de IA que buscan ampliar la frontera de capacidades. También ofrece algo de orientación sobre RSP mucho más simples para desarrolladores de IA que no están ampliando esa frontera.
Estamos en deuda con muchas personas que han trabajado en ideas similares a las RSP, han contribuido a nuestro pensamiento sobre ellas y han dado comentarios sobre esta publicación. Queremos reconocer especialmente a Paul Christiano por gran parte del contenido intelectual y el diseño de lo que entendemos por RSP, y a Holden Karnofsky y Chris Painter por ayudar con el encuadre y el lenguaje.
Esta publicación fue editada el 26/10/2023 tras recibir comentarios de lectores. La versión original está aquí.
-
Véanse las discusiones sobre escalamiento responsable en un comunicado de prensa de un senador estatal de California, un discurso y tuits de Michelle Donelan, secretaria de Estado de Ciencia, Innovación y Tecnología del Reino Unido, y una entrada de blog de Anthropic. ↩
-
“Escalamiento” se usa aquí en sentido amplio: “aumentar las capacidades de los sistemas de IA más allá de lo observado antes”. “Escalamiento responsable” también incluye mejoras en complementos y herramientas, prompting y elicitation, métodos y datos de ajuste fino, etc. ↩
-
Este párrafo fue editado el 26/10/2023 tras comentarios de lectores preocupados por que se nos interpretara como si dijéramos que las RSP son un buen sustituto de la regulación, o que las pausas condicionales al escalamiento son un buen sustituto de una pausa inmediata si esta pudiera lograrse de manera global y confiable. Las opiniones sobre regulación y pausas al escalamiento varían dentro de ARC Evals; véanse algunas opiniones de Paul Christiano aquí y de Beth Barnes aquí. ↩
-
Por ejemplo, véanse Sandbrink 2023 y Esvelt et al. 2023. ↩
-
Estos podrían incluir tratados, sanciones condicionales, “poder blando” (pedir a países que se autorregulen, algo que podrían querer cumplir simplemente para mantener buenas relaciones), etc. ↩