
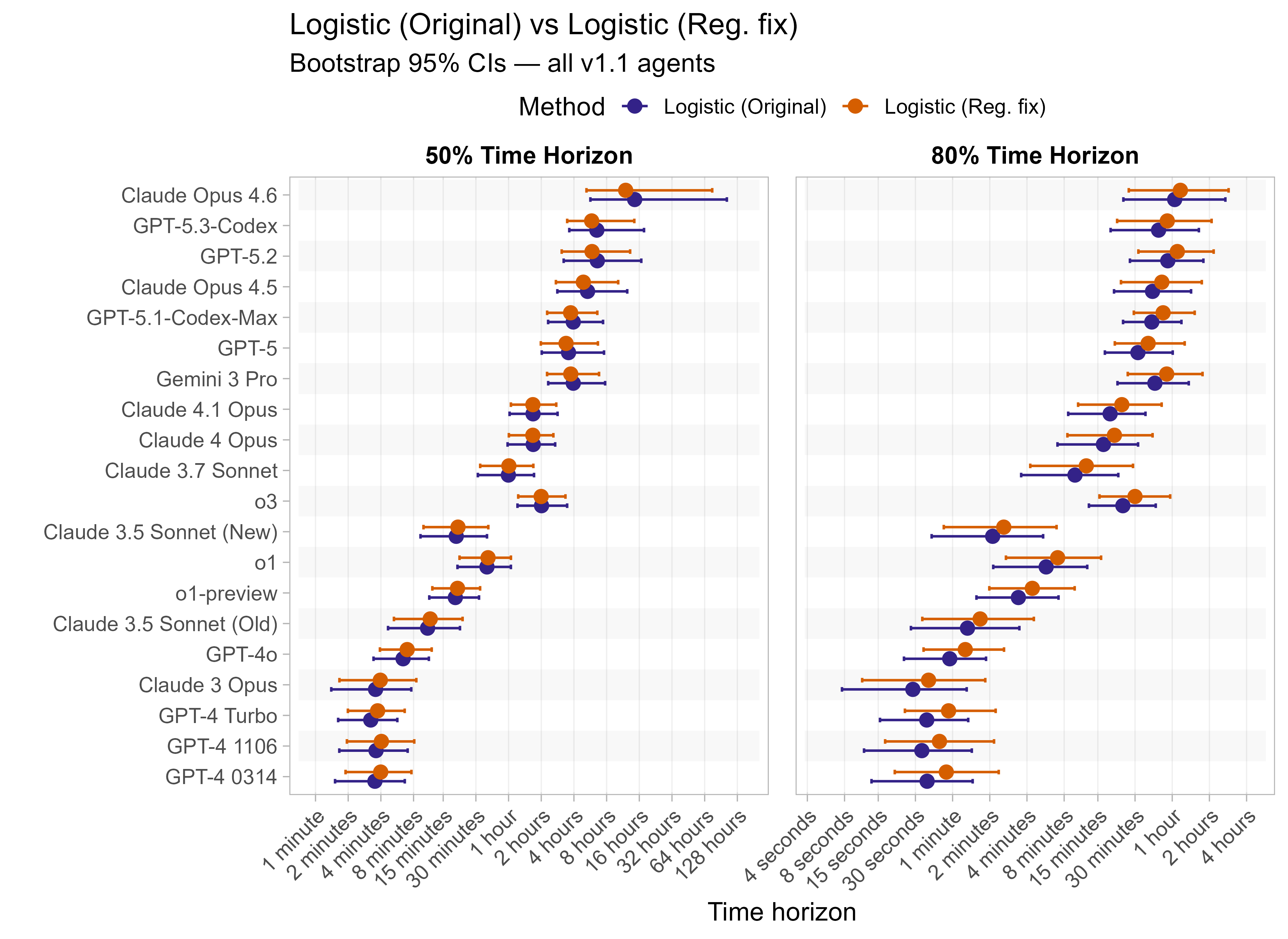
As METR’s time horizon task suite saturates, the results are becoming more sensitive to analysis choices. One example of this was the recent update to fix a modelling mistake with regularization, which decreased recent models’ 50% time horizon results by up to 20%, but had a smaller impact on earlier LLMs’ 50% time horizons.1
In this post I’ll:
- Give a refresher on the current model used to calculate time horizon results and more detail about the regularization mistake METR recently fixed
- Go over what I see as the other main sources of uncertainty in time horizon results (outside of needing more tasks). Where possible, I’ll fit alternative models to show their impacts
- Wrap things up with general thoughts on how much weight people should put on the current estimates
I hope this will help people better understand the modelling assumptions underlying the time horizon results, and how robust (or not) the results are.
Summary
- There are many reasonable variations one could make to the TH modelling, and most of these end up having the effect of reducing recent 50% time horizon estimates (and often increase 80% time horizon estimates). The aspect I feel least certain about is noise in the task length estimates, which I hope to look into more in the future.
- I find that reasonable choices generally still leave us inside the CIs (which are very wide!).
- I think the most important source of uncertainty is the task distribution rather than analysis choices, as which tasks are included has a very large impact on the results (which is accounted for in the current CIs).
- This is all separate from questions about the meaning and applicability of the time horizon metric itself, which has its own subtleties and issues, as discussed here.
See this table for an overview of the sources of uncertainty I think are most important:
| Source of Uncertainty | Description | Scale of impact |
|---|---|---|
| Task distribution | There are only ~230 tasks to cover the range from 1 second to 20+ hours, and also none of the tasks are over 30 hours long. Tasks also vary on multiple axes (topic, 'messiness' etc.) and so which types of tasks happen to be common at a certain length has a lot of influence. | Shown in current confidence intervals, often a factor of 2 in both directions. |
| Task length to success rate modelling choice | The logistic model is very sensitive to how well models perform on very easy tasks, which tends to mean it fits shallow slopes that depress 80% time horizons and increase 50% time horizons. | For recent models, reasonable alternative fits decrease the 50% time horizons by up to 35%, and increase the 80% time horizon by up to 100%. |
| Private vs public tasks | ~15% of the task suite is publicly available, the rest are private. Typically models perform similarly with or without the public tasks included. | 50% time horizons are generally similar, other than Opus 4.6 which sees a reduction of 40% when excluding public tasks, driven by high scores on RE-Bench (which seem legitimate). 80% time horizons are more impacted across models, with most recent models generally showing a decrease. |
| Noise in task lengths | There is substantial uncertainty in the human-time-to-complete values for tasks. This would be expected to generally bias the 80% time horizon values down, and also bias the 50% time horizon values up for the most capable models near the edge of the task suite. | Very hard to be sure, one approach suggests that correcting for this could reduce frontier LLM 50% time horizons by ~30%, but uncertainty is very high (cannot rule out anywhere from 0% to 60% reduction). Capping task length at 8 hours has a smaller effect, reducing 50% TH by 10-15%. 80% time horizons should perhaps increase by ~20% (but again very uncertain, hard to rule out 0-50% increase). |
| More complex modelling | There are various more complex modelling approaches one could take, but I have not yet explored thoroughly enough to present here. e.g. Allowing task difficulty for LLMs to differ from baseliner time, using Bayesian models etc. | Unclear, seem relatively unlikely to take us outside CIs. |
Refresher: The current time horizon model
- This is a quick refresher on the statistical model behind the current time horizon results. For general background or more detail see the dedicated time horizon page, the blog post, or paper.
- There is a suite of ~230 tasks from ~80 families (each containing between 1 and 20 tasks that are somewhat similar), each of which has a task-length corresponding to the time it would take a human to complete (either based on actual observed human completion times (‘baselines’) or estimated).
- Each LLM attempts each task multiple times (typically 8, although there is some variation) and the attempts are scored as binary pass/fail.
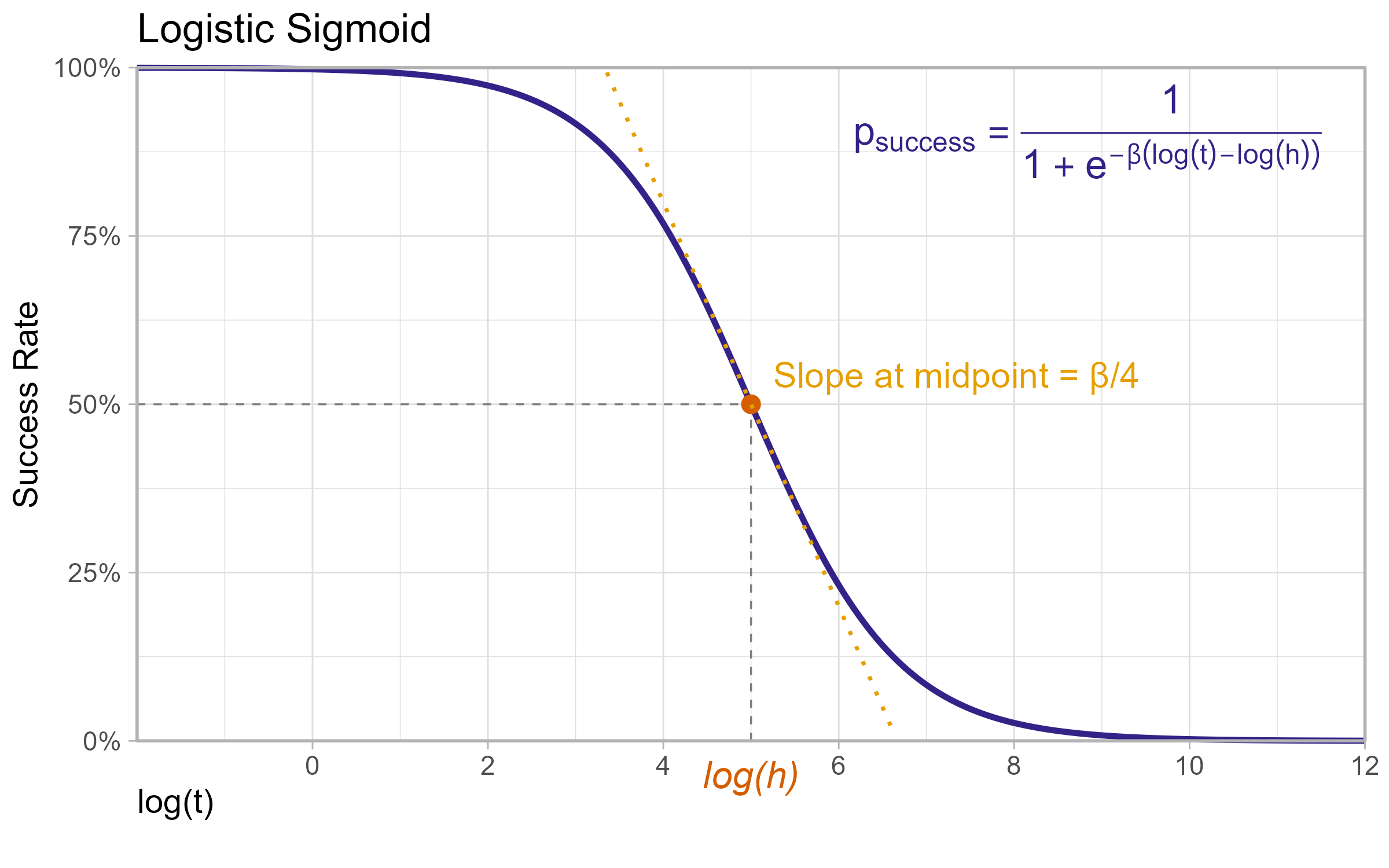
- The success rate of an LLM at a task is modelled as
where
$h$ and $\beta$ are learned parameters for each LLM where:
- $h$ gives the task-length at which an LLM is predicted to succeed 50% of the time (the 50% time horizon)
- $\beta$ is the ‘slope’ parameter which affects how quickly the LLM’s success rate changes with task length, and is used in calculating the 80% time horizon.
- The model then finds the ${h_a, \beta_a}$ parameters that maximise the log-likelihood:
where:
- $p_{a,t}$ is the estimated success probability of agent $a$ on task $t$ as given above (which depends on $h_a$ and $\beta_a$),
- $S_{a,t}$ is the observed success rate at task $t$,
- $w_{a,t}$ is the weighting given to the task-agent pair, equal to $({\text{Family Size}_t})^{-1/2}$
- The family size weighting means that families with many tasks have reduced per-task influence.
- Note this is fully separable by LLM, so the model in fact fits each LLM’s parameters independently
- Confidence intervals are constructed using a hierarchical bootstrap, over task families, then tasks, then attempts.
- This is again done independently for each LLM, and weights are recomputed for each bootstrap sample
- Once the $h_a$ and $\beta_a$ values are estimated for LLM $a$, they can be used to compute its p-time horizon (the task length such that it is predicted a success rate of $p$) for any $p$:
which gives in particular:
Note on the regularization mistake
Until it was updated on 2026/03/032, the time horizon model didn’t find the maximum likelihood estimates for $h$ and $\beta$ as described above, and instead used a penalised regression where there was an additional term:
Penalised regression: Find ${h_a, \beta_a}$ to maximise the following:
where $C$ was set to 10.
The regularization made all the curve fits slightly shallower than they would otherwise have been, but the exact impacts of this vary depending on the capability of the LLM. For weak LLMs it tends to reduce the 50% time horizon, and for strong LLMs it increases the 50% time horizon, with those in between being less impacted. It also has the effect of generally lowering 80% time horizons across all models.
Main sources of uncertainty
Finding one clear mistake in the time horizon model naturally raises concerns that there might be others that are also impacting the results. There are also various alternatives to the modelling choices that seem just as reasonable, and so it would be good to know if any of these substantially impact the results.
I’ll start this section by going over the individual areas that seem to make the most impact, then end by quickly covering everything else I looked into.
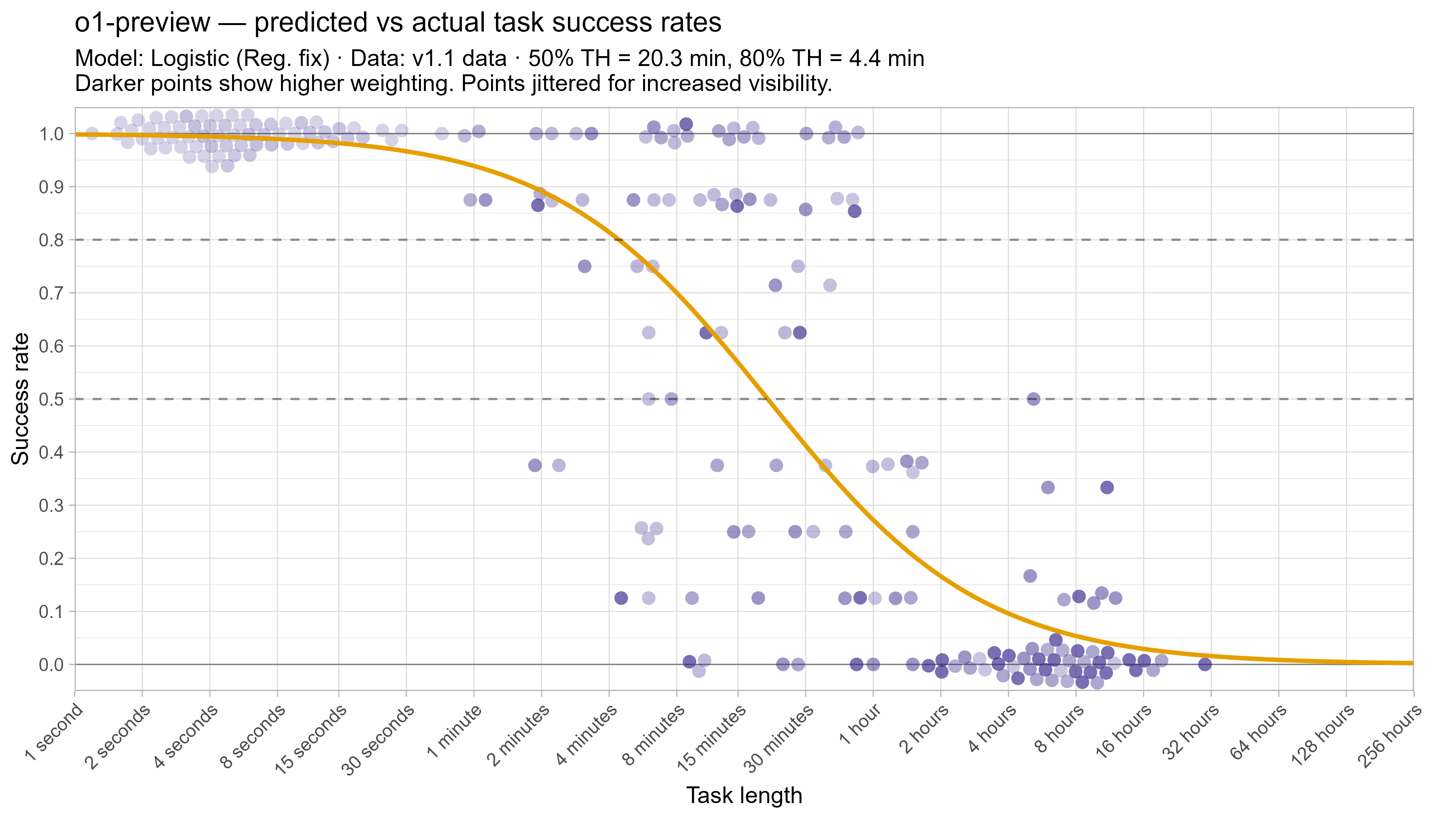
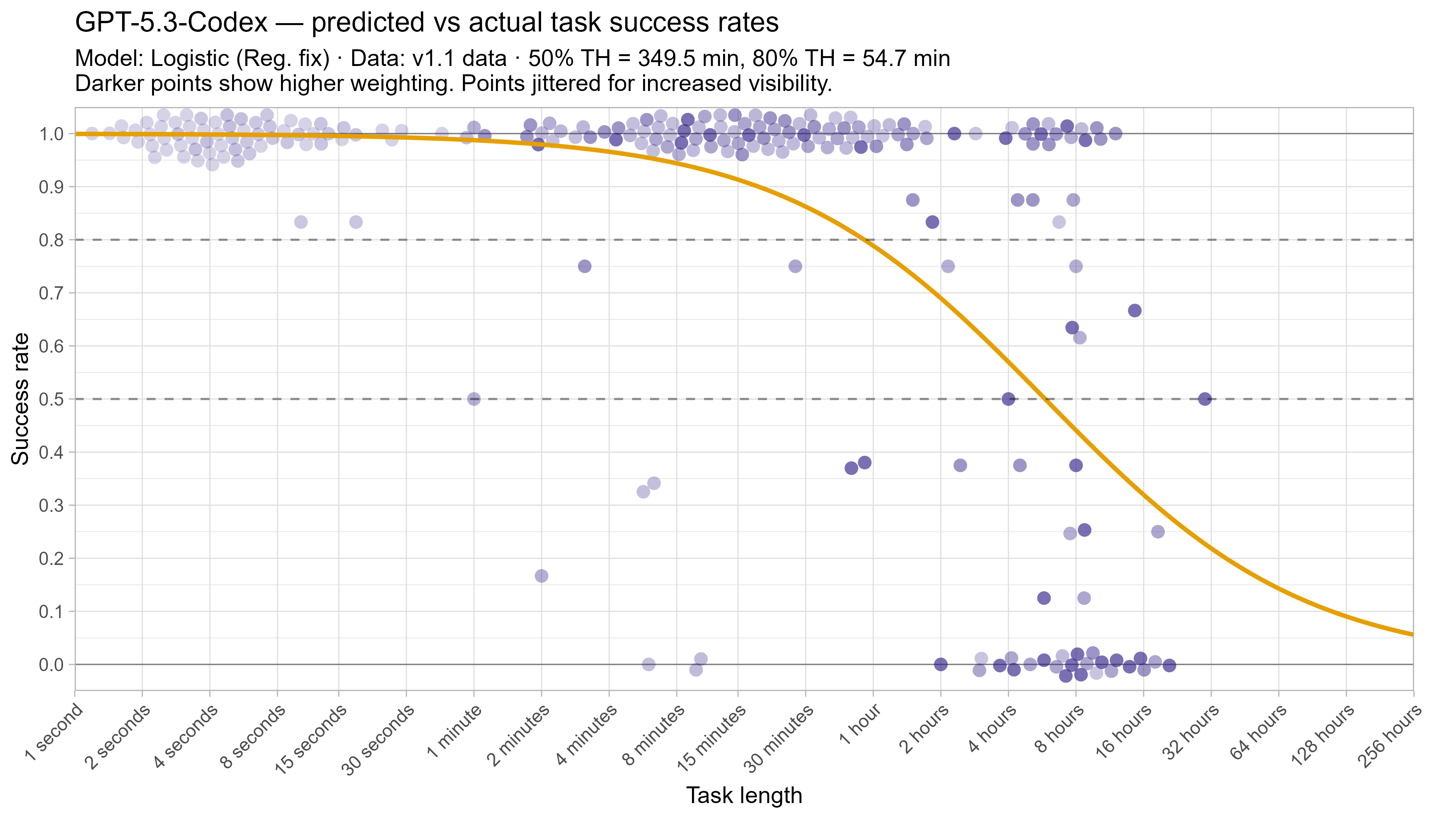
In this post I will often focus on how various changes impact Opus 4.6’s time horizons when discussing the impact of various changes. This is due to the fact that as the top-performing model by 50% time horizon as of 2026/03/20 it is closest to the end of the task suite, and so its model fit is effectively less constrained by data and more strongly influenced by modelling assumptions.
Note that one thing I don’t discuss here is uncertainty over task distribution, as this is already incorporated into the results in the existing (very substantial) bootstrapped confidence intervals, but I believe that this is the main source of uncertainty in the results.
Alternative success-rate curves
As covered above, the current model assumes that for each LLM the success rate it will have on a task follows a certain sigmoid based on the task’s length. In particular it uses the logistic sigmoid:
where $\sigma(x) := \frac{1}{1 + e^{-x}}$
which looks like this:
A notable property of this is that it has ‘thin tails’ for small task lengths, in the sense that as tasks become very short it will make extremely confident predictions that the model will succeed.
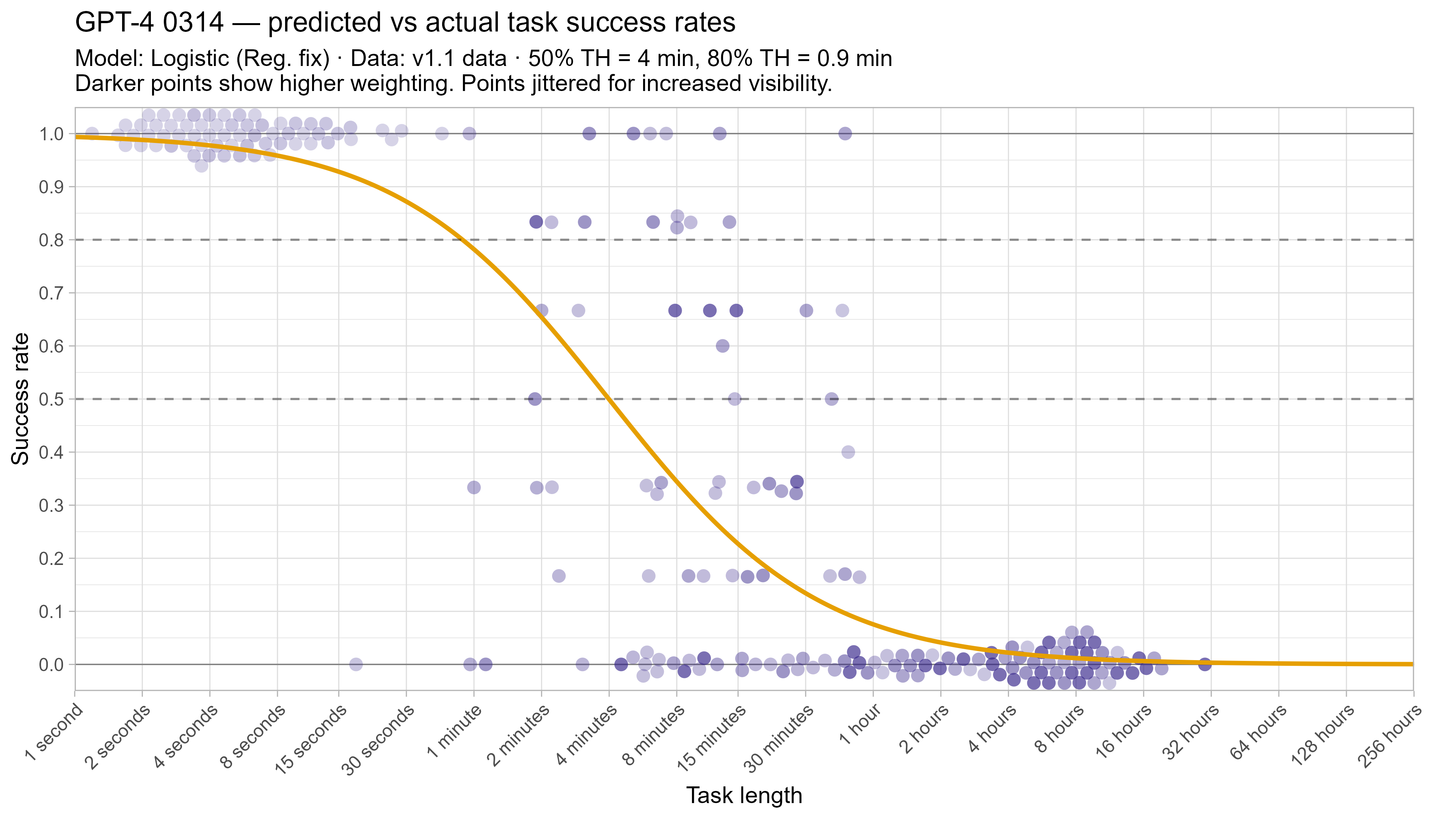
However as can be seen on the plot, this doesn’t seem to match behaviour very well, as LLMs seem to occasionally fail tasks that should be very easy, which can cause large distortions to the model.3
One way to straightforwardly see the impact of this is by fitting the model on data that has been modified to have only successes on tasks below 15 minutes. Despite this being strictly better than Opus 4.6’s actual performance, it results in the 50% time horizon decreasing from 12 hours to 9 hours due to the model being able to fit a much steeper curve without needing to worry about the very short tasks (and the 80% time horizon almost doubles to over 2 hours).4
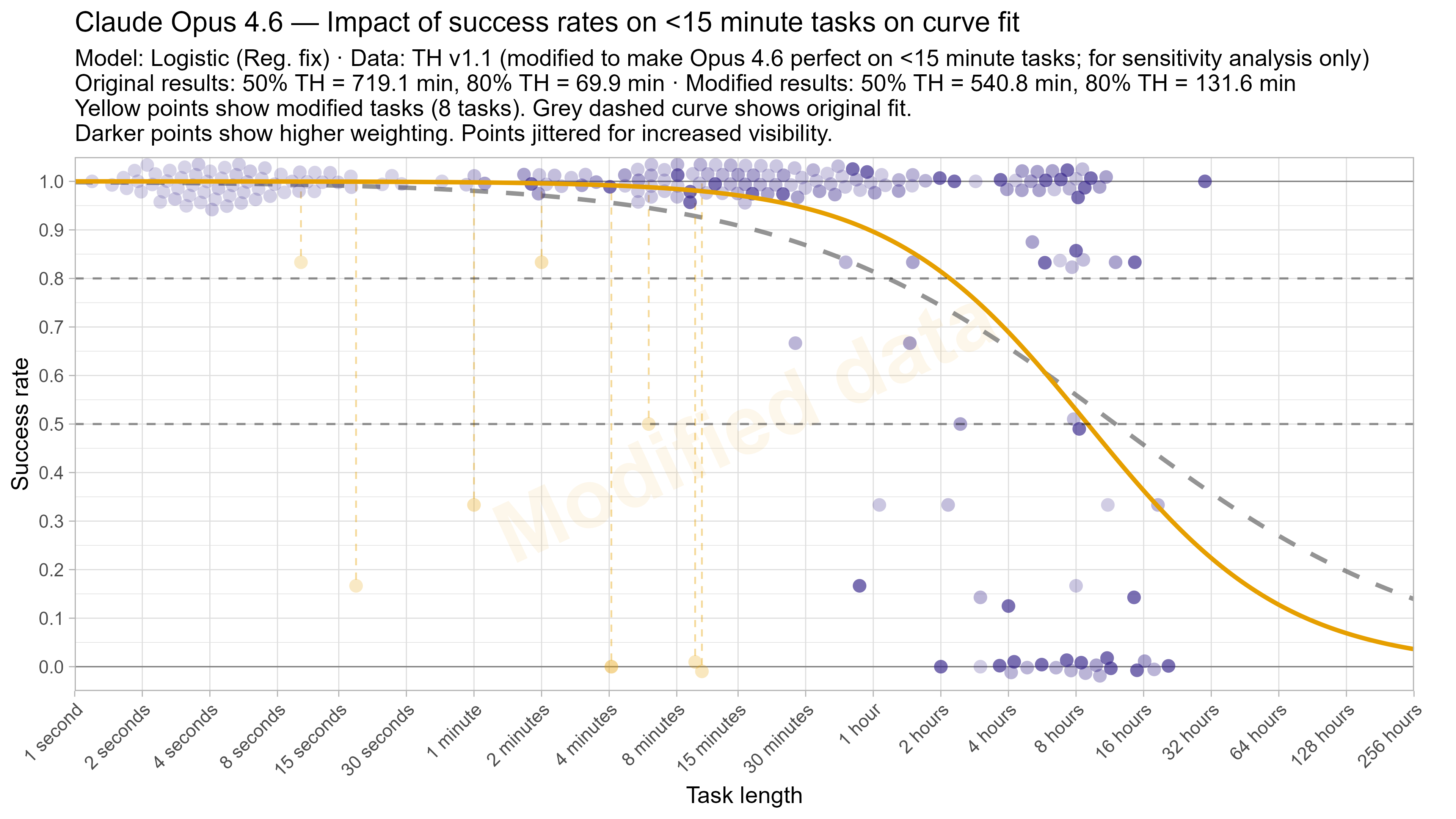
There are various ways to try and avoid this issue:
- Stop allowing the slope steepness to vary for different LLMs
- Change to sigmoids that have thicker tails for lower time values
- Change the likelihood to make it less sensitive to individual tasks
- Switch to non-parametric or least-squared based approaches
I tried various models that cover all of these (discussed in more detail below), although as the goal was to show the variety of outcomes possible from different results I did not spend substantial time on each, and it is possible some are not configured optimally or otherwise contain mistakes.
Details of the alternative models
Logistic (Fixed Slope): Instead of having each LLM learn a different slope-steepness parameter, find a single value that maximises the likelihood over all LLMs. This was based on the idea that while regularizing the slope steepness towards 0 was not well motivated, it could make sense to regularize it towards its average value. Investigating this further revealed that out-of-sample predictive performance only improved with increasing regularization strength, and so I include this as the limiting case where all LLMs have one common slope steepness.
Logistic (Reliability Ceiling): Multiply the original logistic models’ predicted success probability by 0.995, as one way of enforcing that there is always some non-trivial chance of LLMs failing at even very easy tasks. There is some research on human reliability that suggests a failure rate of 1/200 to 1/100 for trivial tasks which inspired the exact choice, but this was not carefully considered.
Beta-Binomial Logistic (Reliability Ceiling): Instead of modelling multiple attempts within the same LLM<>task pair as independent, instead assume they all draw from one common success probability that can vary somewhat from the predicted success chance. I model the success chance as a beta distribution with expected value equal to the reliability ceiling’s p_success, but with variance = p*(1-p)*0.1. By using a beta distribution for this common success probability there is a closed form solution that makes this easy to model.
Cauchy Sigmoid: Replace the logistic sigmoid with a Cauchy CDF that has extremely thick tails:
Weibull (Survival): Replace the logistic sigmoid with a Weibull Survival curve, where LLM failure at a task is treated as ‘death’ according to a Weibull survival model. See more details here, where Gus Hamilton looked into fitting exactly this model to the METR time horizon data.
Min Square Error Logistic: Fit the same logistic model as before, but instead of minimising the log-likelihood instead find parameter values to minimise the weighted square error between the predicted and observed task success rates. This substantially reduces the influence of probabilities near zero or one.
Min Square Error Cauchy: The same as the above, but using the Cauchy CDF instead of the logistic sigmoid.
Non-parametric approaches:
Local Linear (LOESS): Fit locally linear polynomial regression, with half the data included for each point (span=0.5) weighted to have more influence the closer they are to the point being fit (tricube kernel). Note this is not constrained to be decreasing.
Monotone Spline: Fit a monotone spline to minimise the square error, using 15 knots and B-splines as a basis.
Isotonic (PAVA): Fit a monotonic sequence of linear functions that minimizes the weighted squared errors.
Rolling Average (+-2x time): Just take a simple rolling average success rate over all tasks that are within a factor of two. Note this is not constrained to be decreasing.
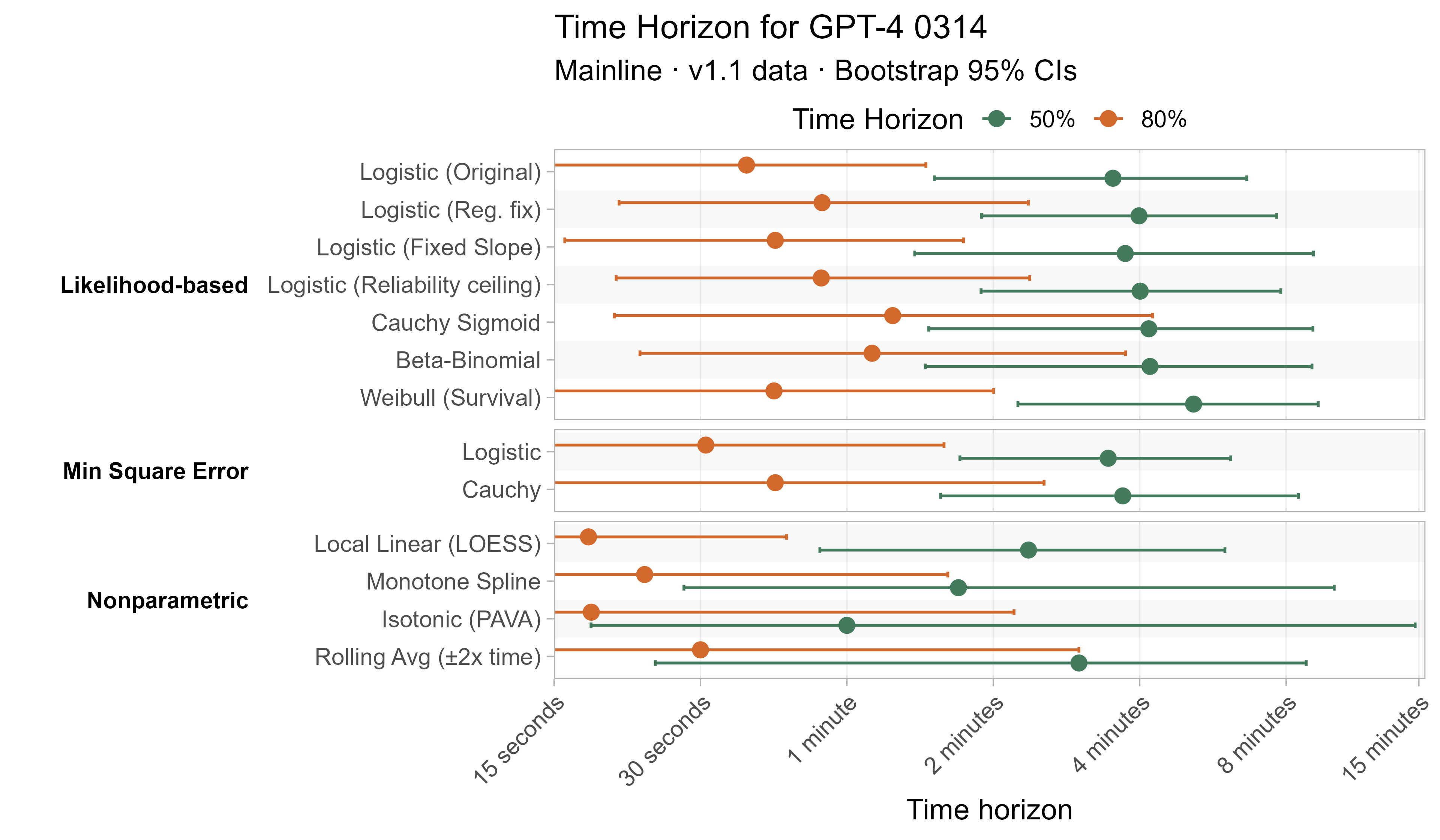
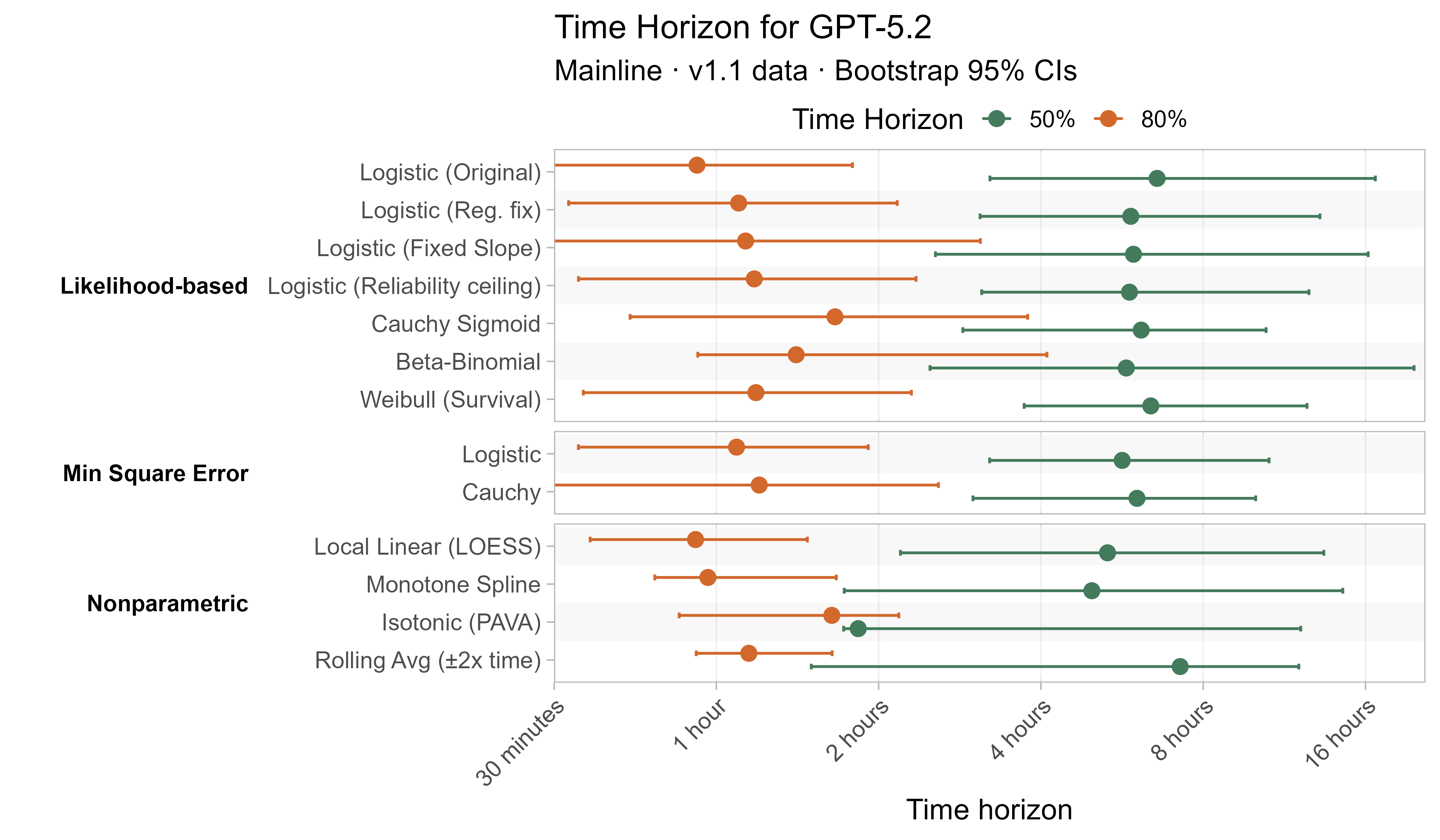
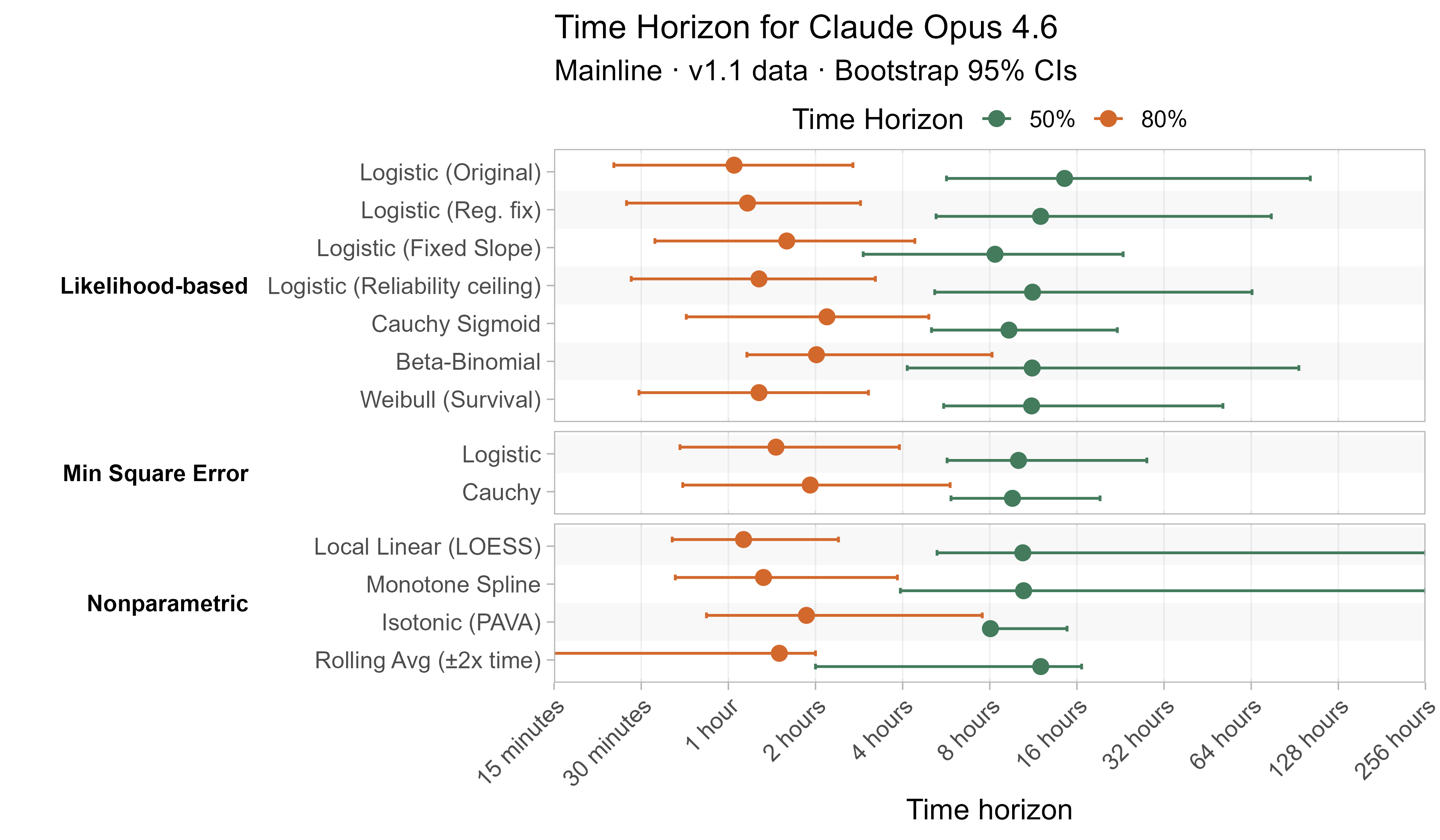
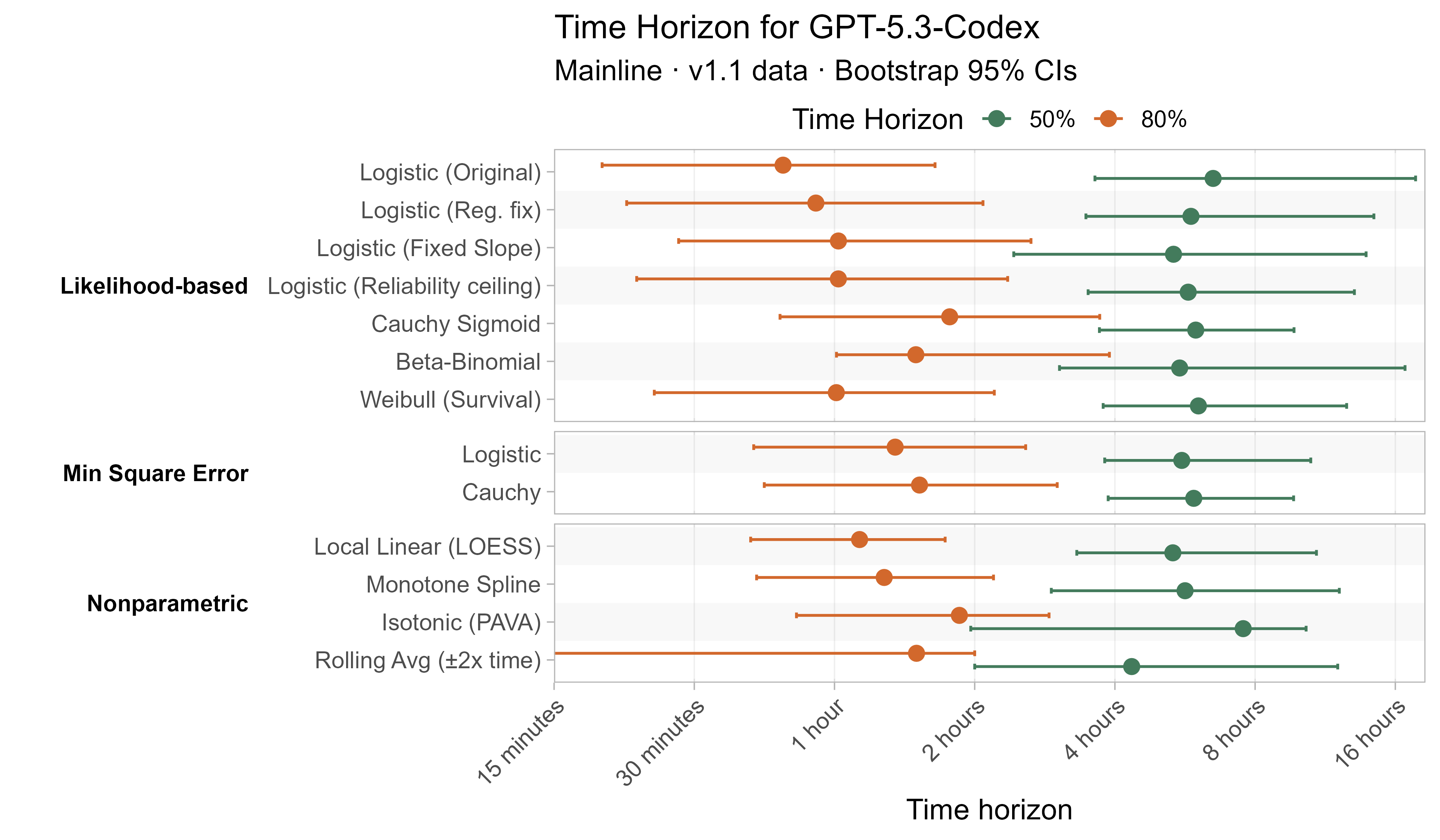
Here are the results for all the different approaches for Opus 4.6 (shown as it is most sensitive to the curve choices due to being closest to the edge of the task suite):
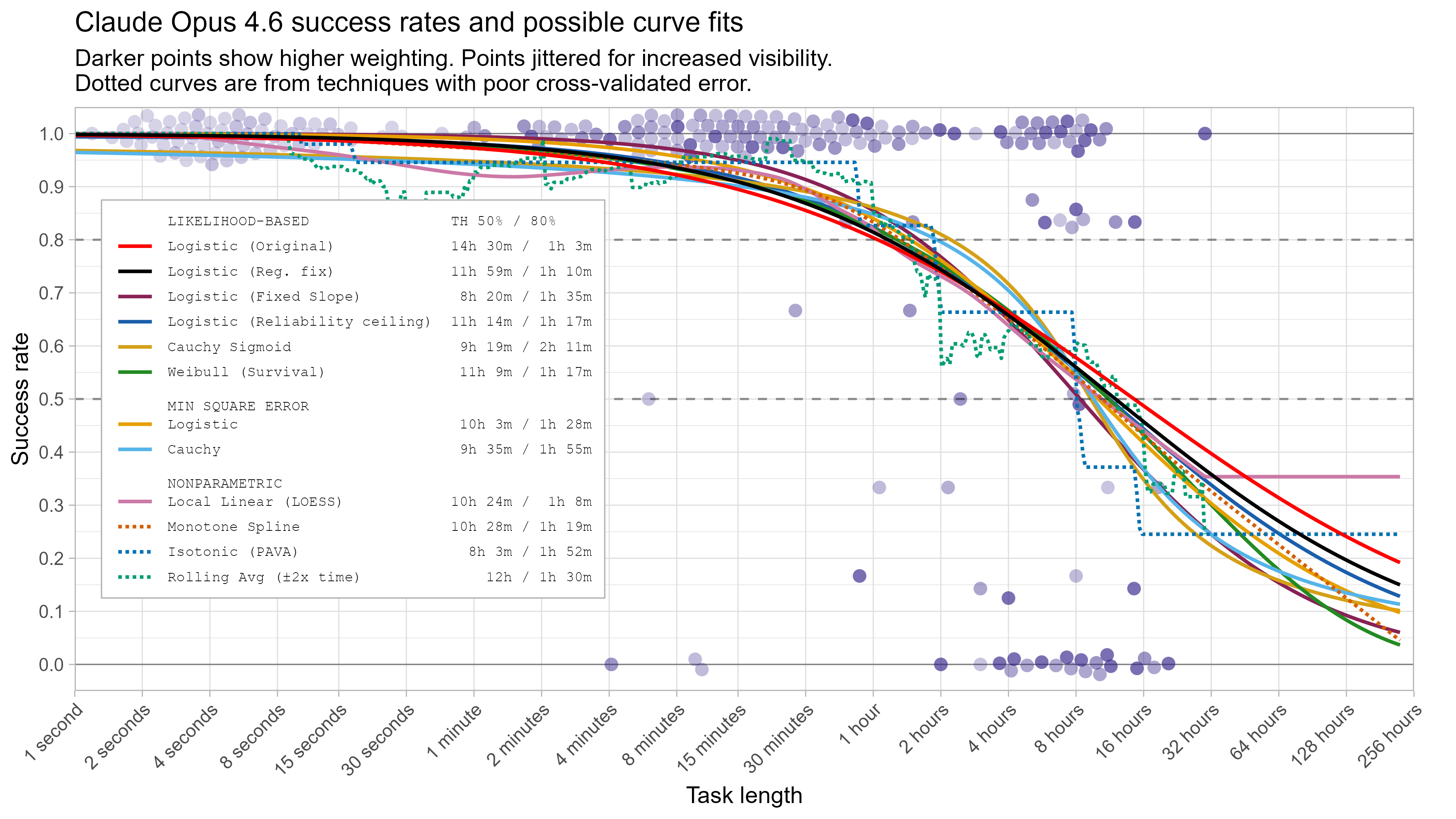
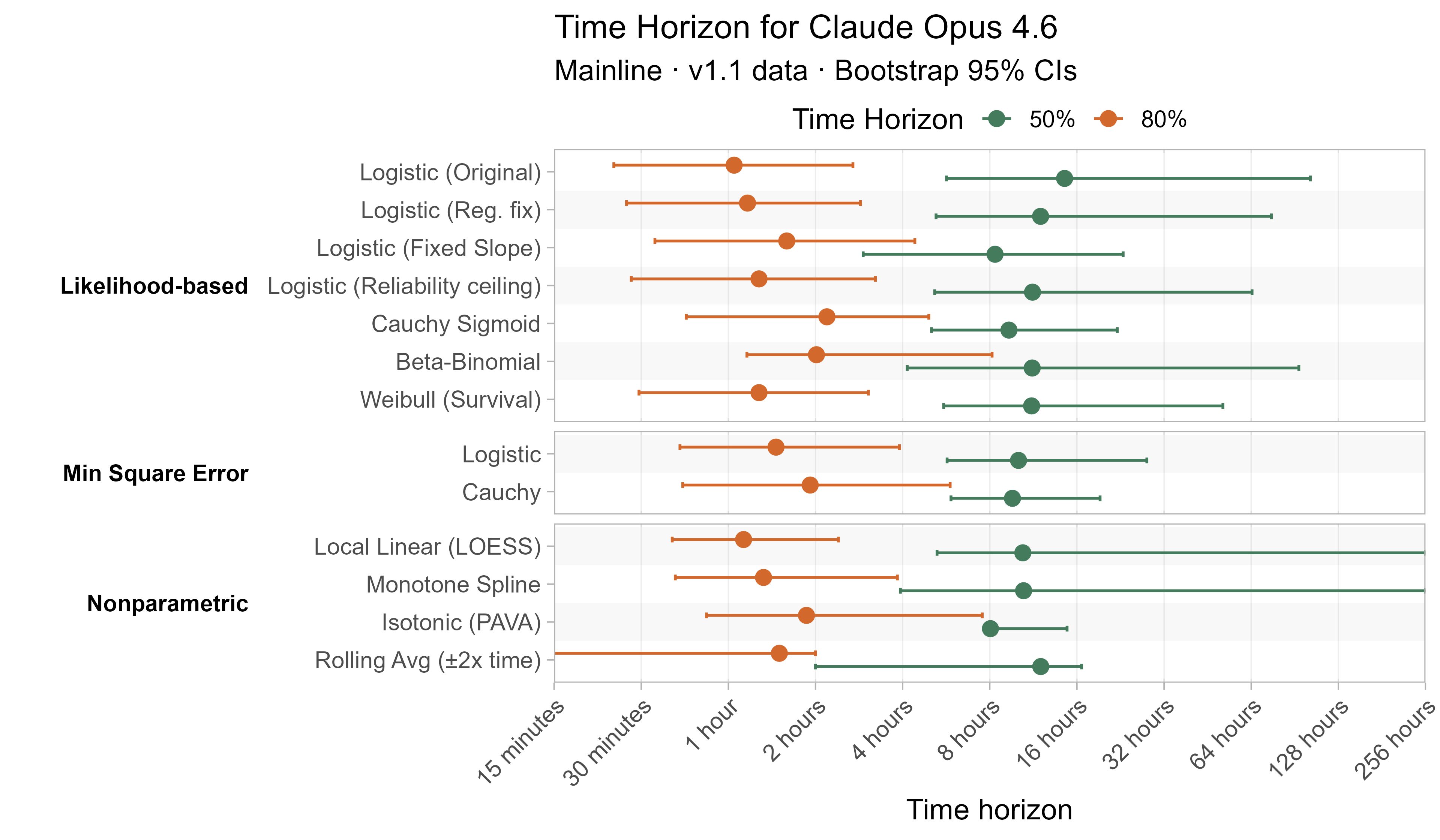
The variation in the results from reasonable methods is ~1.5x in 50% TH and 2x in 80% TH for Opus 4.6. Other LLMs are generally impacted less — see the full results in the appendix of this post.
A natural question when considering these alternative modelling approaches is how well they fit the data compared to the current model. One approach for assessing this is to look at cross-validated error, a way of assessing how well they fit on unseen data:
How the cross-validated error is constructed
- I construct “Leave-one-family-out” (LOFO) cross validated error by:
- For each task family<>LLM pair (e.g. ChatGPT 5 and HCAST/hypothesis_testing) fit a model without any of the attempts from that LLM on any of the tasks in the family
- Use the newly fit model to make predictions about how well the LLM will do on each task in the family
- Evaluate these against the held-out data, using both MSE and BCE/likelihood
- Repeat across all families, weighting by sqrt(family_size) when combining the results together as in the main model fit
- Leaving out families instead of tasks is motivated by the fact that tasks within the same family can be very similar to each other, and so I don’t want them to unduly leak information about the held-out tasks.
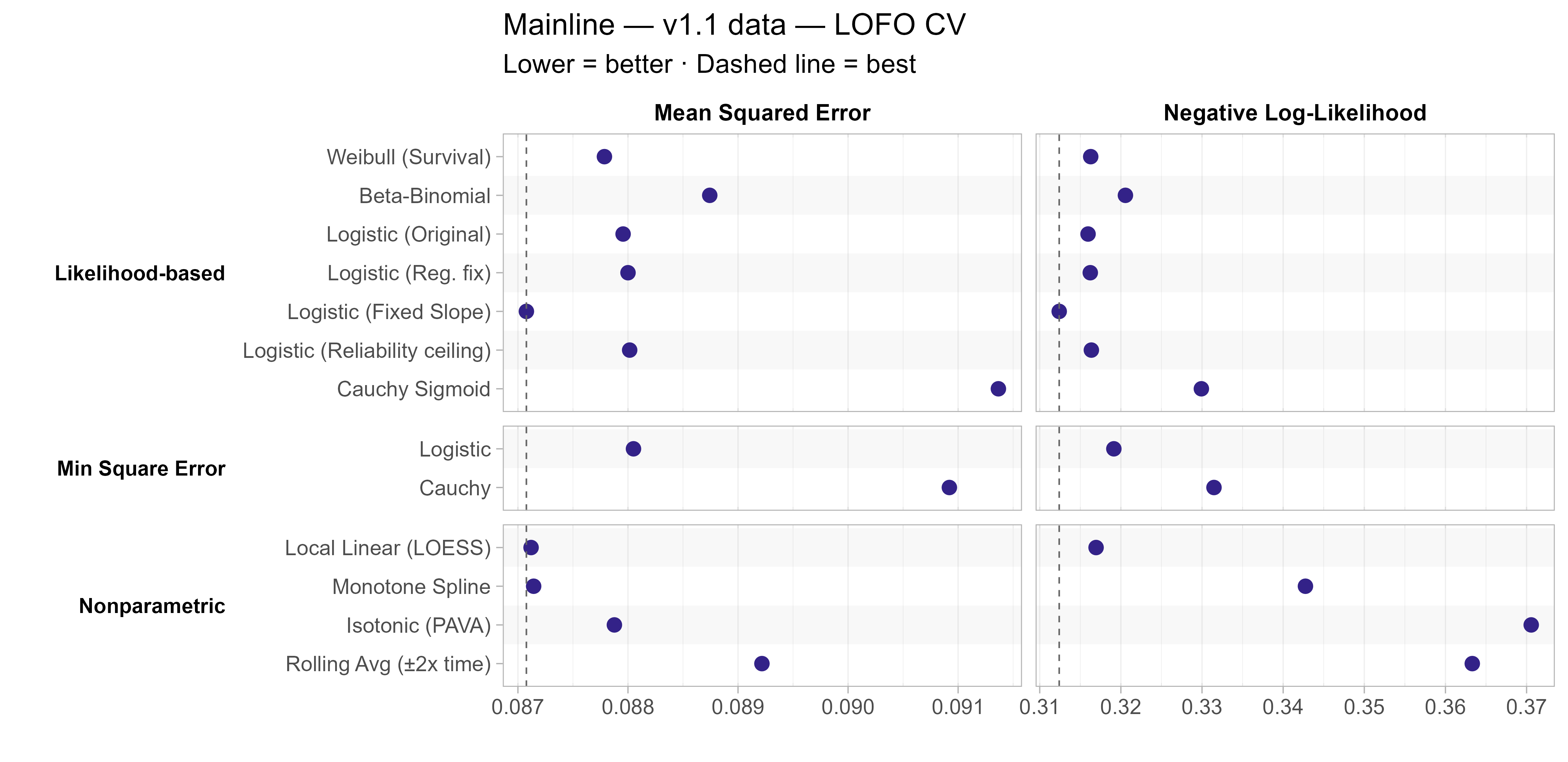
The most notable result here is that the fixed-slope logistic model performs the best on both metrics, suggesting that the additional noise introduced in estimating a slope for each LLM is not worth it. Otherwise LOESS, Weibull, and most of the logistic fits (original, regularization fix, and reliability ceiling) also all did similarly well.
Private vs public tasks
Most of the tasks in the time horizon task suite are private, in the sense that neither the task prompts nor the solutions are publicly available. However public statements and solutions are available for 1/66 SWAA tasks, 28/157 HCAST tasks, and all 5/5 RE-Bench tasks within the 1.1 task suite (although in all these cases the public listing includes a request not to train on the examples).
One would hope that the time horizon results for models would not be heavily impacted by only using the results from the private tasks, so I checked this:
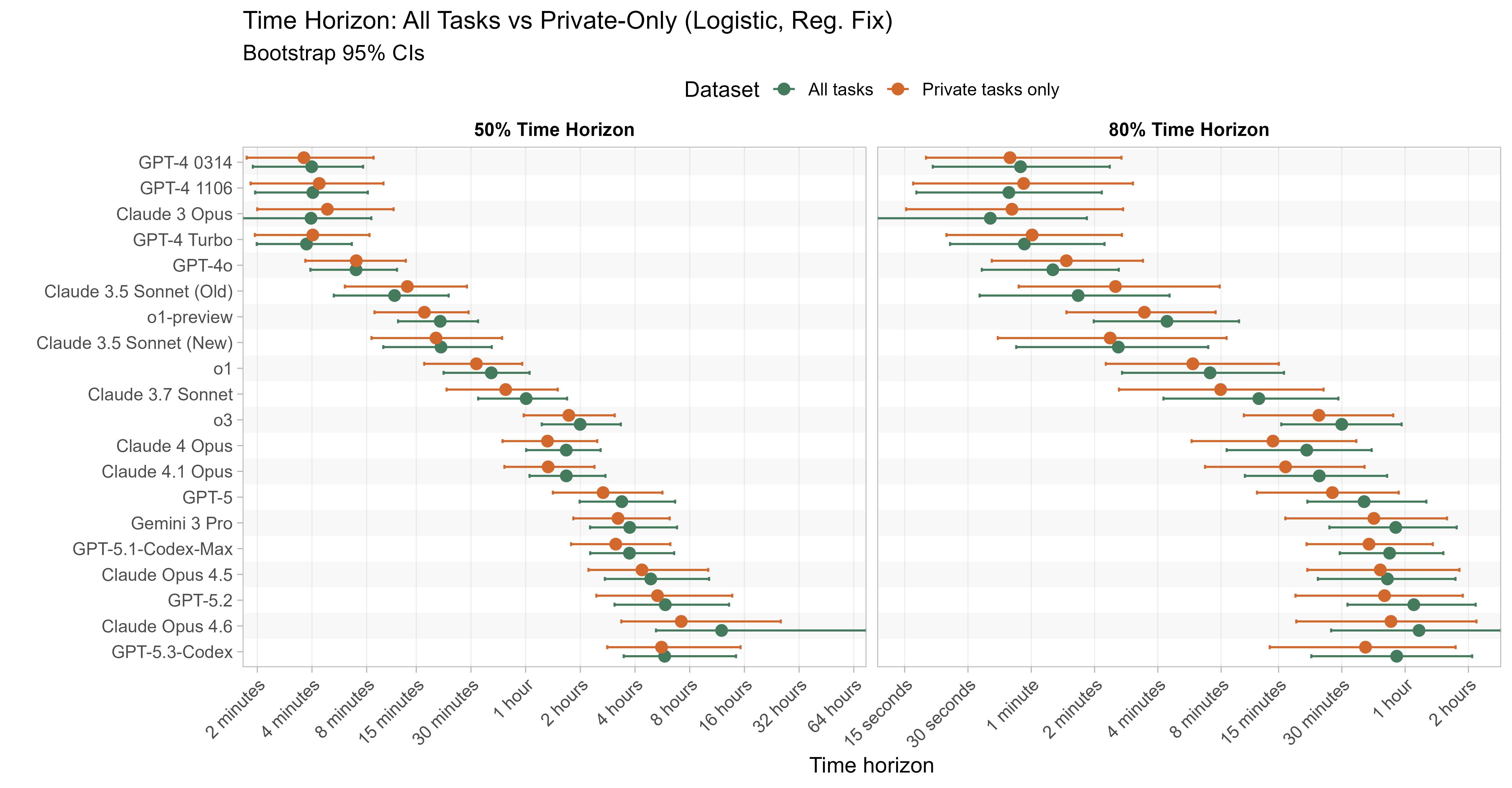
Generally results are within 5-10% for 50% TH, with models sometimes performing better or worse on the private only tasks, but Opus 4.6 in particular sees a 40% decrease in 50% TH on the private-only tasks to 7h 11m (from 11h 59m). For 80% time horizons there are generally bigger deviations, with many recent models performing somewhat worse when removing the public tasks.
Comparing Opus 4.6 to Opus 4.5 on the public tasks where 4.5 didn’t already get 100% shows that this is almost entirely driven by RE-Bench tasks:
| Public tasks where Opus 4.5 doesn't get 100%: | Opus 4.5 observed success rate | Opus 4.6 observed success rate |
|---|---|---|
| (HCAST) local_research/which_does_worse | 0% | 0% |
| (HCAST) symbolic_regression/level_2 | 0% | 83% |
| (RE-Bench) ai_rd_nanogpt_chat_rl/main | 0% | 100% |
| (RE-Bench) ai_rd_rust_codecontests_inference/main | 25% | 100% |
| (RE-Bench) ai_rd_small_scaling_law/main | 25% | 86% |
| (RE-Bench) ai_rd_fix_embedding/main | 50% | 100% |
We asked Anthropic about this and they said they did not train on any of the public tasks from the task suite.5 The RE-Bench tasks are optimisation-focused, and Opus 4.6 seems to perform particularly well on this type of task generally (see e.g. its performance on the optimisation-shaped AI R&D tasks discussed on page 184 of its model card).
Given this, I suspect that this just illustrates the impact small numbers of tasks can have on a model’s time horizon results, and the inherent noisiness this introduces. Nevertheless, as only using private tasks would have been a reasonable modelling approach, I wanted to include these results for completeness.
Noisy task length estimates
One important source of uncertainty currently not included in the model is noise in the estimates of task length.
To estimate the lengths of tasks, either one or more baseliners complete them under timed conditions, and then the geometric mean is taken of their times, or if no baseliner times are available (either because nobody was asked/chose to baseline the task, or because nobody successfully completed it) then a researcher, potentially consulting an expert, estimates the task’s length instead.
Measuring the noise in the task lengths
- To measure the noisiness of baselines, I fit a model where baseliner attempts are equal to the ‘true’ task lengths (unknown, estimated by the geomean of the baseliner times) multiplied by lognormally distributed independent noise (with one global variance parameter). I then use the tasks with multiple successful baseliner attempts to estimate the level of this noise.
- This model fits the data reasonably well, with passable QQ plots, no clear heteroskedasticity etc.
- To measure the noisiness of the estimates, I take a similar approach, but using the tasks where there is both an estimated task length (which was created first) and successful baseliner times, to act as a source of truth.
My analysis suggests 80% of individual baseliner attempts are within ~3x of the ‘true’ task length (but taking the geomean of multiple attempts decreases the noise) and 80% of estimates are within 4x of the ‘true’ task length.
This is quite a lot of noise! And in particular this likely means that most of the longest tasks are overestimates (since if you look at extreme values in noisy data, they are likely to be exaggerated), and this likely causes the model to systematically overestimate 50% time horizon values at the high end. Separately this noise would cause the model to underestimate 80% time horizon values in general, as it is more sensitive to longer tasks being underestimated than the reverse.
It is hard to tell how much of an impact this has, as I cannot ‘unnoise’ the task length estimates to see what the results would be with the true values. I’ll explore two different approaches to estimate the impact.
Capping Task Lengths
One very simple approach is to cap the task lengths at some maximum value (lowering any task lengths that are above this to the cap). I think there are good reasons to think that several tasks have ‘true length’ >= 8 hours, so I use that as the conservative maximum value here (although there might still be tasks that e.g. have ‘true length’ 2 hours but have estimated length 6 hours, so this isn’t a strictly conservative estimate).
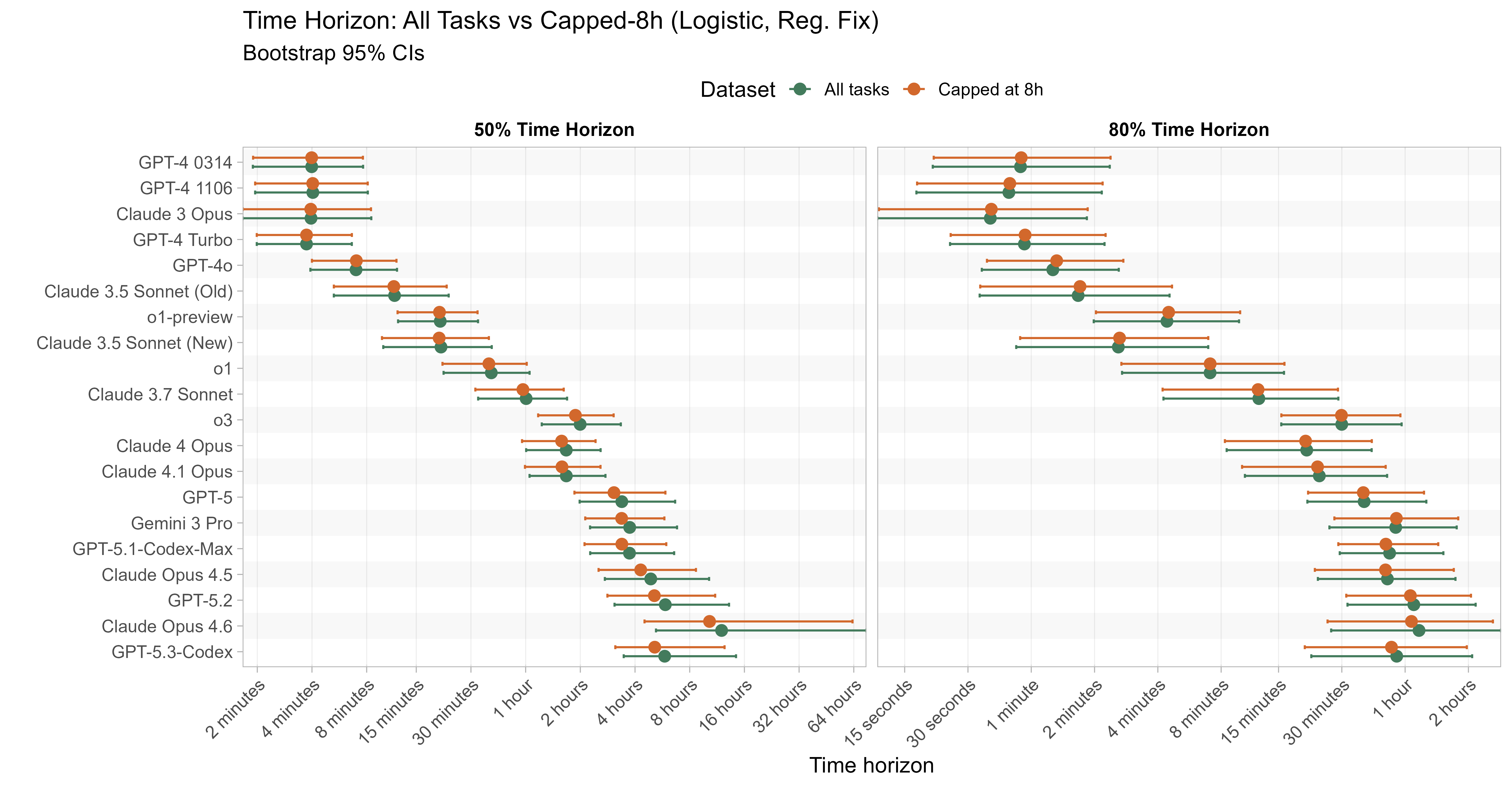
This gives moderate reductions in recent 50% time horizon estimates, with recent models seeing a 10-15% reduction in 50% time horizons, but older models and 80% time horizons being less affected. I’d expect reducing task lengths to mechanically reduce the estimated time horizons in any case, and so the fact that the 50% time horizon remains above 8 hours for some models indicates that the long TH aren’t being driven by egregious overestimates of long tasks.
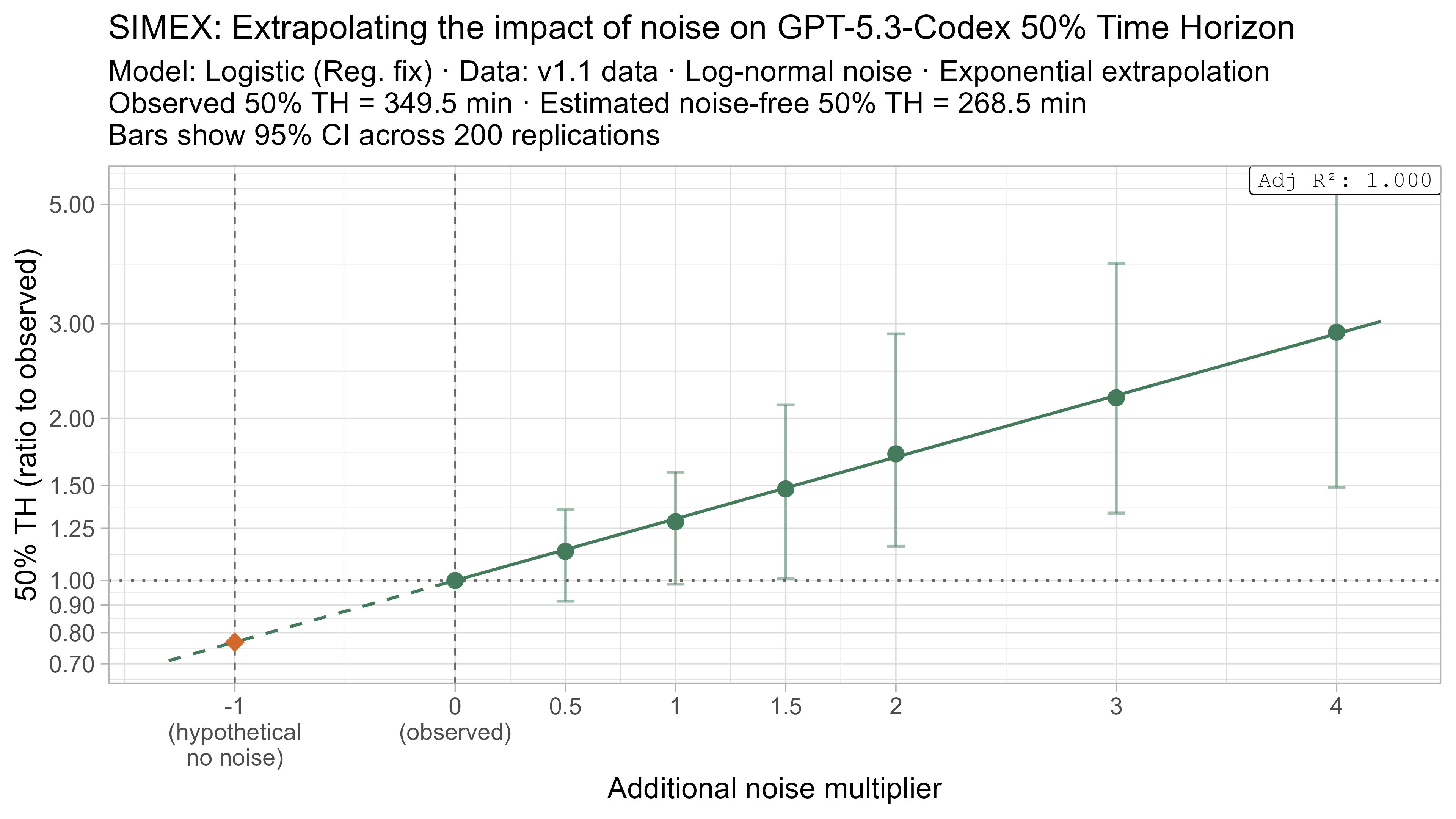
SIMEX
SIMEX (‘SIMulate and EXtrapolate’) is a two step approach for estimating the impact of noise in data where I:
- Simulate adding more noise to the data, and fit the TH model on these noised datasets
- Model the relationship between the additional noise and the resulting TH values and attempt to extrapolate this back to what the value would have been with “noiseless” data
This technique will always have very substantial uncertainty as it fundamentally relies on extrapolating a trend beyond the regime where there is data (from the ‘adding noise’ regime to the ‘subtracting noise’ regime), but nevertheless it gives some additional insight as to the plausible scale of the impact.
Technical detail on SIMEX implementation
- To use SIMEX you need to already know the level of noise in your data and the form it takes.
- From looking at the noise in tasks where there are multiple baseliner times and both estimated task lengths and baseliner times, I chose to model the task-length noise as:
- For tasks with $n$ successful baseliner attempts: multiplicative noise with distribution $\text{lognormal}(0, 0.78^2/n)$
- For tasks with estimated task lengths: multiplicative noise with distribution $\text{lognormal}(0, 1.05^2)$
- I model SWAA tasks as having no noise, as they were baselined in a different way, and make essentially no impact to the outcomes of interest.
- For each level of additional noise, $\lambda$, I then create 200 noised datasets with noise distributions:
- Baselined task lengths: $\text{lognormal}(\text{original_task_length}, \lambda \cdot 0.78^2/n)$
- Estimated task lengths: $\text{lognormal}(\text{original_task_length}, \lambda \cdot 1.05^2)$
- SWAA task lengths are unchanged
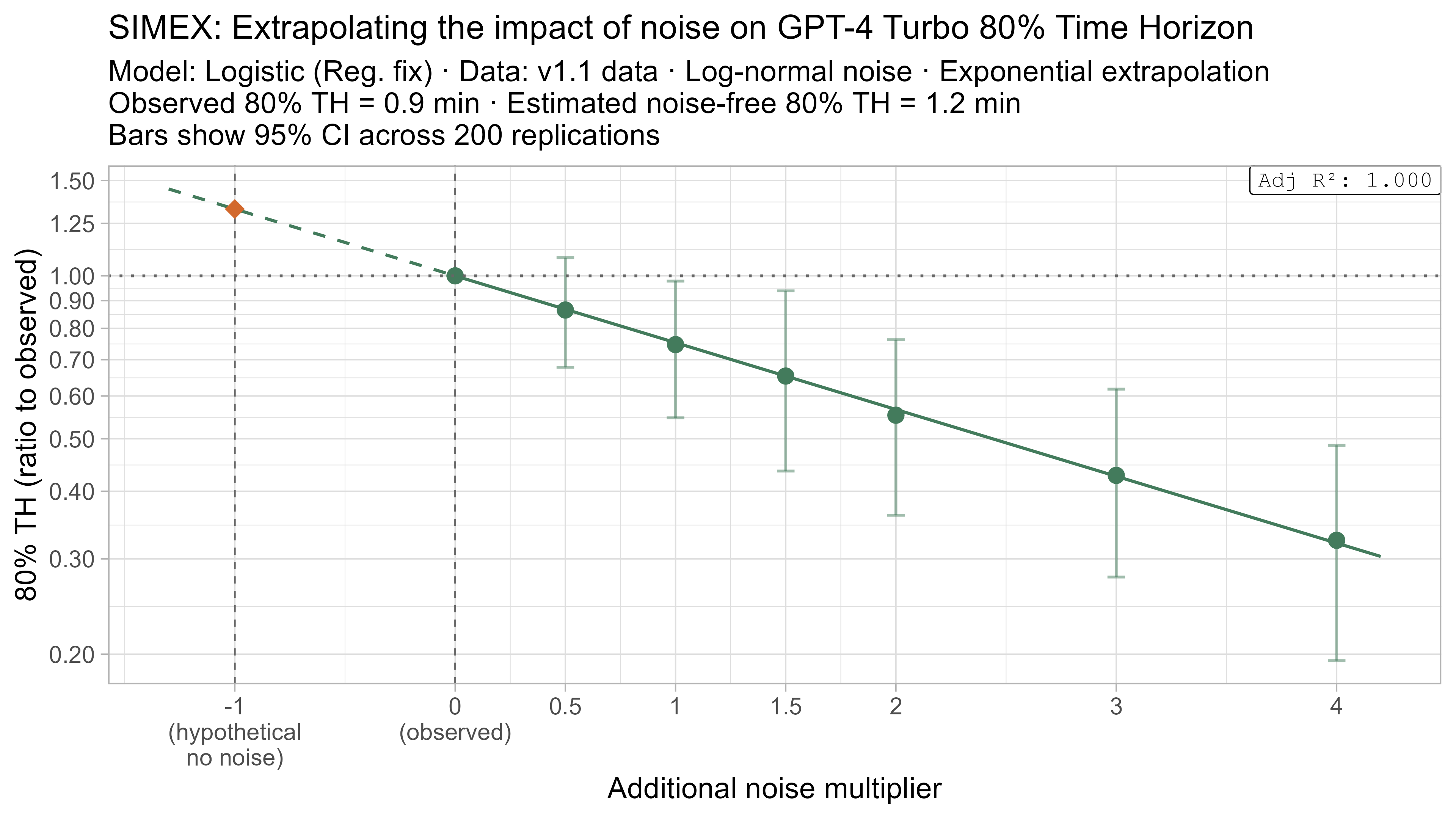
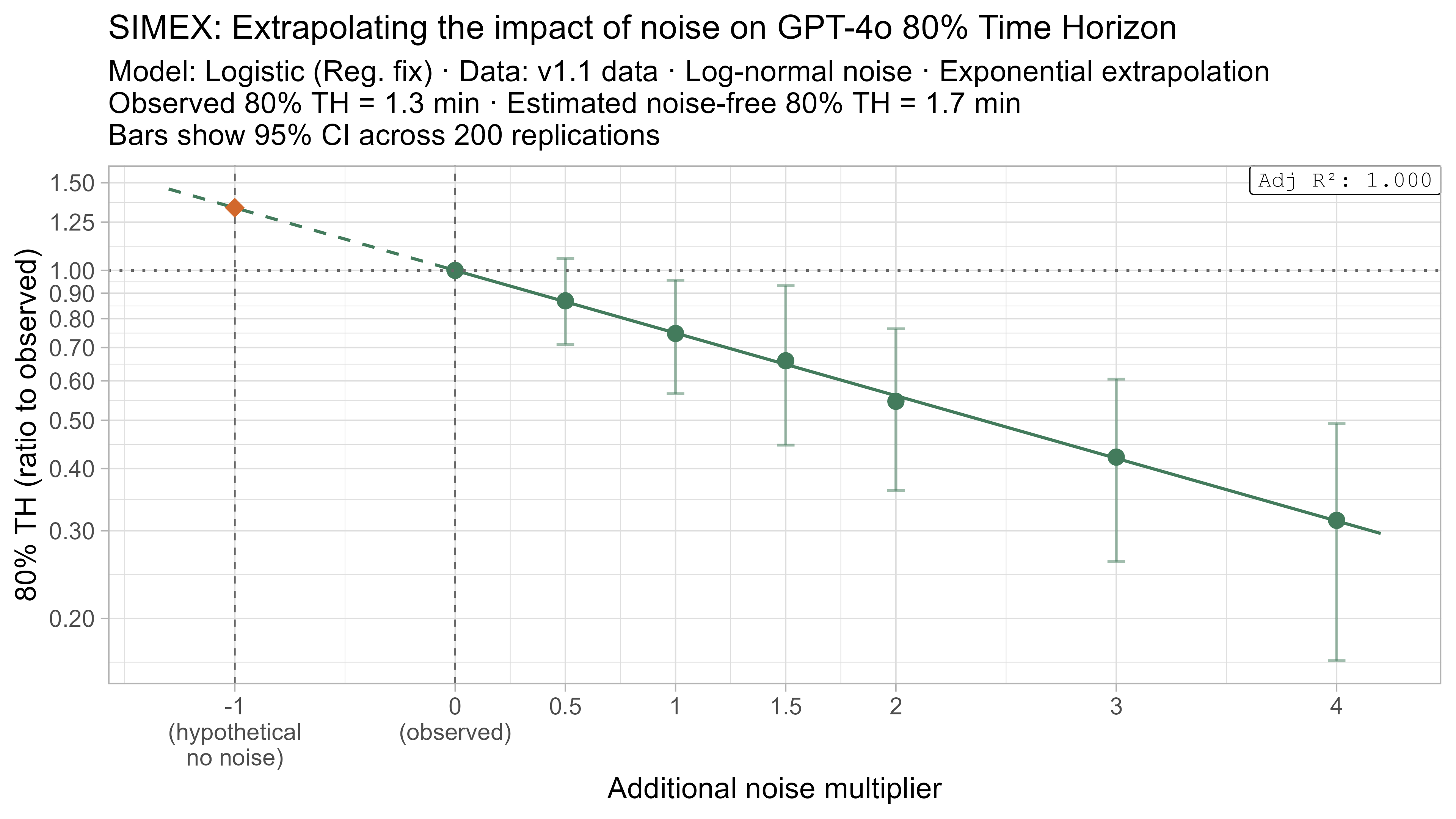
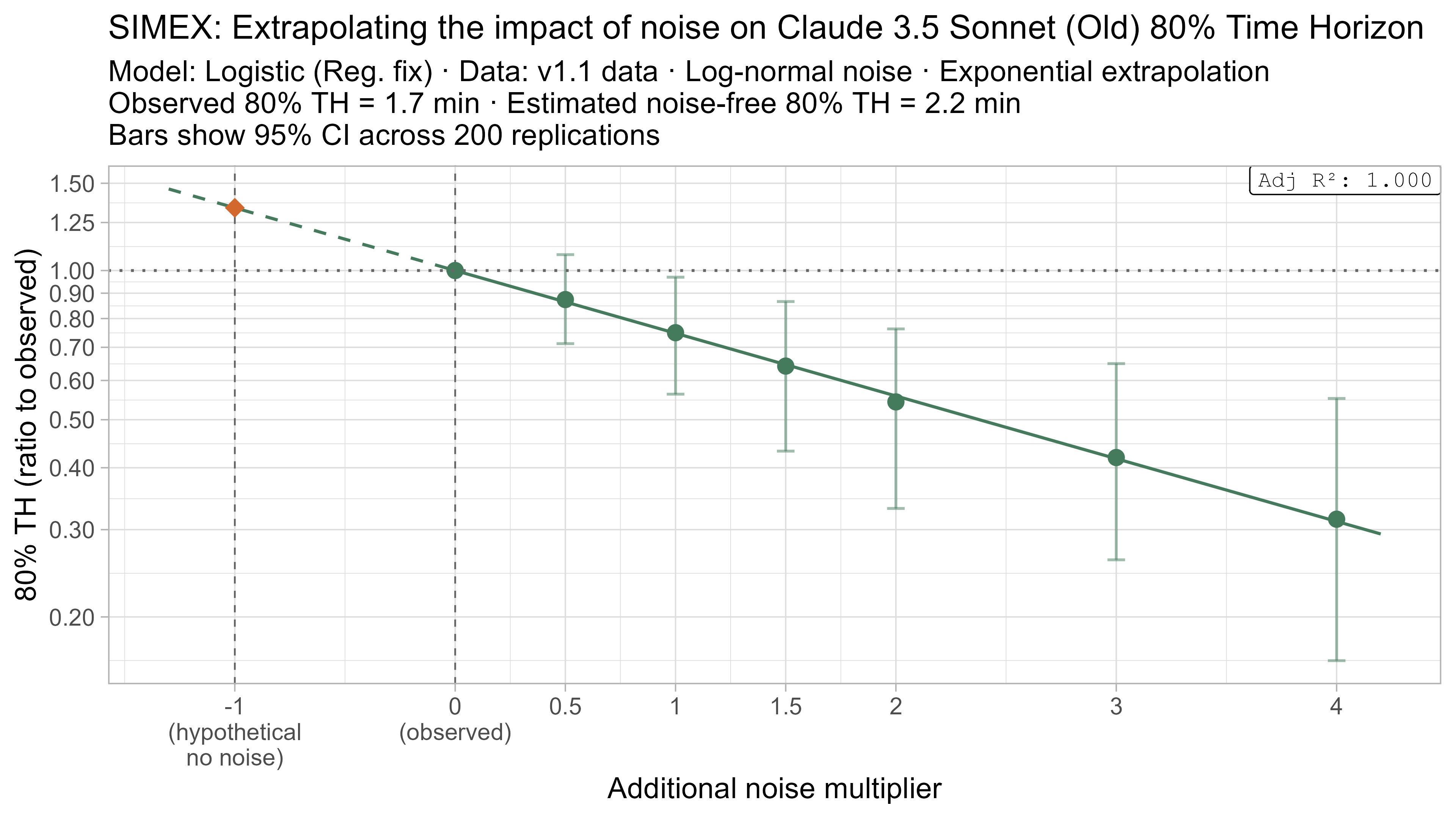
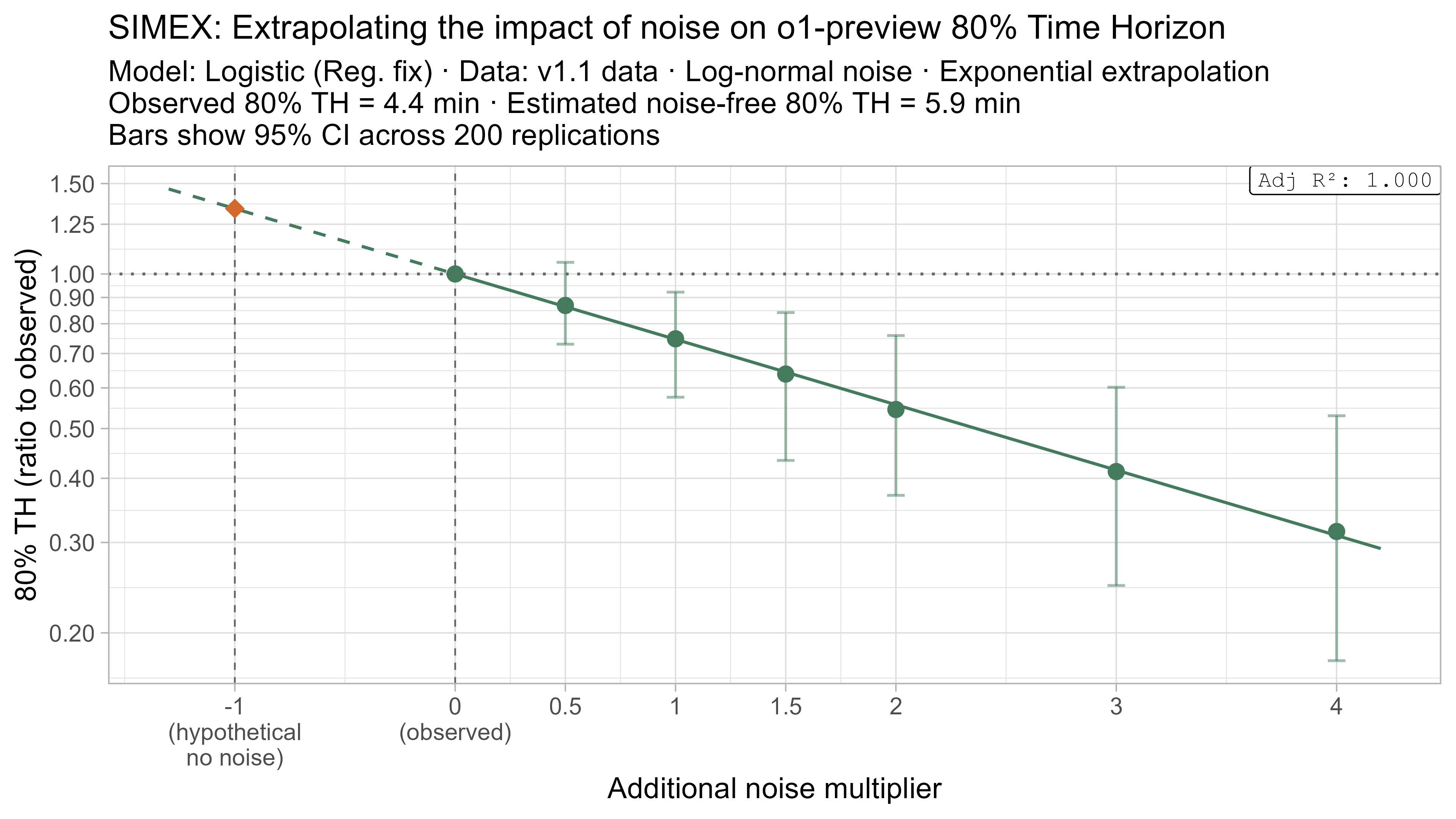
- Fit a regression of the form $\text{lambda_noised_TH} / \text{observed_TH} = \exp(\beta \cdot \lambda)$, and solve for $\beta$
- Estimate the ‘noise-free’ time horizon as $\text{observed_TH} \cdot \exp(-\beta)$
- This is just plugging $\lambda = -1$ into the equation above
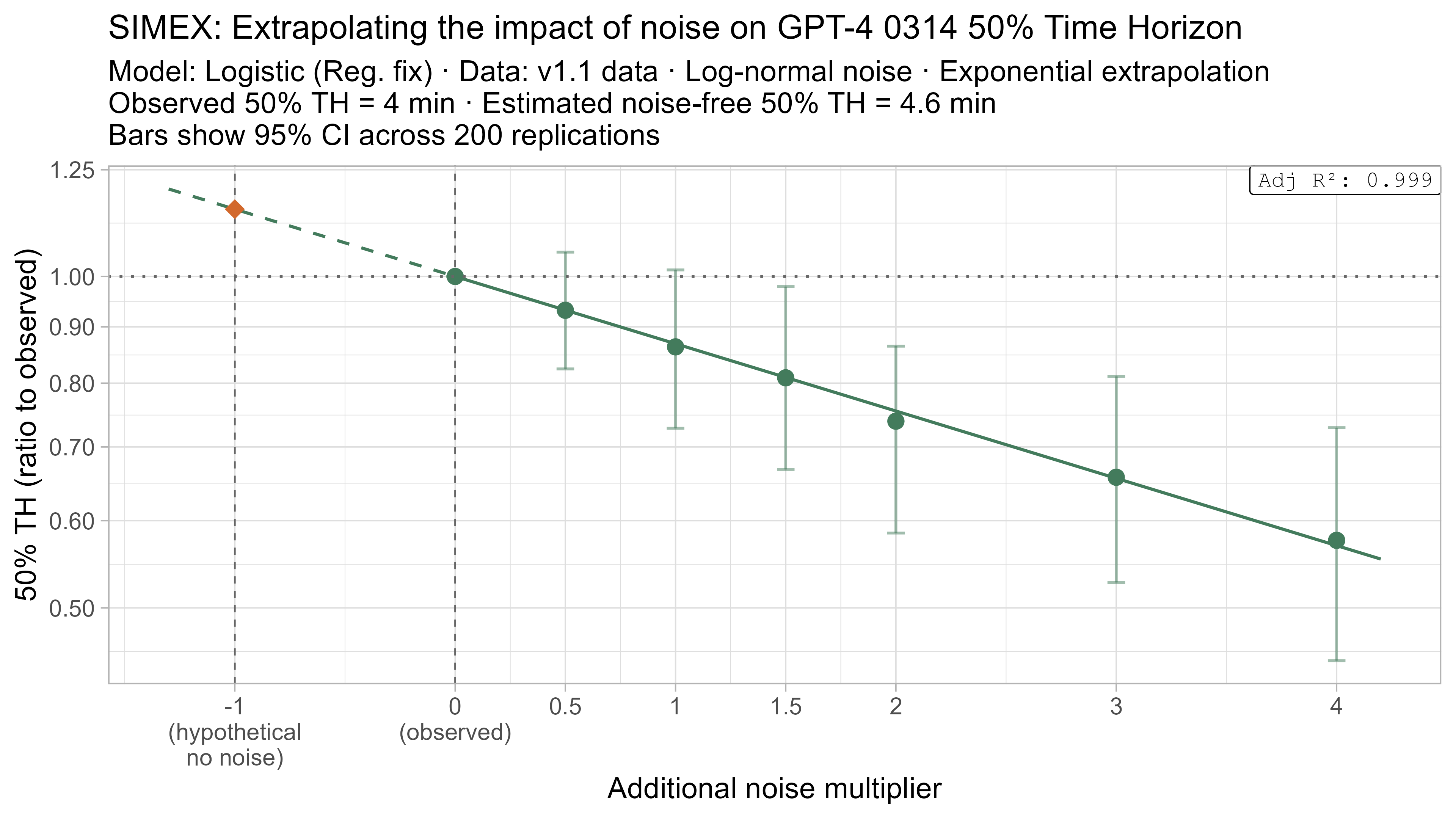
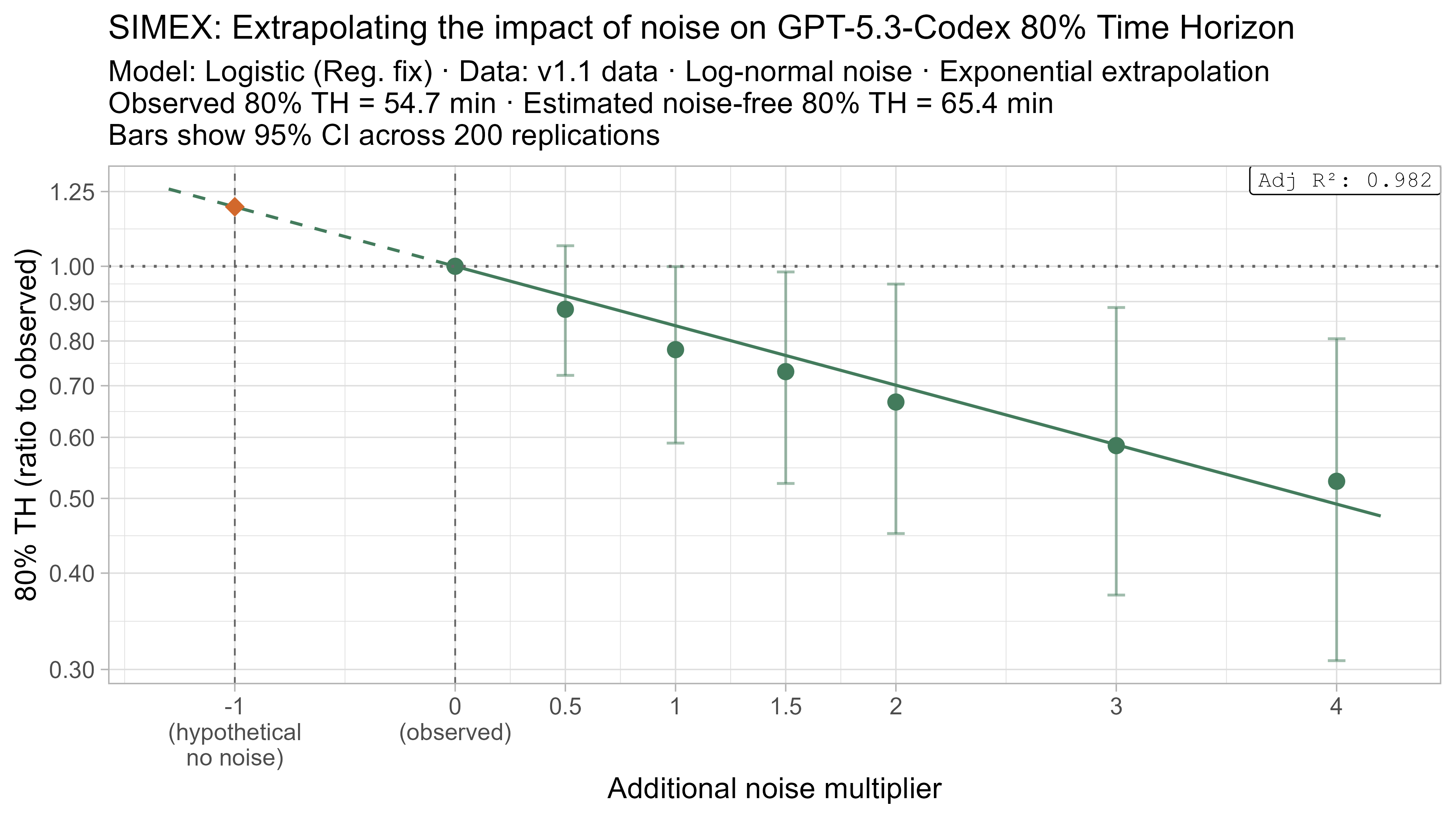
Here is what the relationship between noise and time horizon looks like for Opus 4.6 using the standard logistic model:
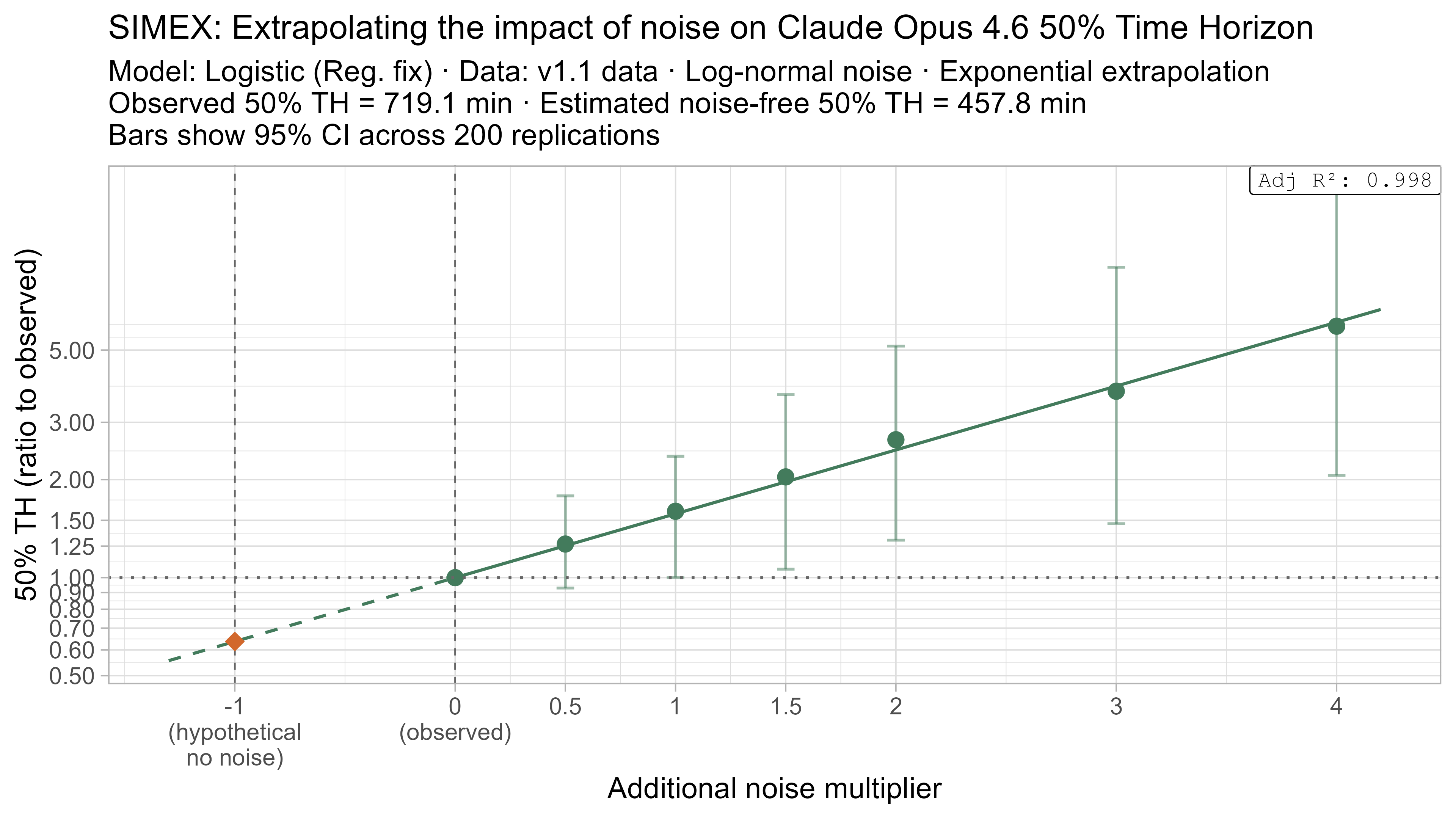
This is useful, as it shows that while there is a clear trend for how noise impacts the 50% TH on average, it also illustrates the large amount of uncertainty. Looking at the results for adding an amount of noise I think is similar to what already exists in the data the 95% range spans no impact to a 150% increase.
Keeping that uncertainty in mind, let’s look at how the ‘noise-adjusted’ time horizons vary for every LLM (due to the additional computational complexity I only computed point estimates of the SIMEX-adjusted time horizons):
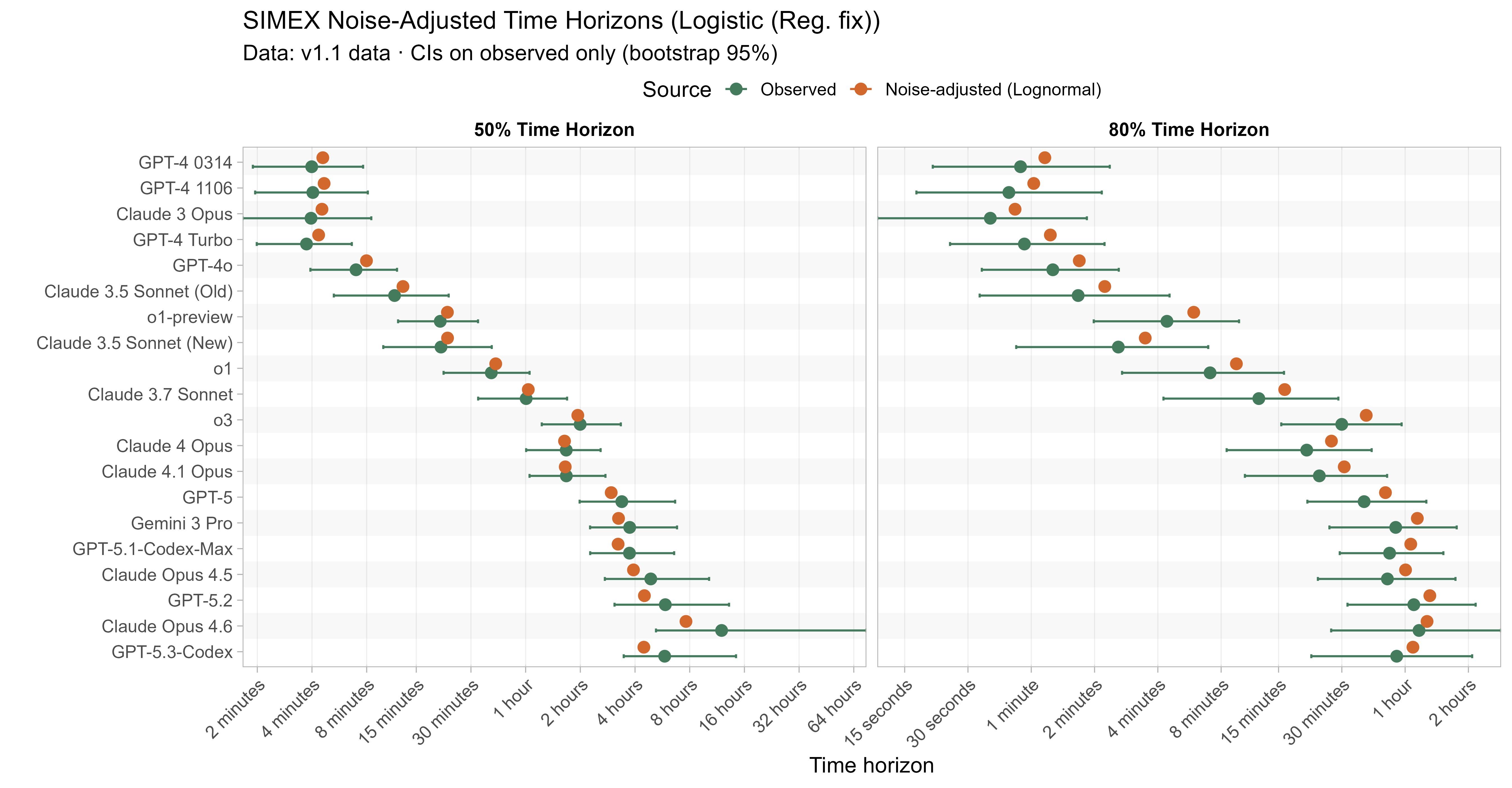
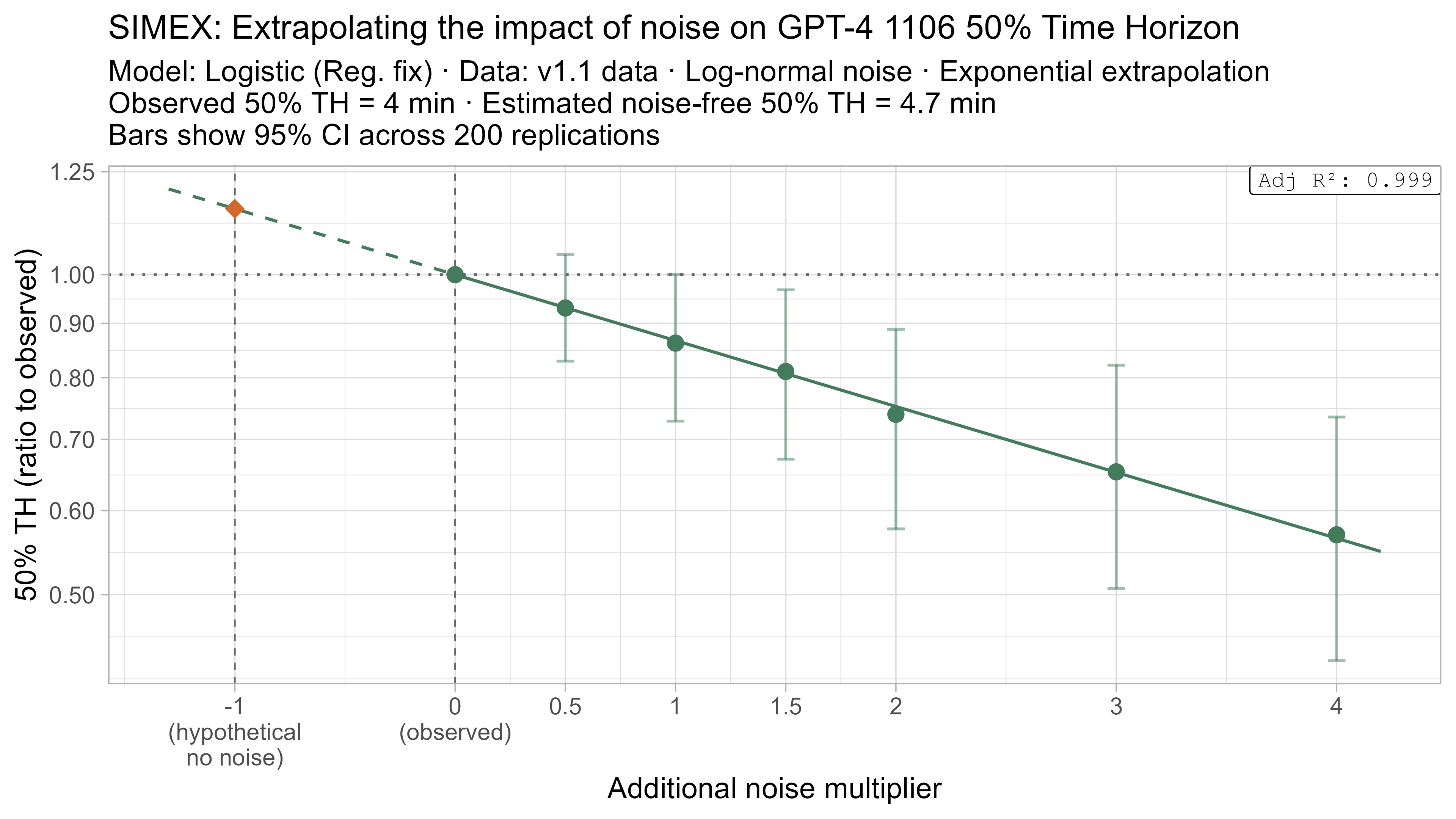
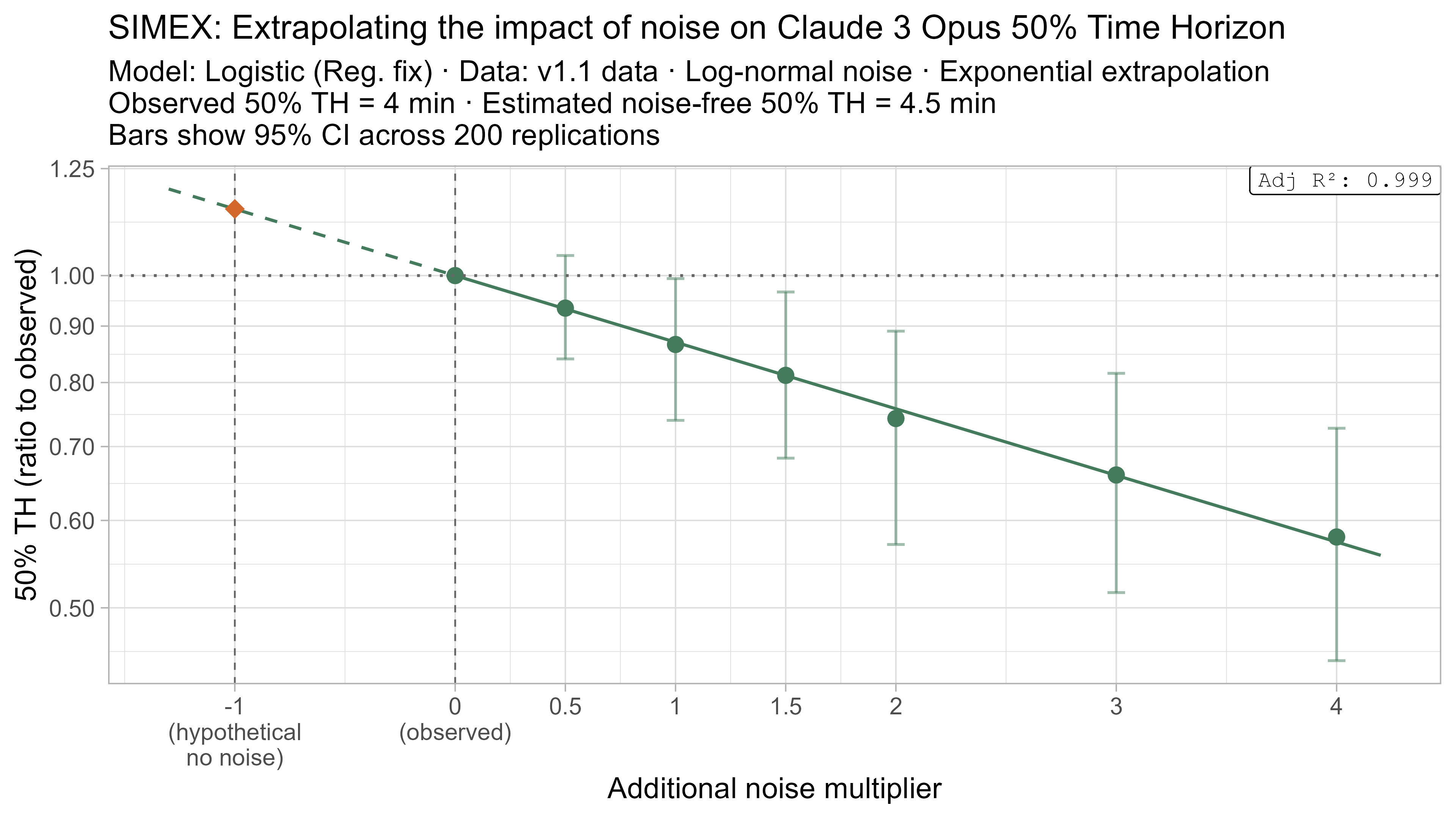
Based on these results, the task-length noise didn’t have a substantial impact on 50% time horizon values prior to Opus 4.5. It does however consistently cause the 80% time horizon results to be biased down, which makes sense as they are more sensitive to longer tasks being underestimated compared to the reverse.
I also combined SIMEX with the previous approaches, looking at the average noise-adjusted results for a range of methods on both the full TH1.1 dataset and restricted to private-only tasks (focusing only on Opus 4.6 here for simplicity):
| Opus 4.6 SIMEX Results Method |
Full Dataset (TH1.1) | Private Tasks Only (TH1.1) | ||
|---|---|---|---|---|
| Noise-Adjusted 50% TH | Noise-Adjusted 80% TH | Noise-Adjusted 50% TH | Noise-Adjusted 80% TH | |
| Logistic (Reg. Fix) | 7h 38m (-36%) | 1h 16m (+9%) | 5h 20m (-26%) | 1h 1m (+19%) |
| Logistic (Reliability Ceiling) | 7h 4m (-37%) | 1h 25m (+11%) | 5h 9m (-26%) | 1h 11m (+22%) |
| Logistic (Fixed slope) | 7h 51m (-6%) | 1h 30m (-6%) | 5h 36m (-3%) | 1h 3m (-3%) |
| Weibull (Survival) | 6h 49m (-39%) | 1h 14m (+9%) | 5h 13m (-30%) | 1h 7m (+20%) |
| LOESS (nonparametric) | NA (noise caused fits to sometimes fail to cross 50%) | 1h 23m (+23%) | NA (noise caused fits to sometimes fail to cross 50%) | 1h 7m (+22%) |
One interesting takeaway of this is that applying the noise-adjustment causes the different modelling choices to give substantially more similar results, e.g. the fixed slope logistic used to have lower 50% time horizon values than the rest, but is much less impacted by noise and so its noise-adjusted TH is similar. The failures of the technique for the LOESS 50% TH illustrates some of the potential pitfalls.
Again I want to emphasise not to over-anchor on these numbers, as uncertainty over the level and form of noise in the data and how to model the impact of the noise on TH is substantial — as I showed adding an equivalent amount of noise sometimes had no effect, and other times more than doubled 50% TH. Nevertheless these results give a rough sense that on average accounting for the noise in the TH estimates could reduce Opus 4.6 50% TH results by 25-40% for the current logistic model.
I don’t think either of the techniques considered in this section are conclusive, and overall still feel very uncertain about the impact noisy task-length estimates are having on time horizon results. I hope to explore this further in future including using simulations, and Bayesian modelling to directly account for the noise in task length estimates.
Other changes
- There are also various other reasonable changes that I looked into, but that have small (<10%) impacts on the time horizon results so I will not go over them in detail:
- Not including the task diversity weighting (1/sqrt(family size))
- Dropping SWAA tasks
- There are also some changes that would be reasonable but would involve changes to the model architecture that were infeasible for this post:
- Having task-specific discrimination parameters instead of having them vary by LLM
- Explicitly modelling task-difficulty-for-LLMs as being different from baseliner time (e.g. due to some tasks being ‘messier’ than others)
- Switching to a fully Bayesian modelling approach
- Accounting for baseliners failing to complete some tasks
Conclusion
There are many reasonable variations one could make to the time horizon modelling. The ones explored in this post mostly reduced recent 50% time horizon estimates, but kept them within the (very wide) confidence intervals. The aspect I’m least confident about is noise in task length estimates, which I hope to explore further in the future.
Beyond analysis choices, I still think the biggest sources of uncertainty are the task distribution itself and the fact that “time taken for humans” is a very imperfect proxy for difficulty-for-models.
I hope this post has helped readers better understand the modelling assumptions behind the time horizon results and how sensitive (or not) they are to reasonable alternatives.
Appendix
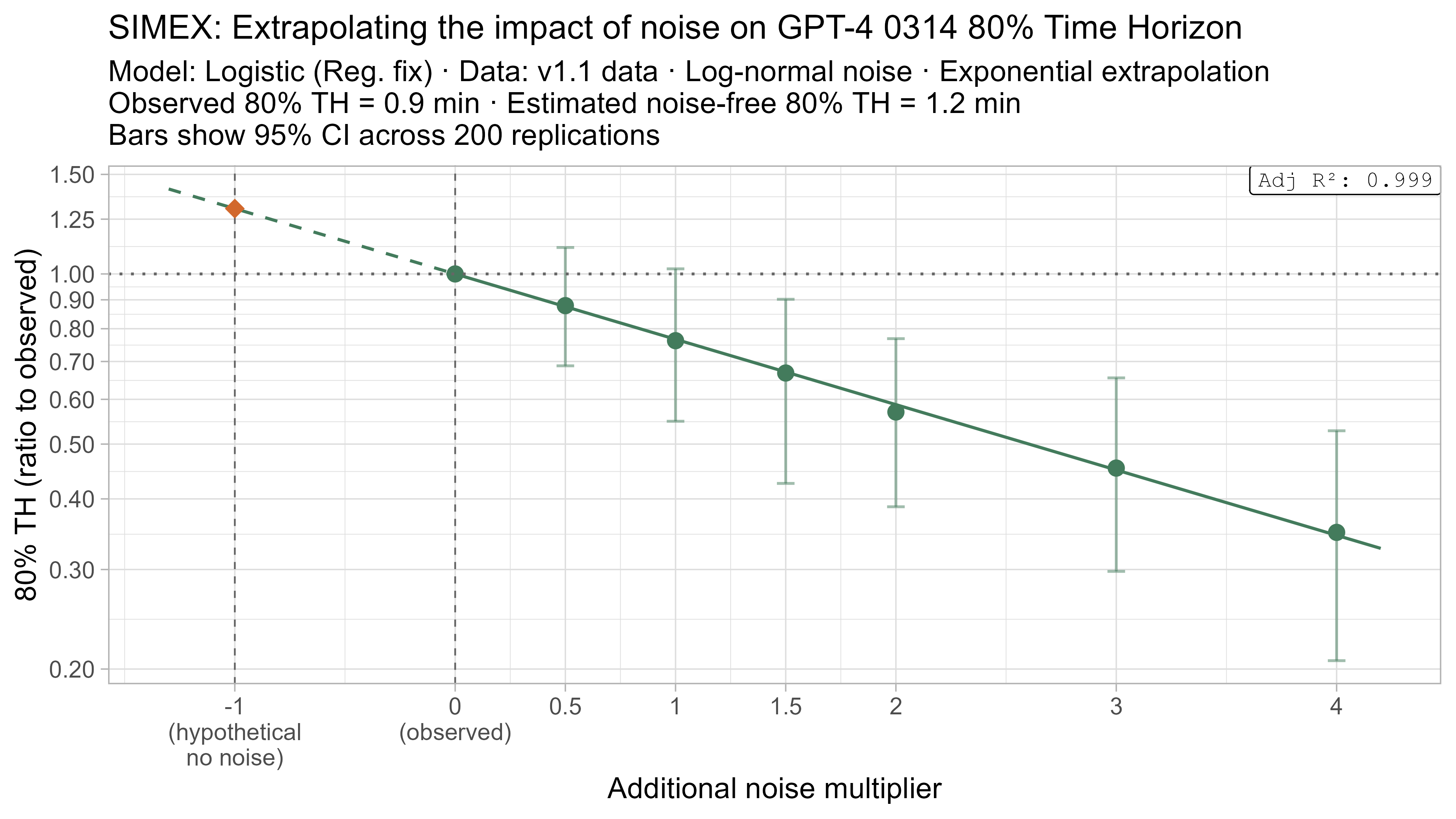
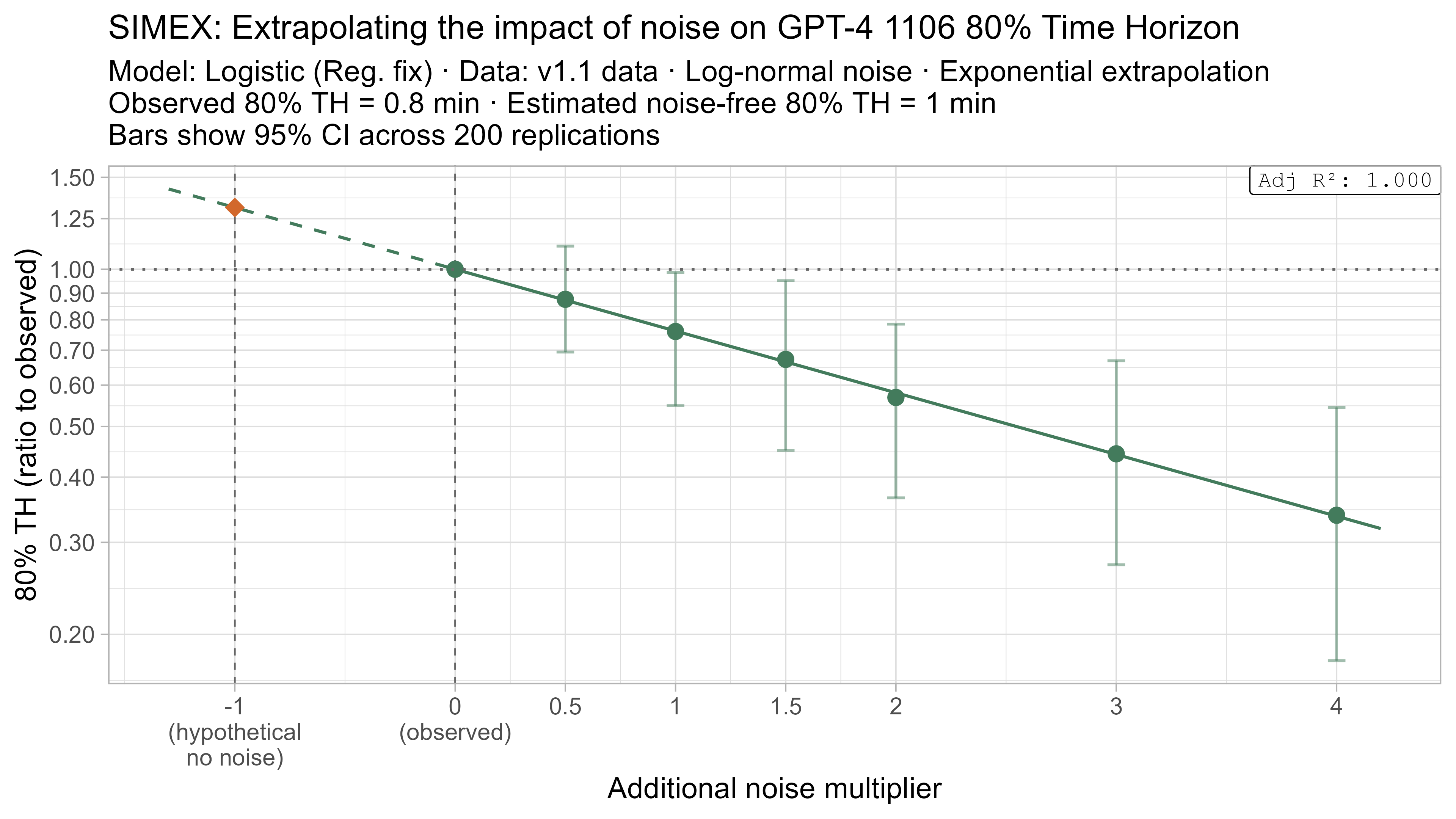
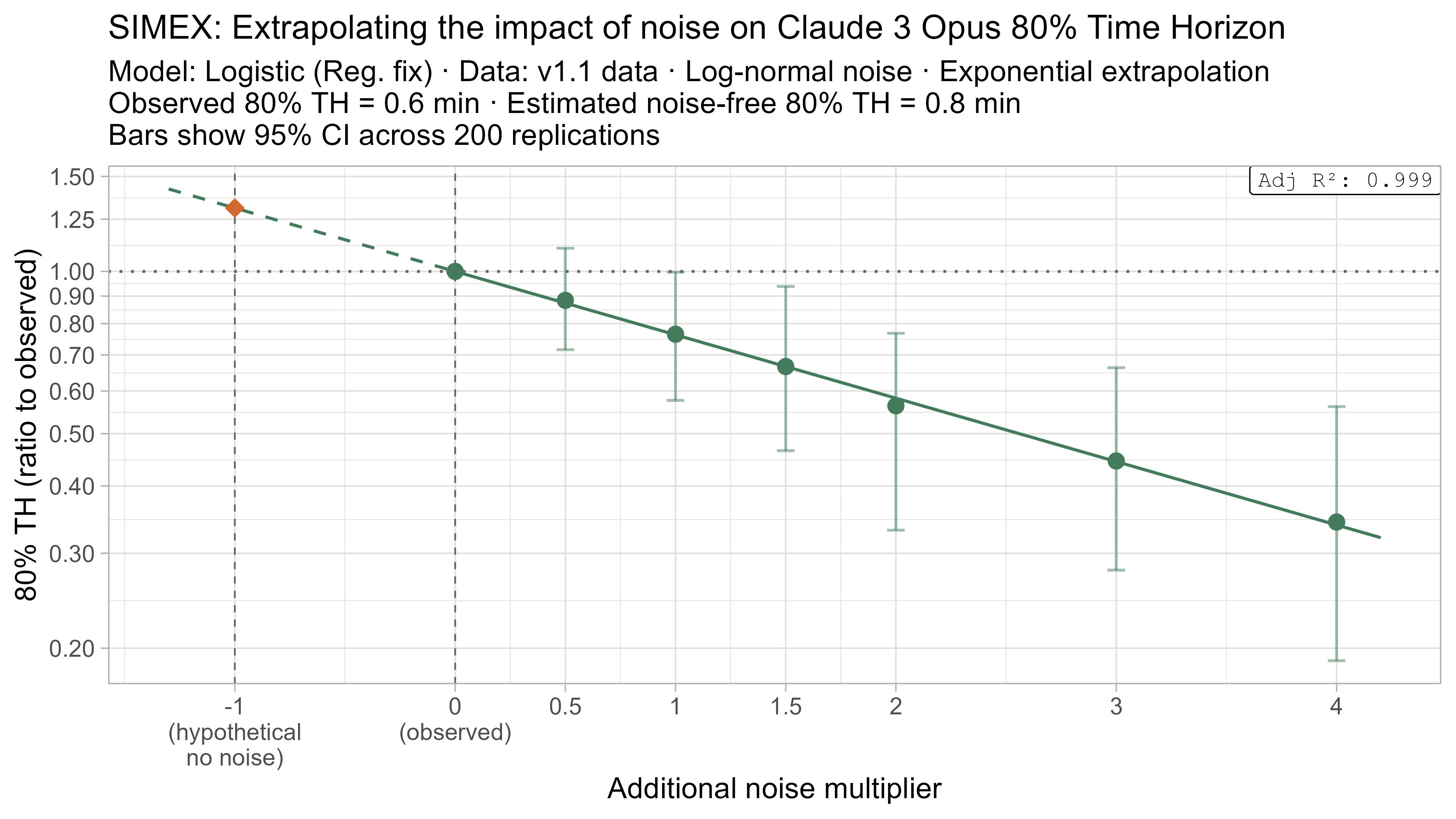
A1. Alternative curve fit time horizons — all LLMs
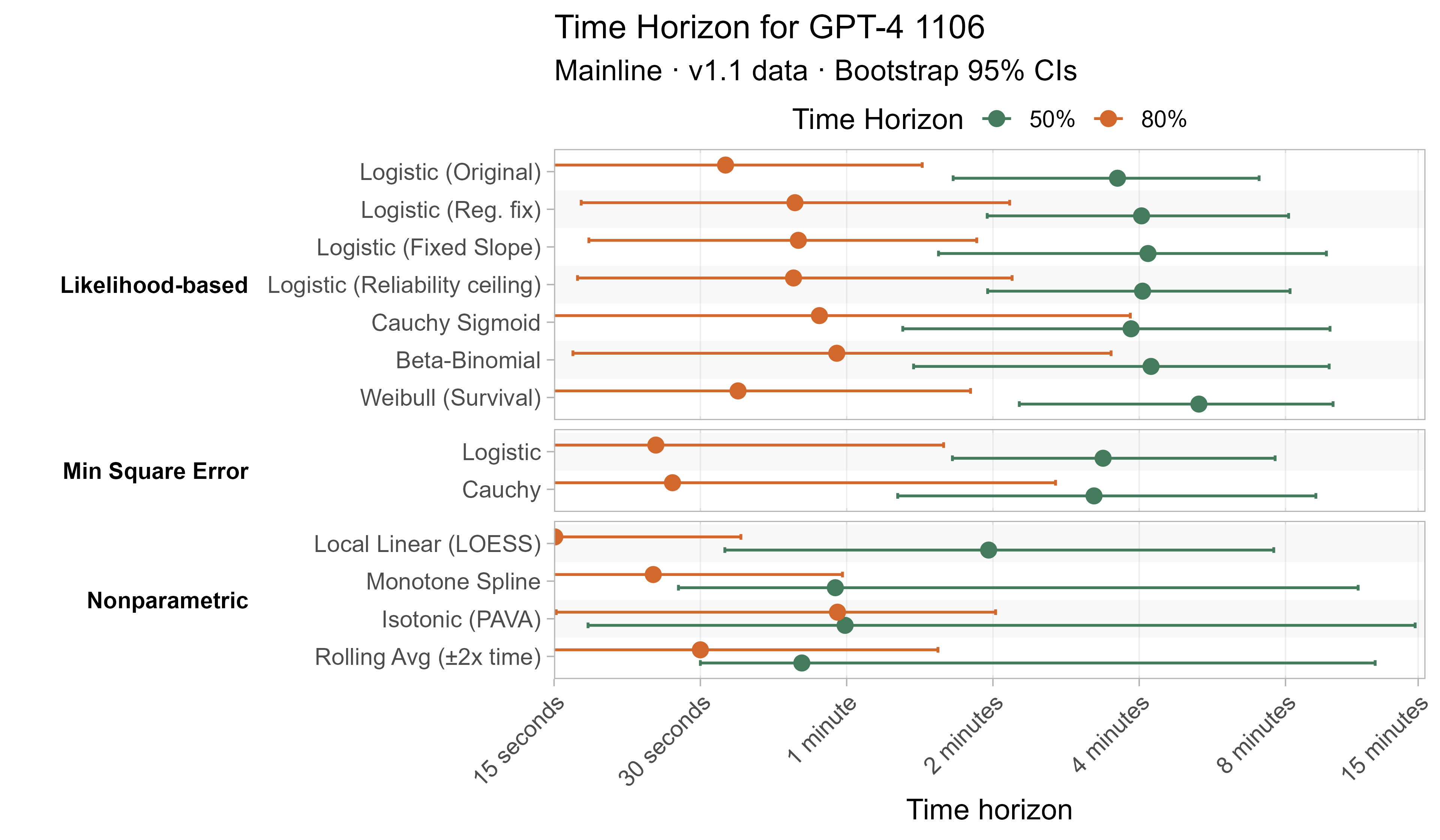
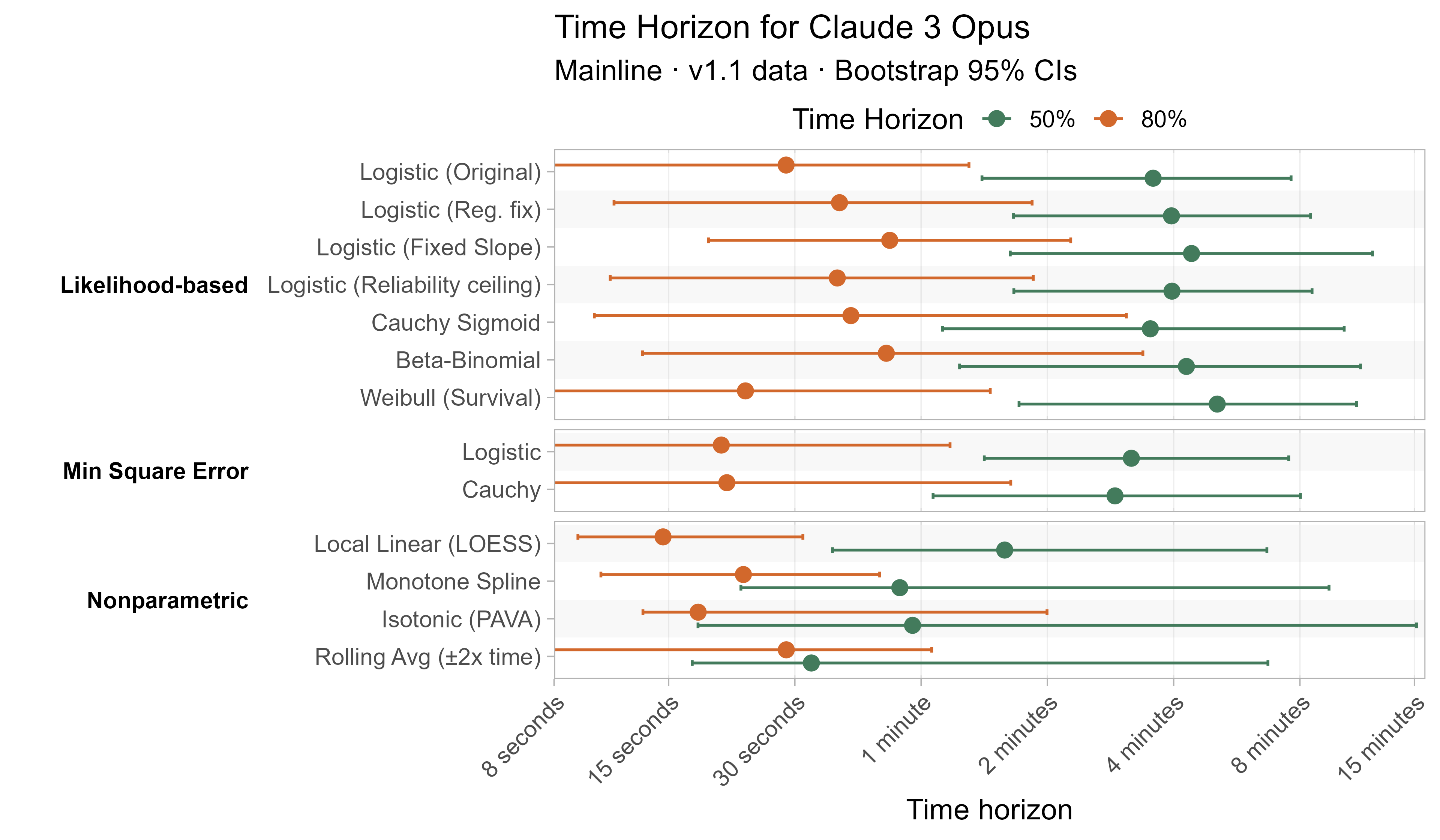
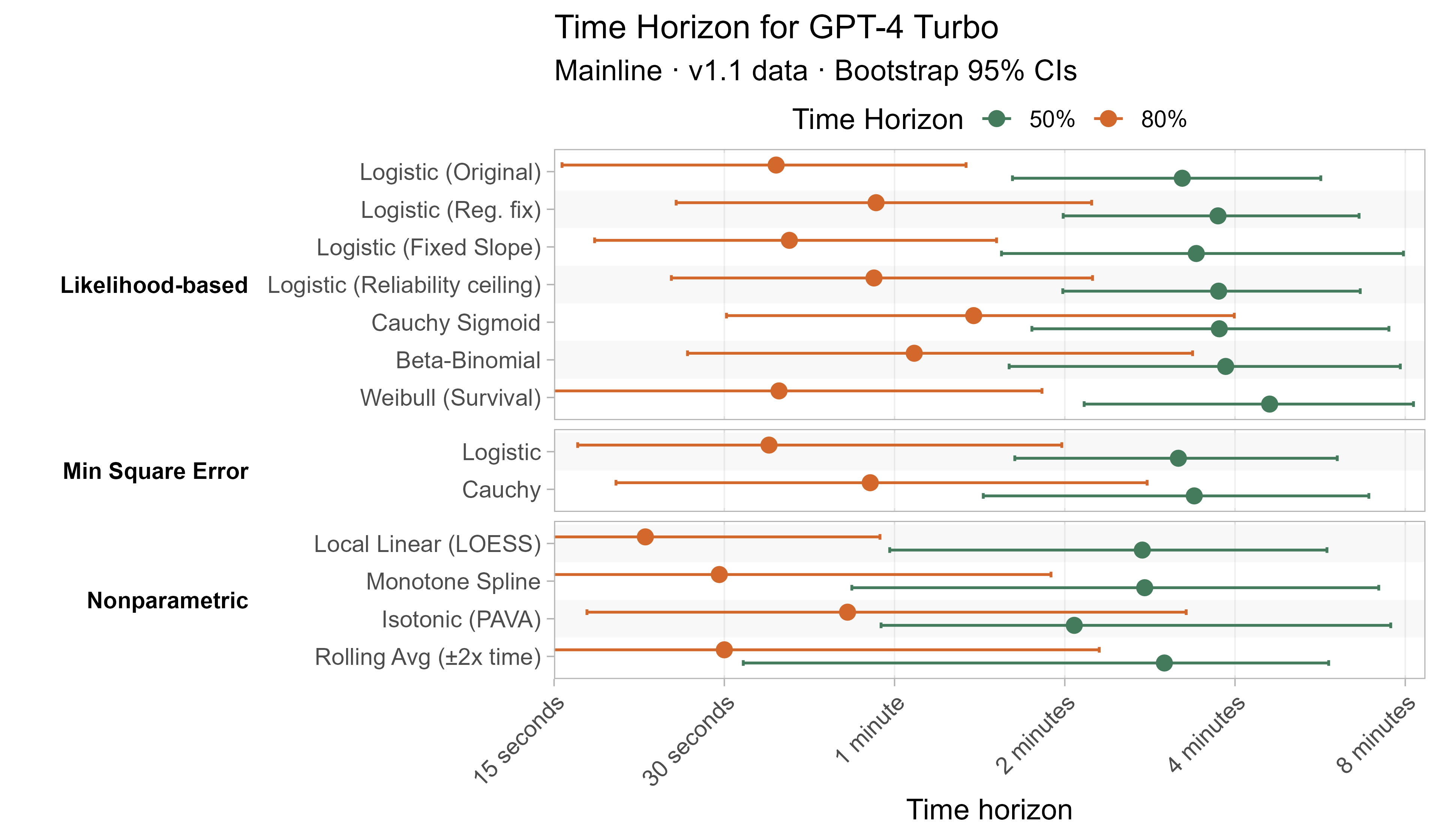
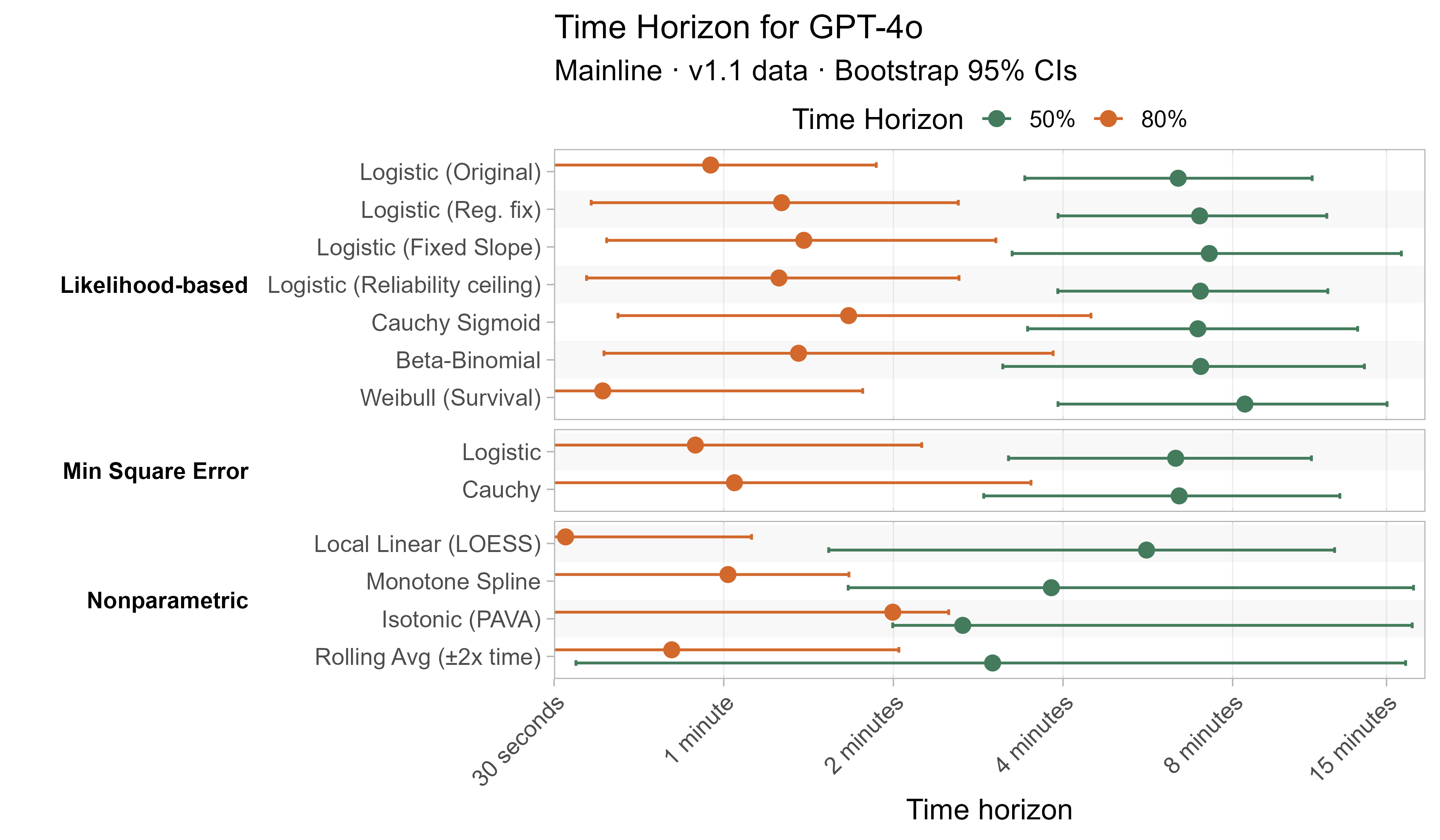
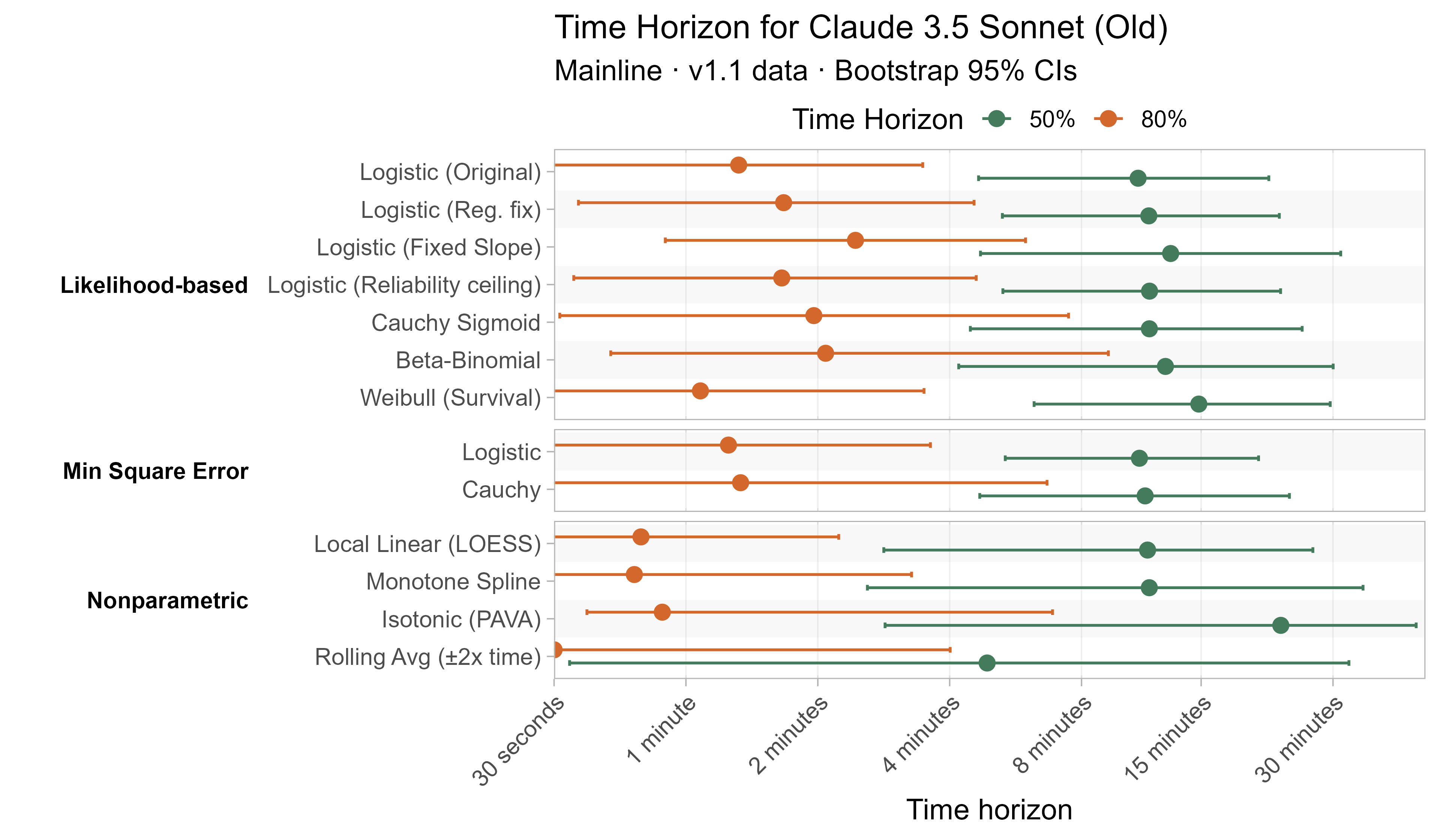
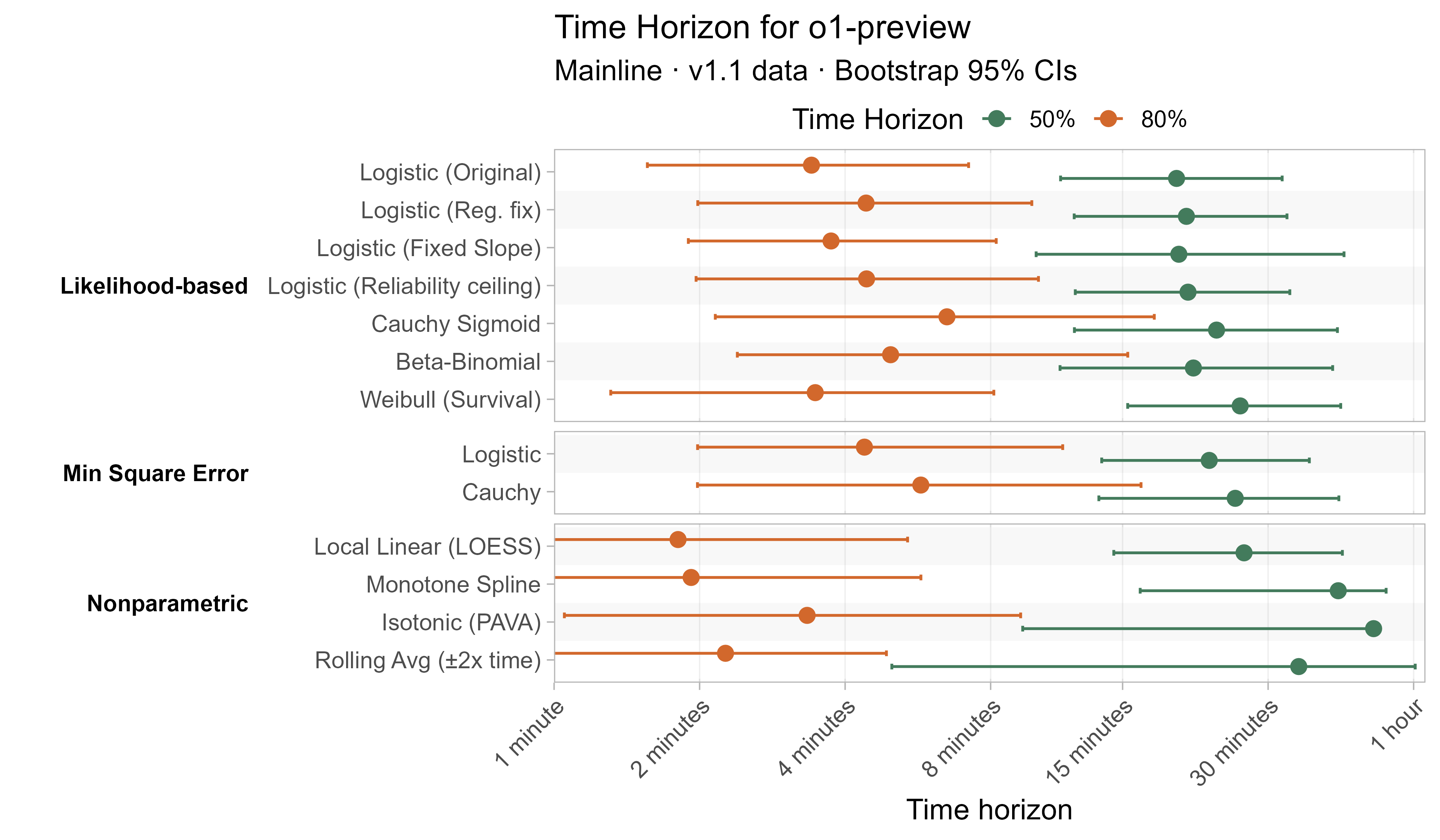
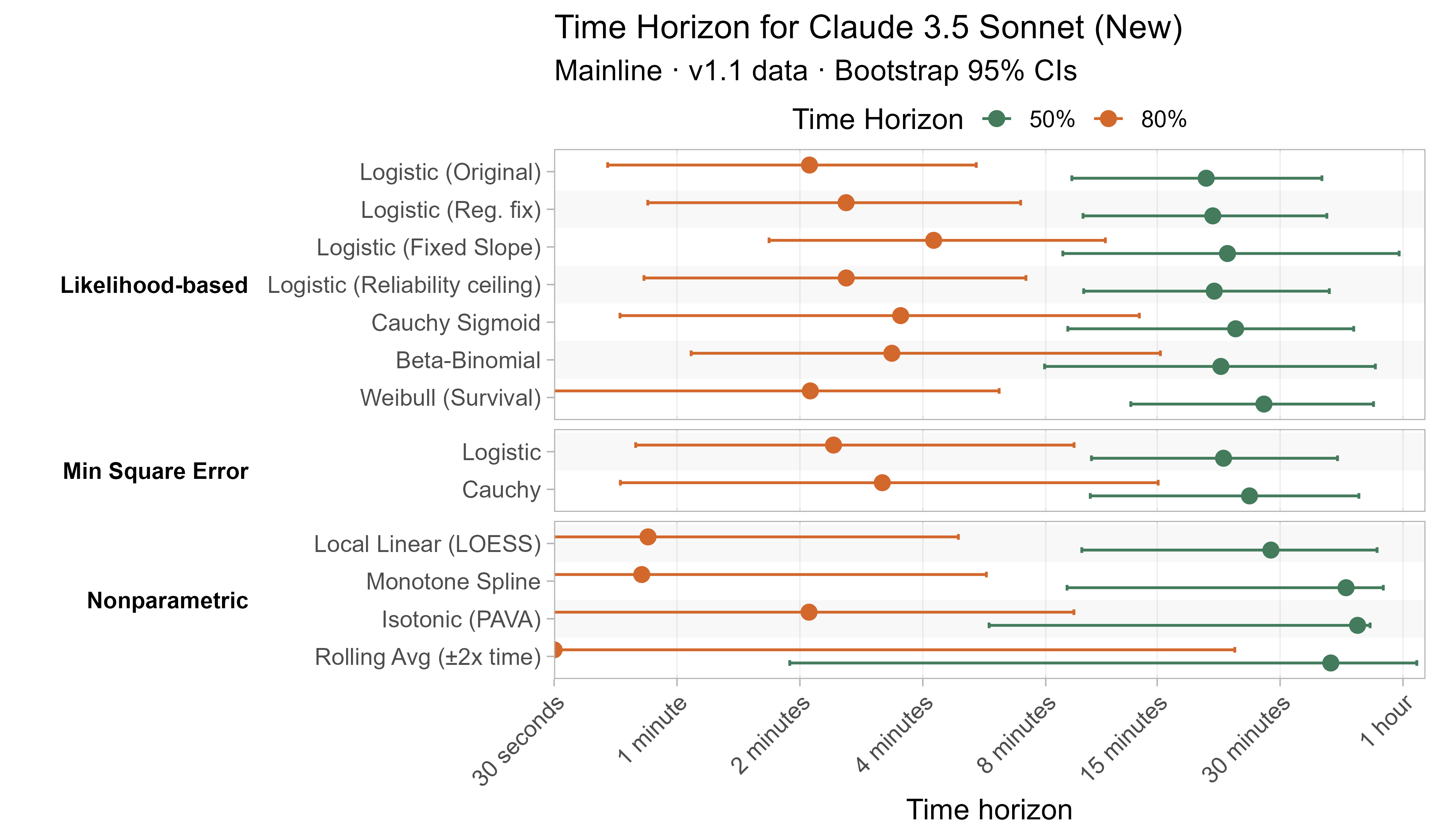
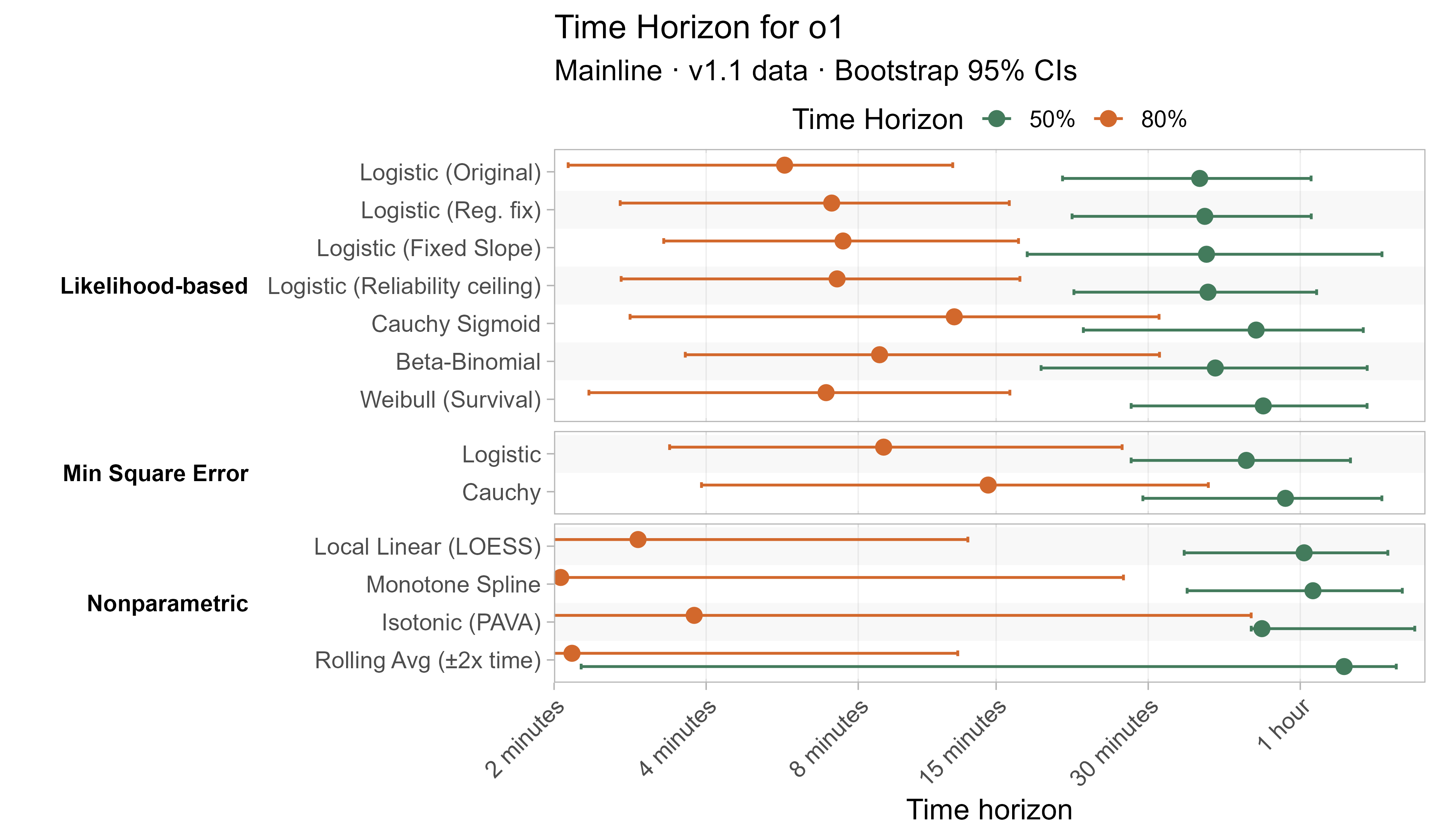
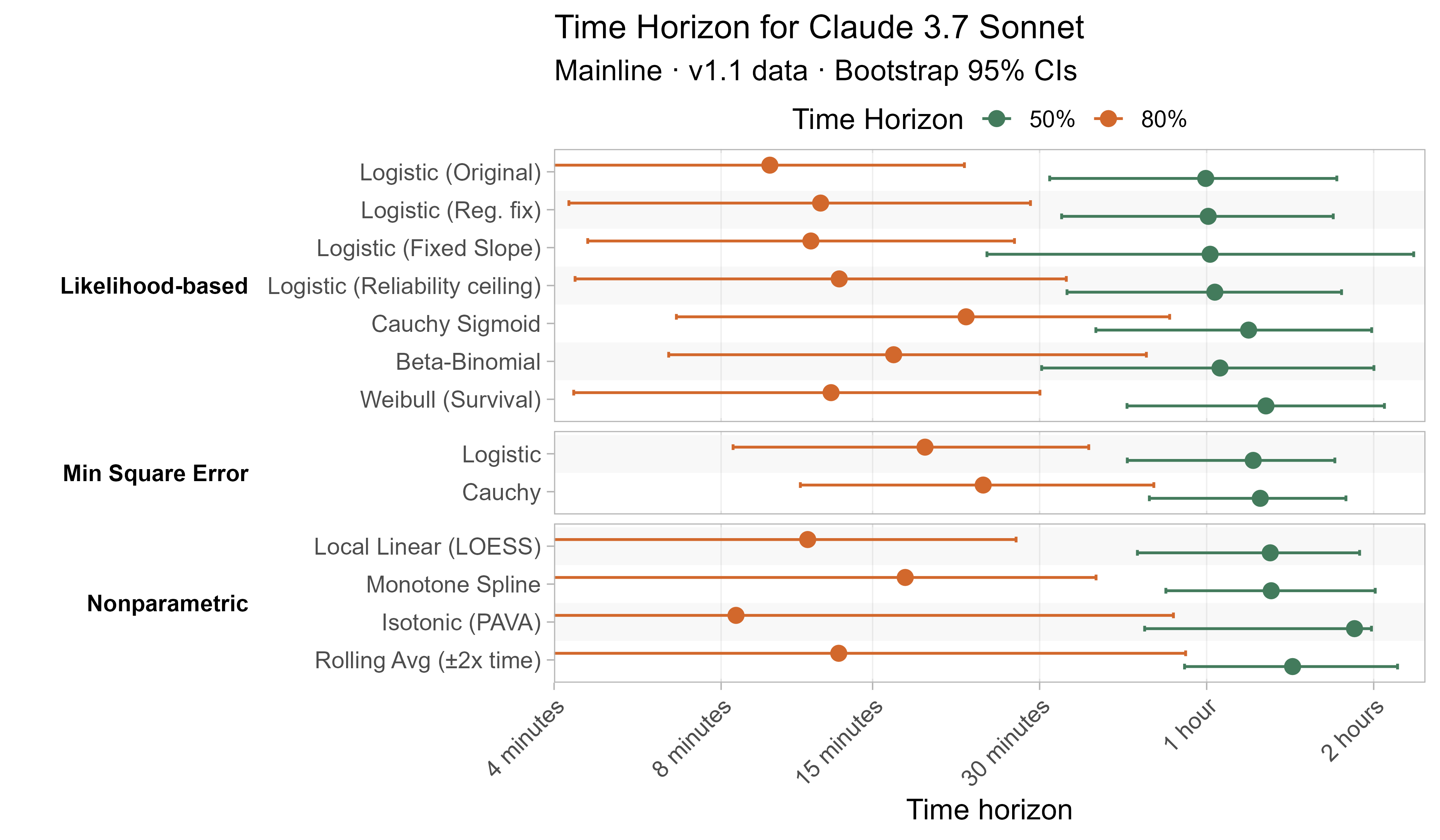
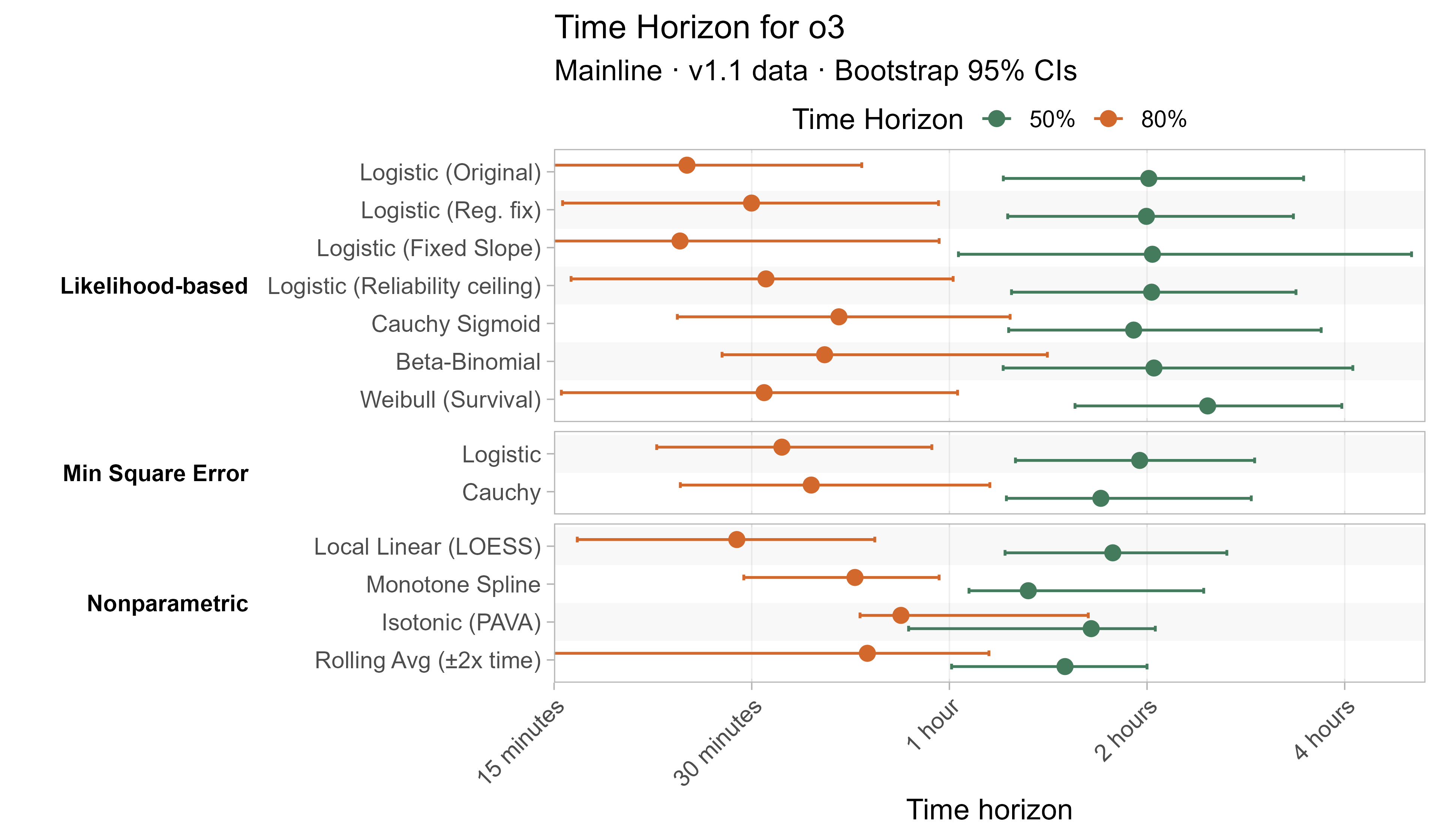
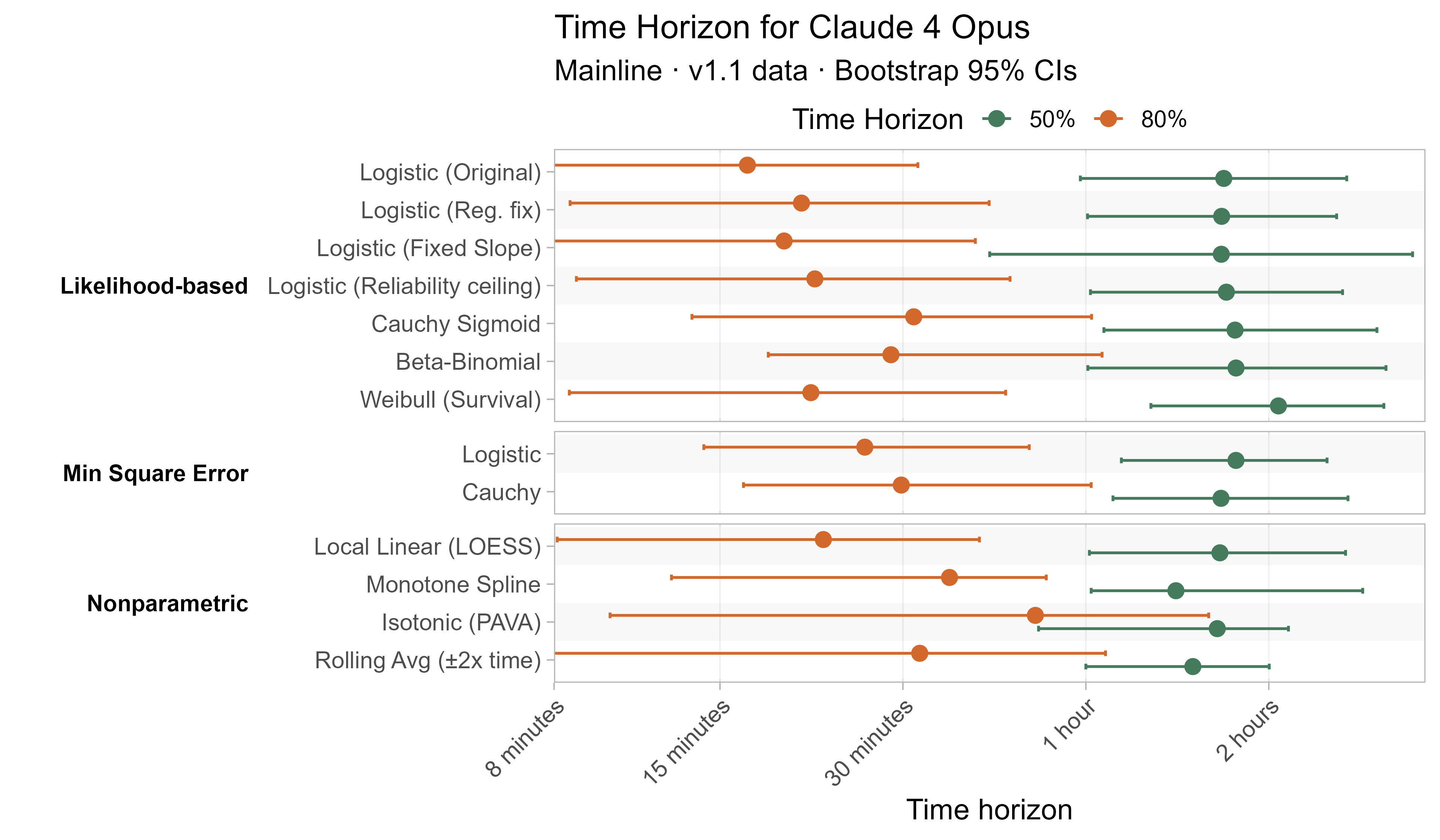
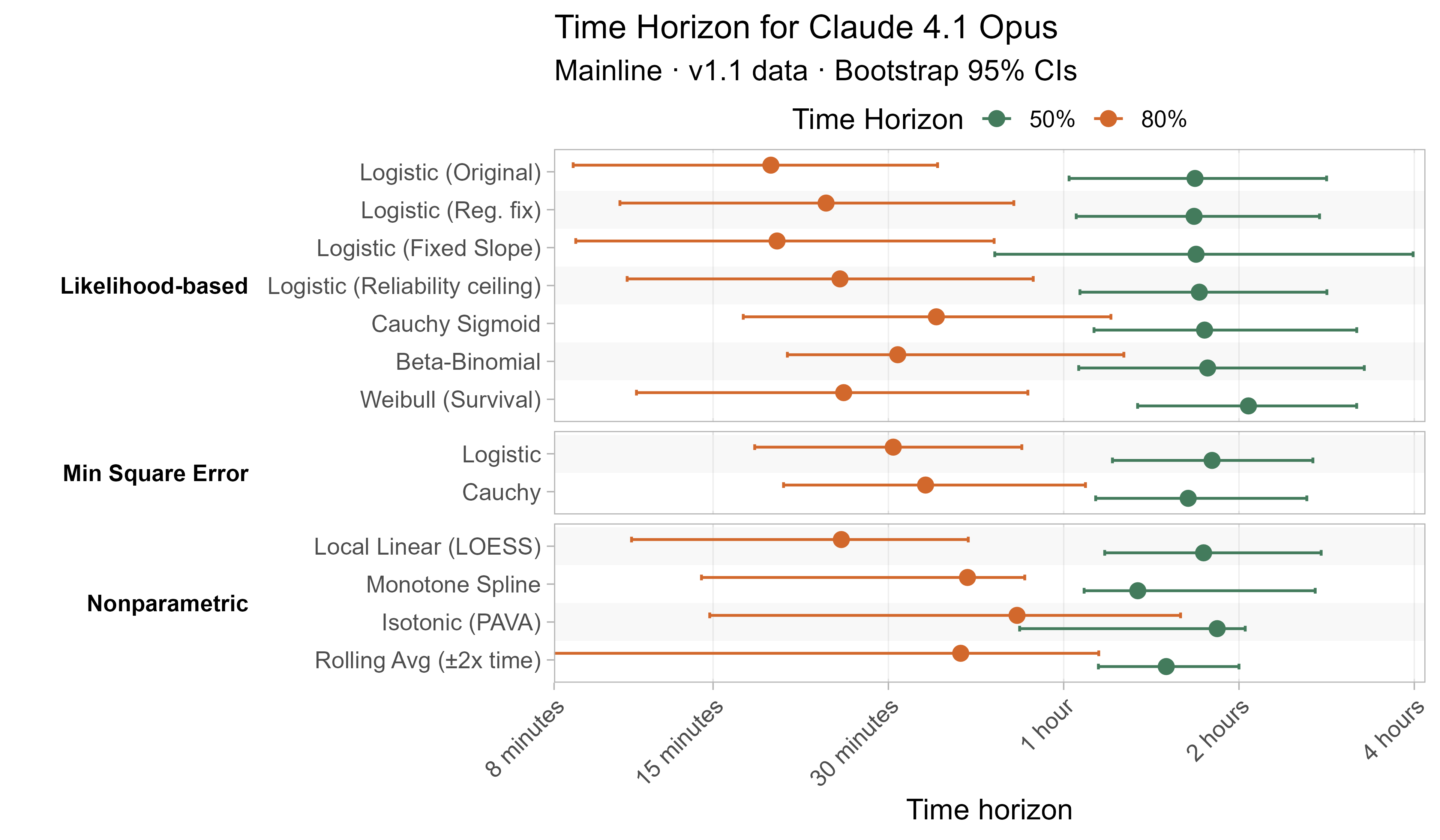
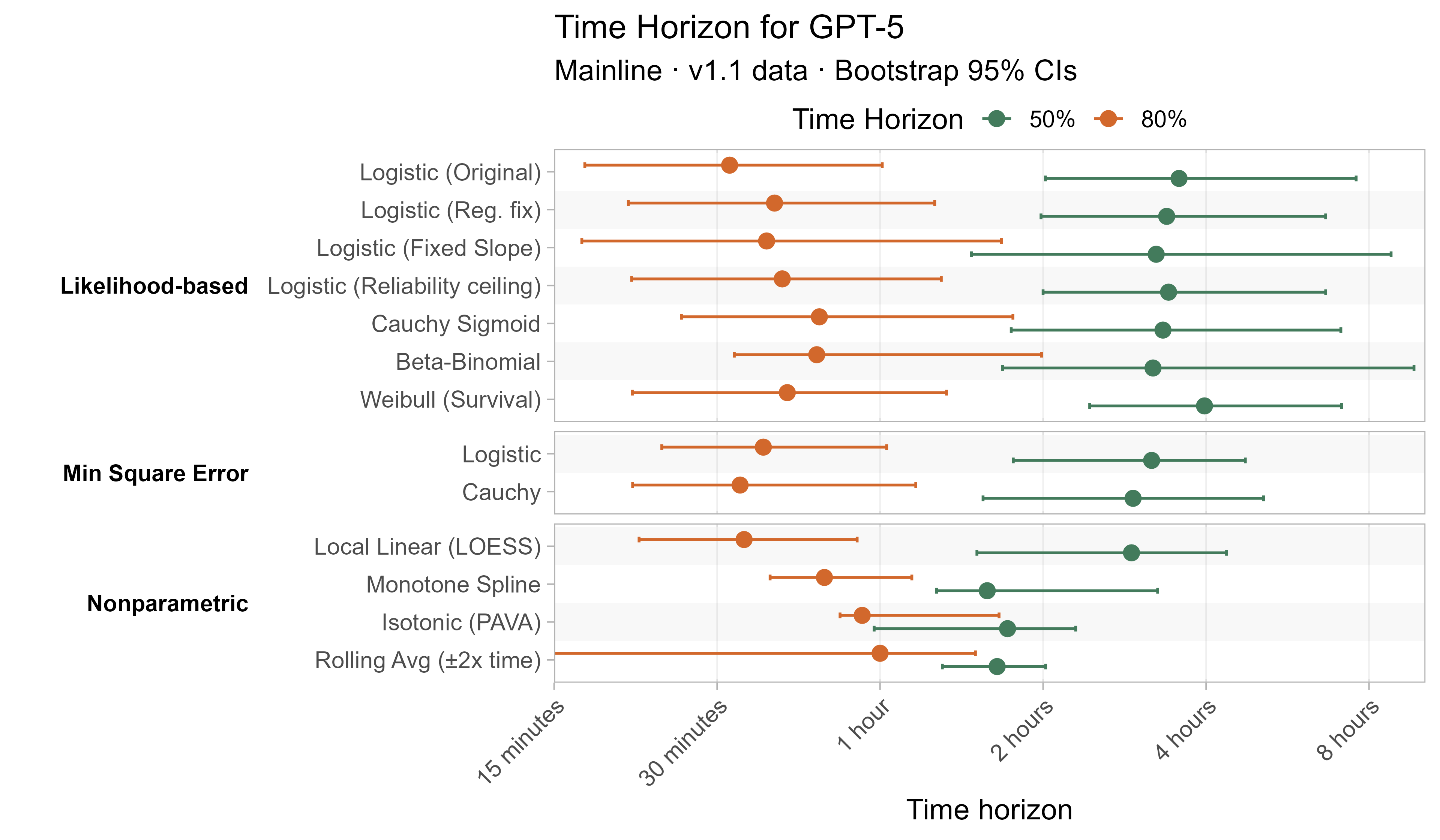
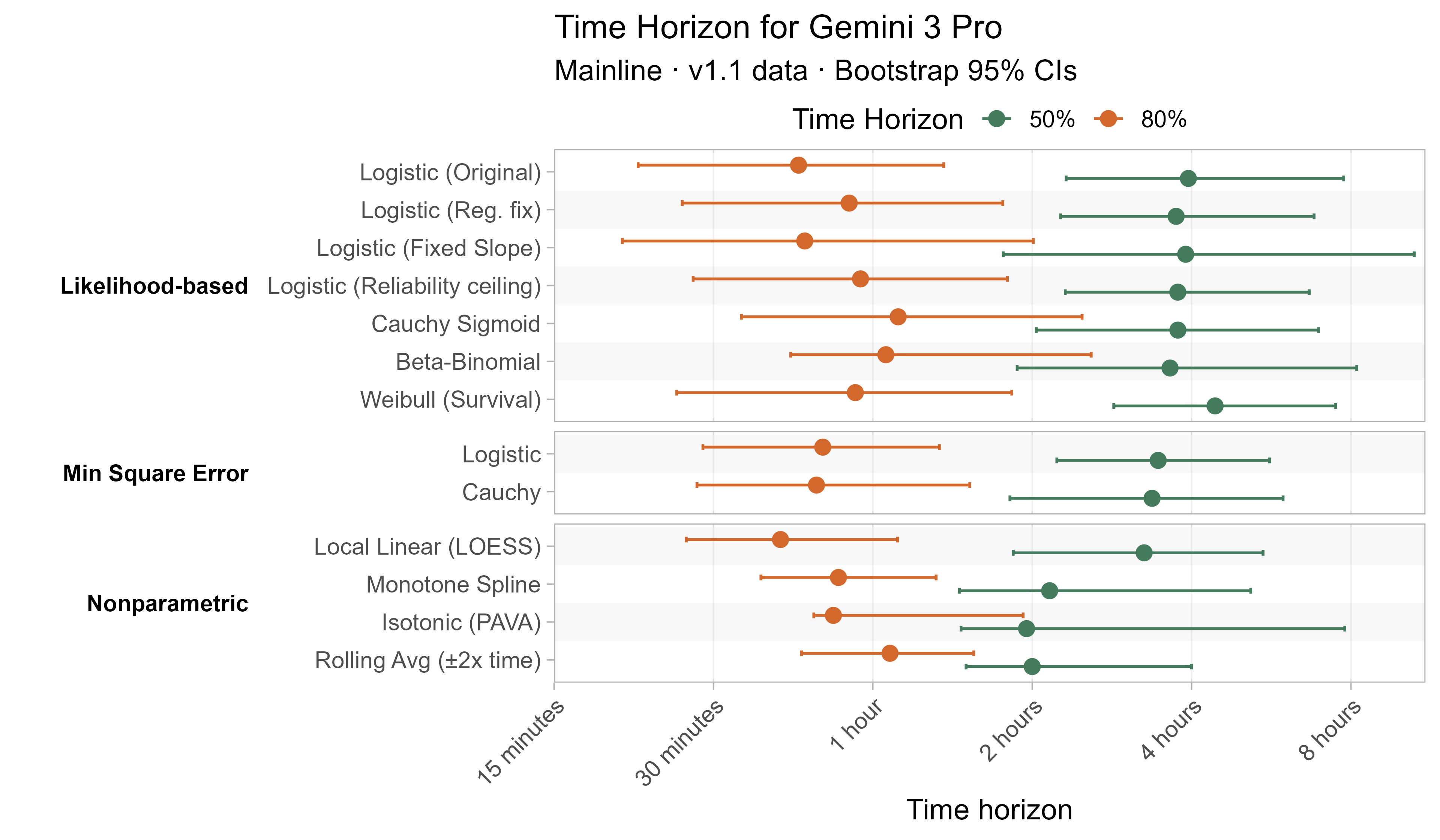
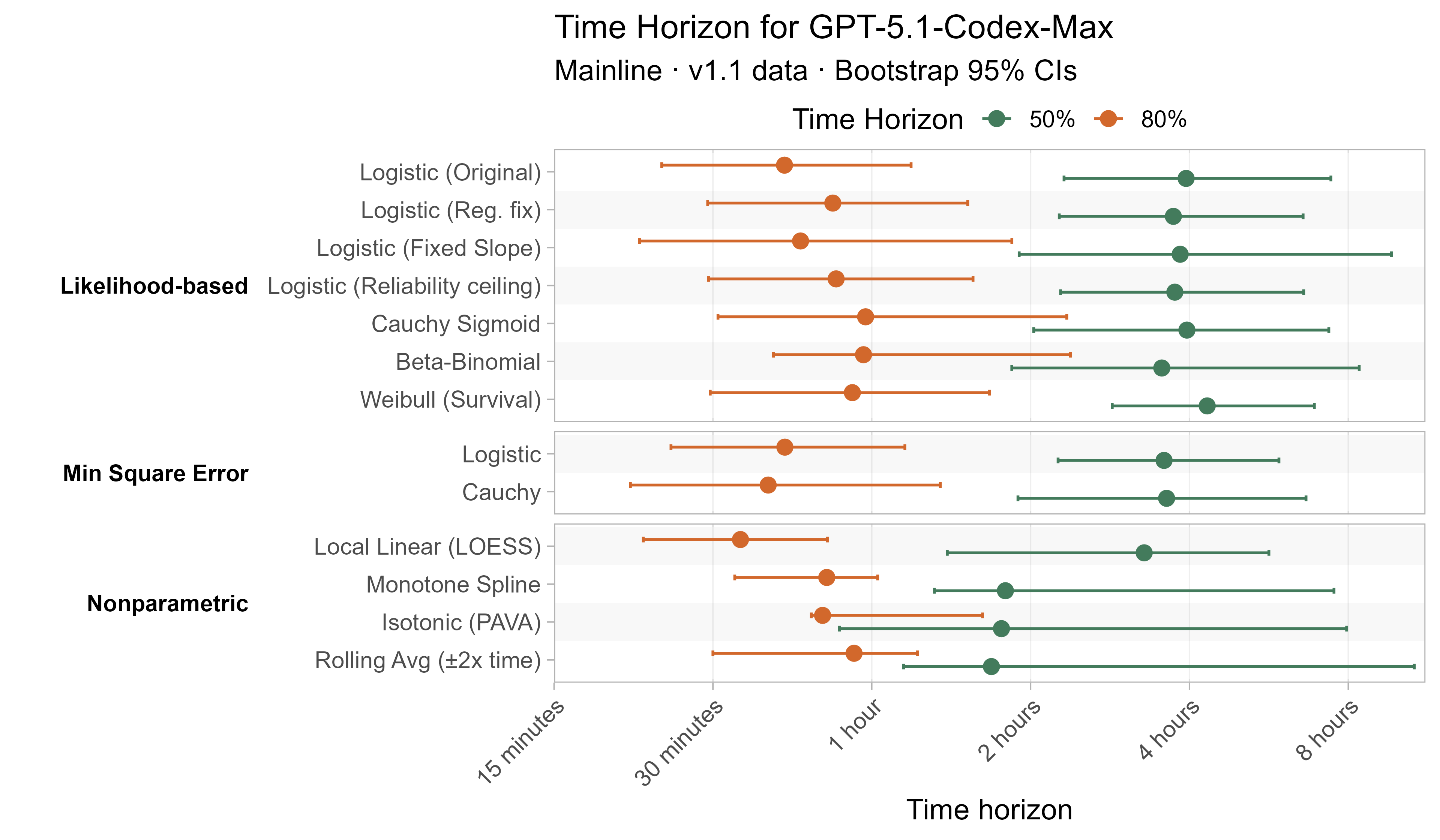
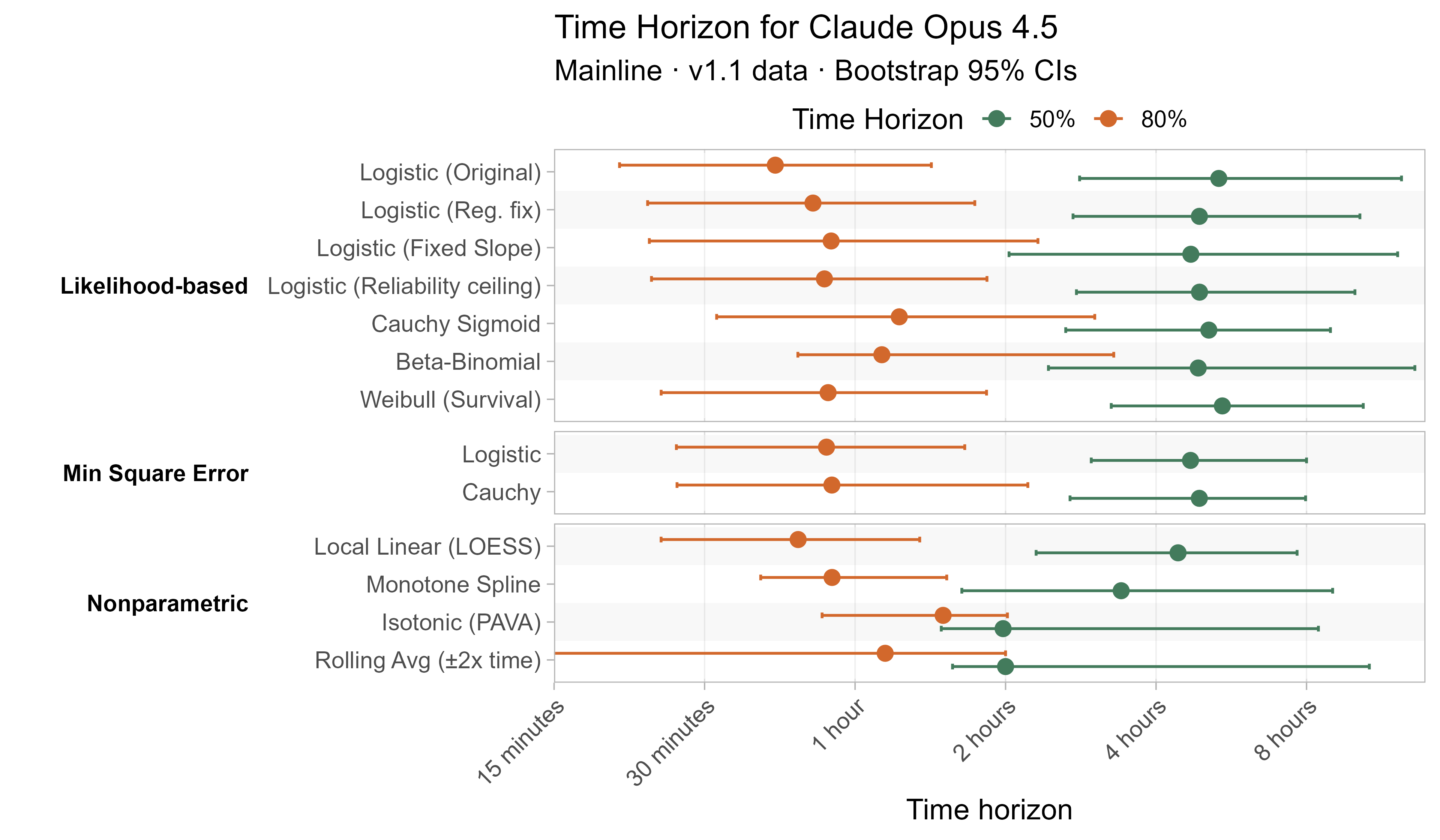
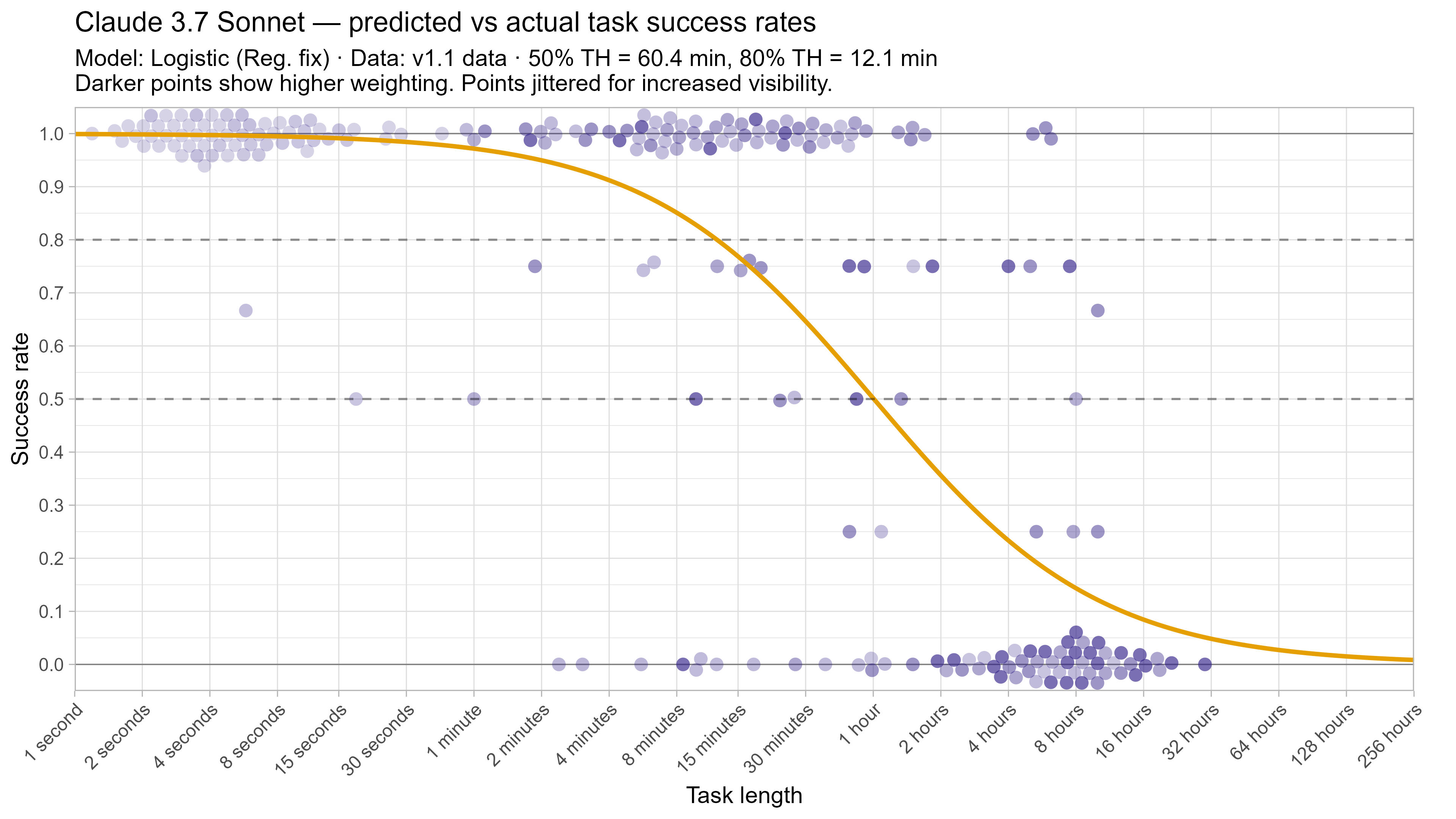
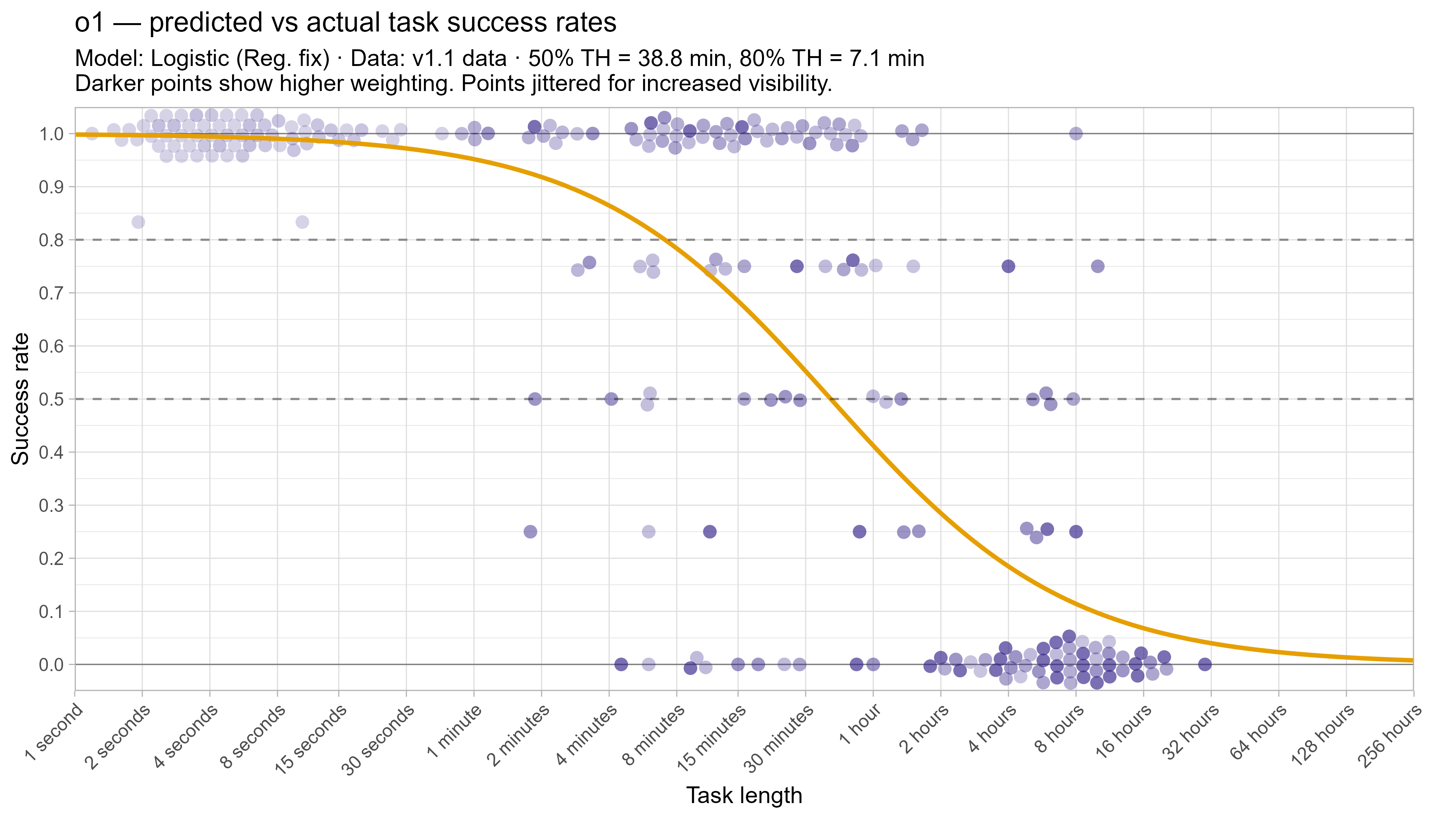
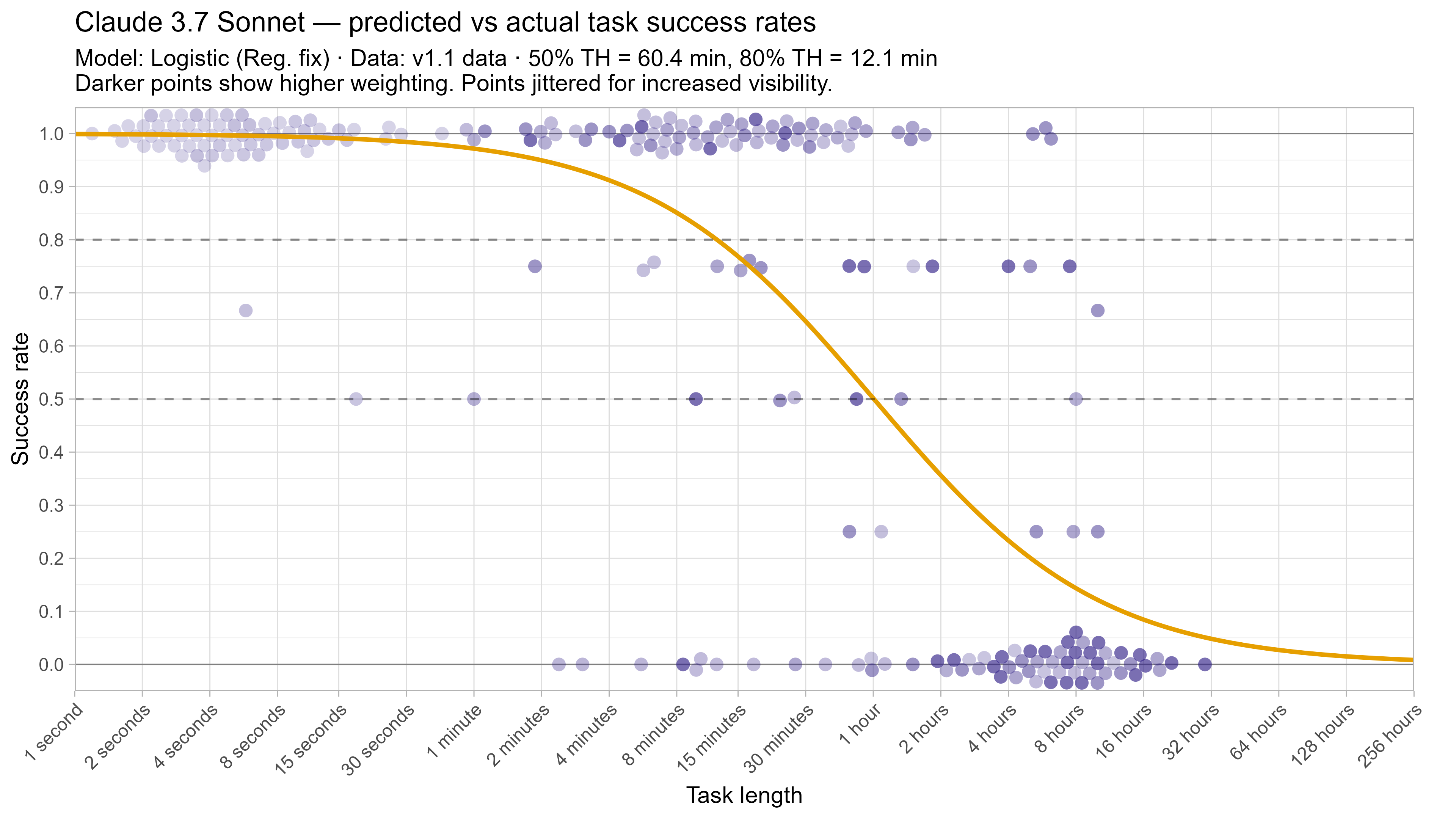
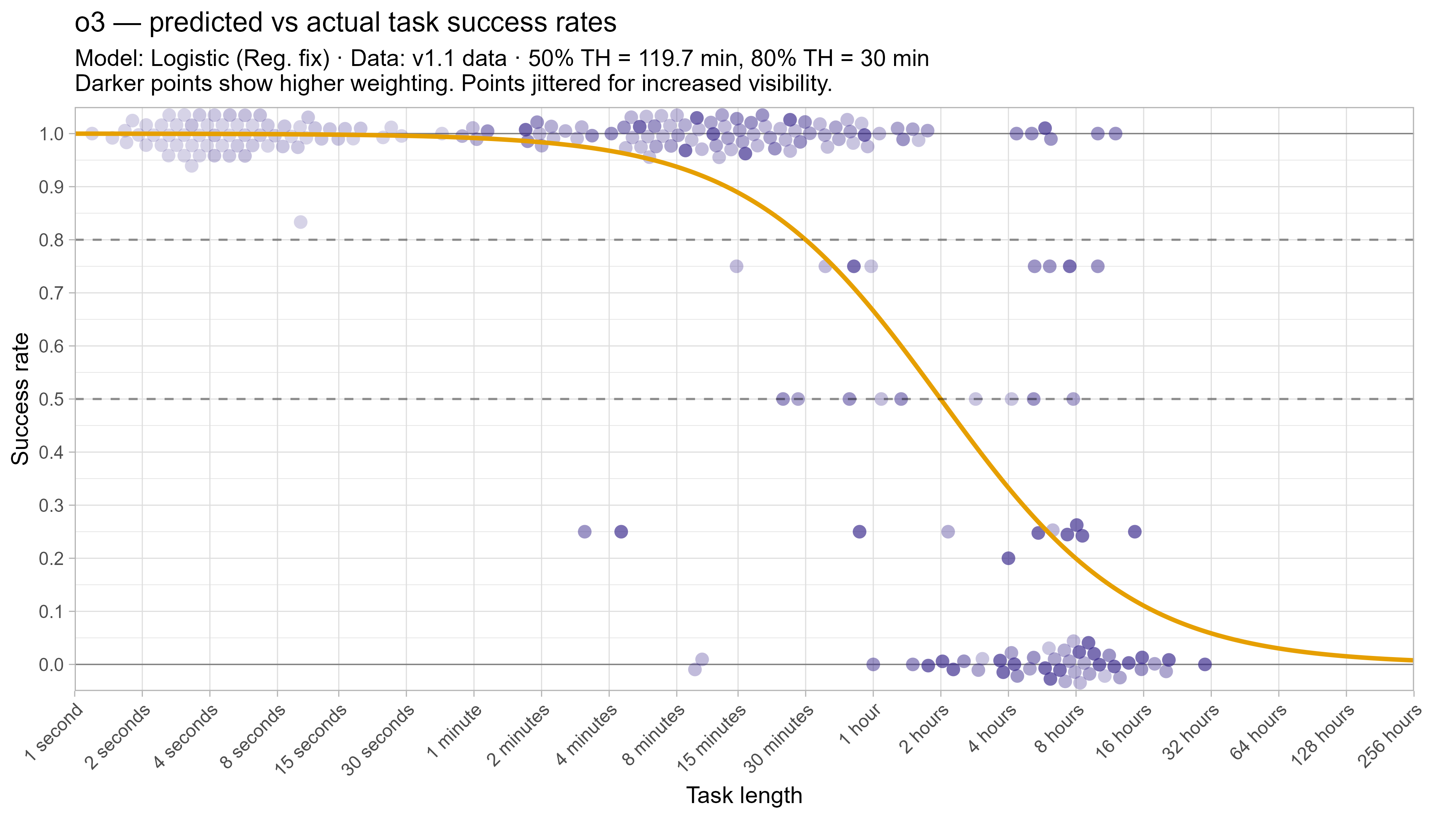
A2. Per-LLM fitted curves (TH1.1, Logistic Reg. Fix)
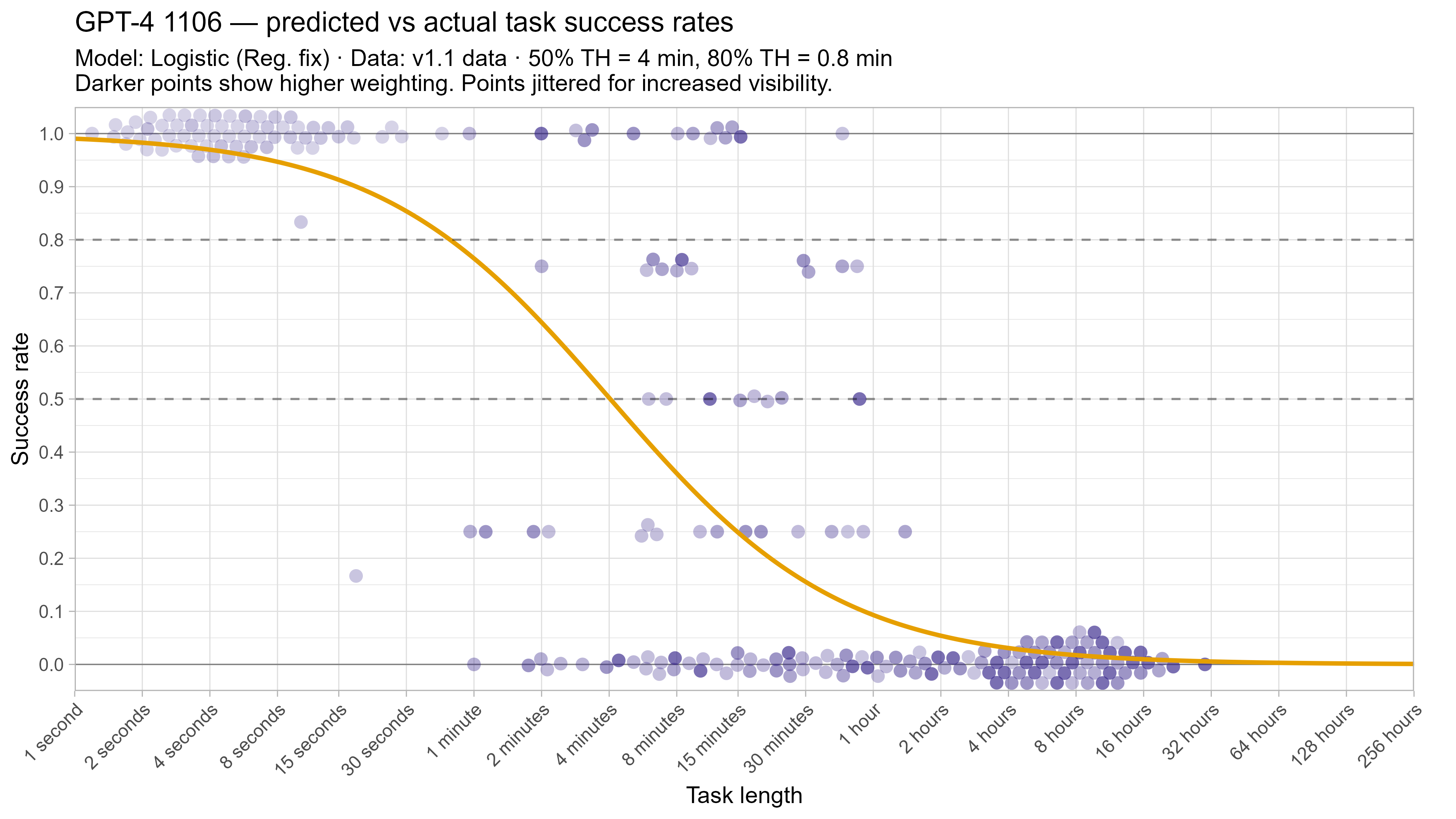
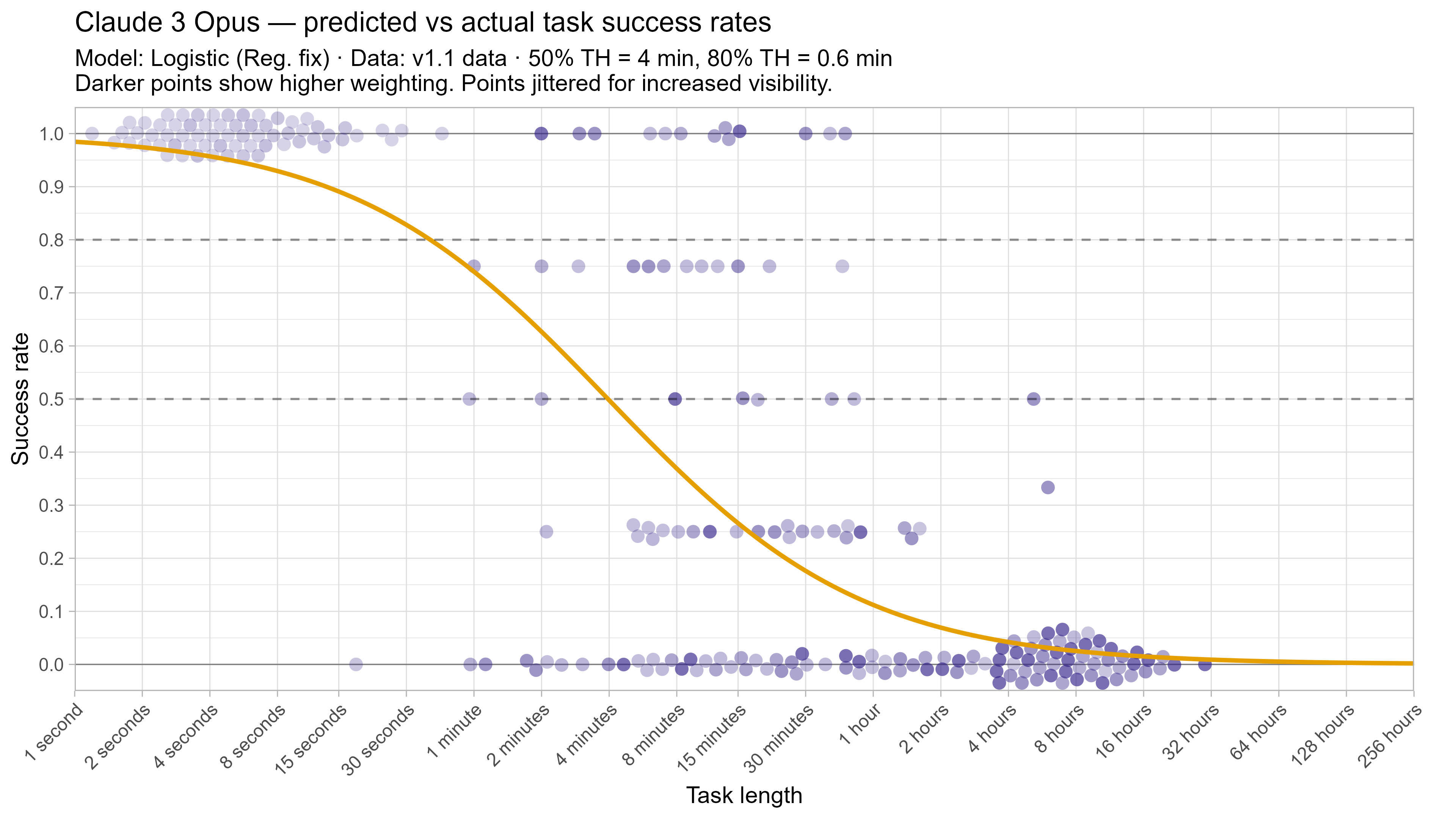
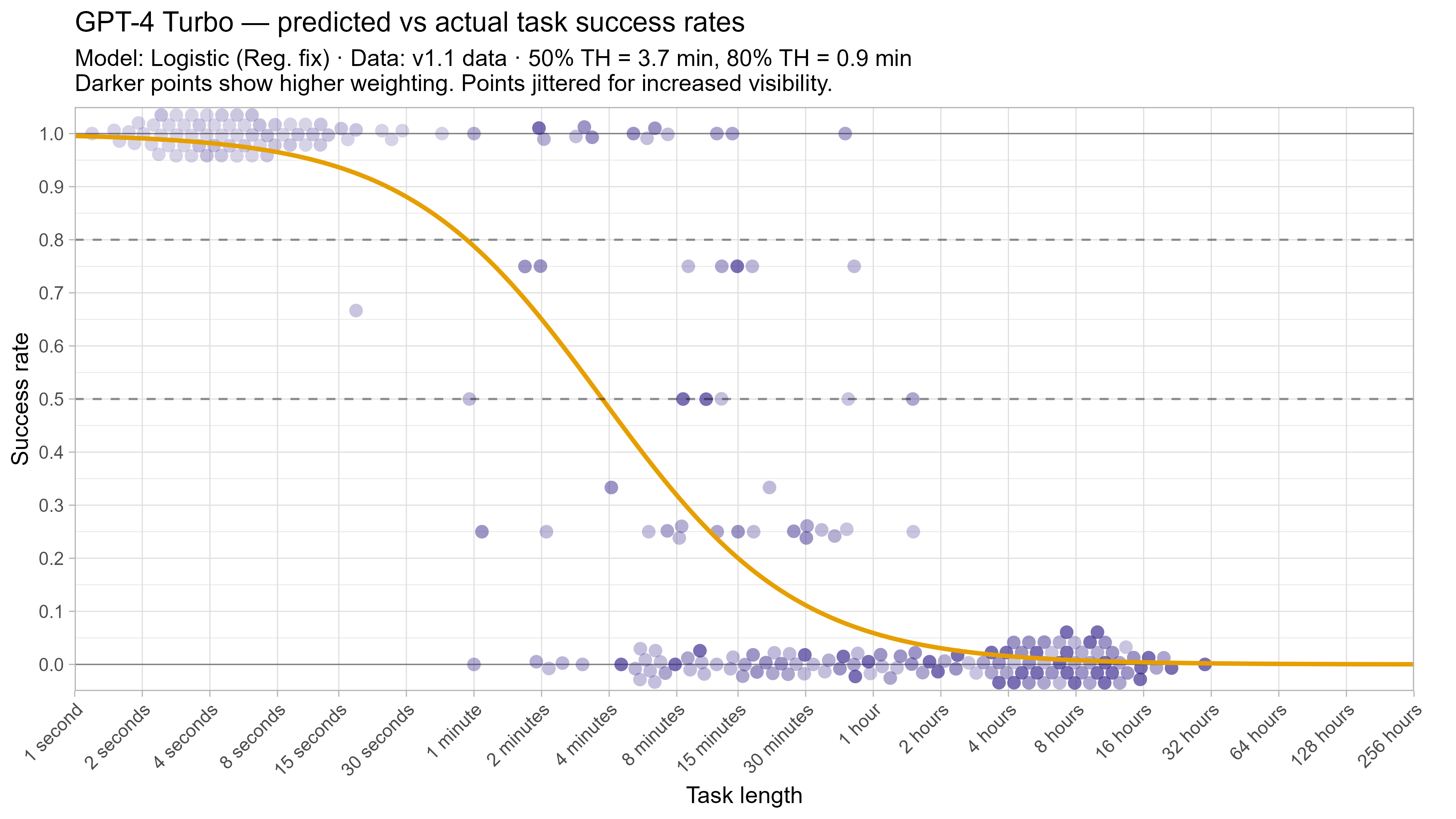
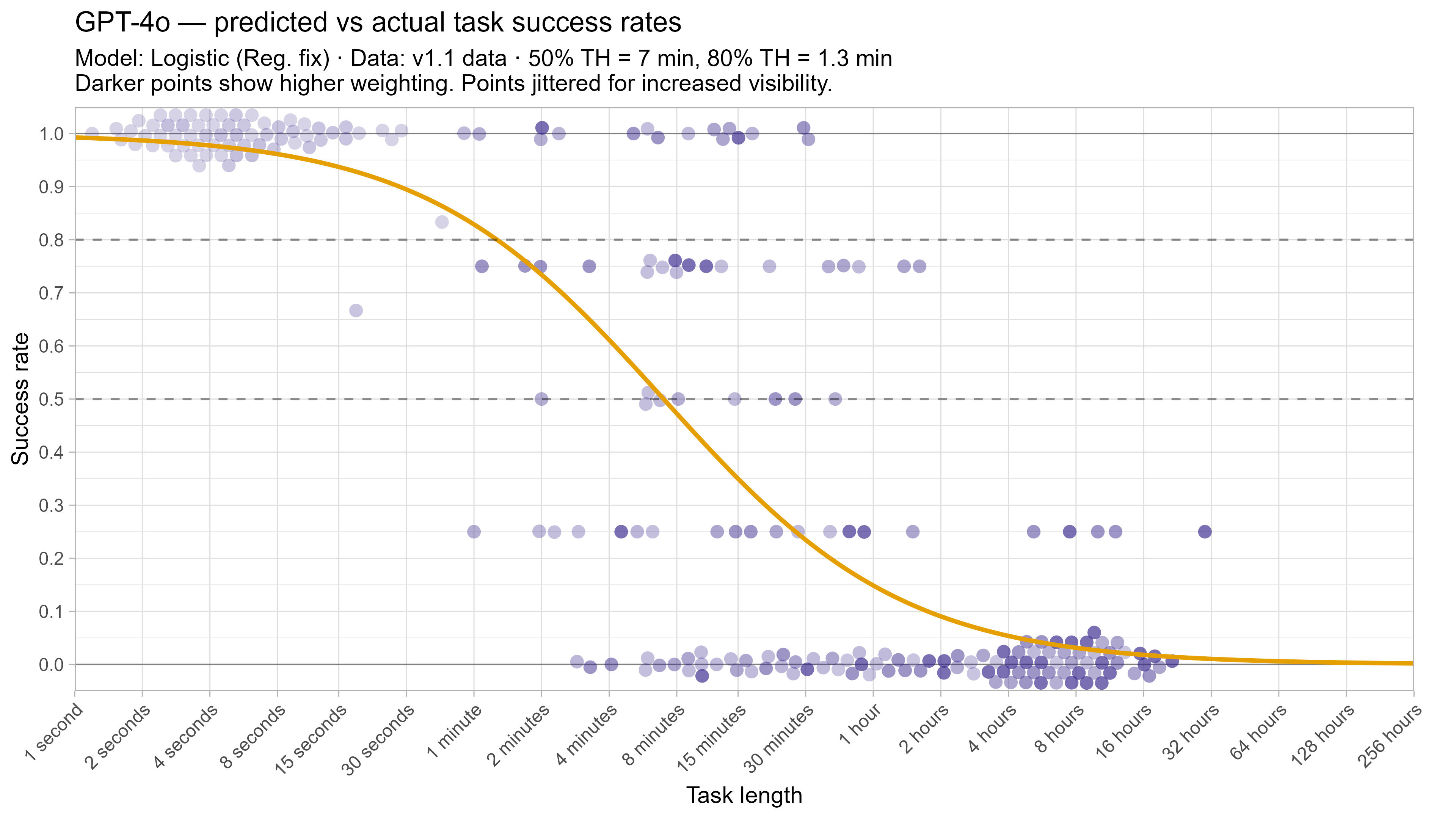
.png)
.png)
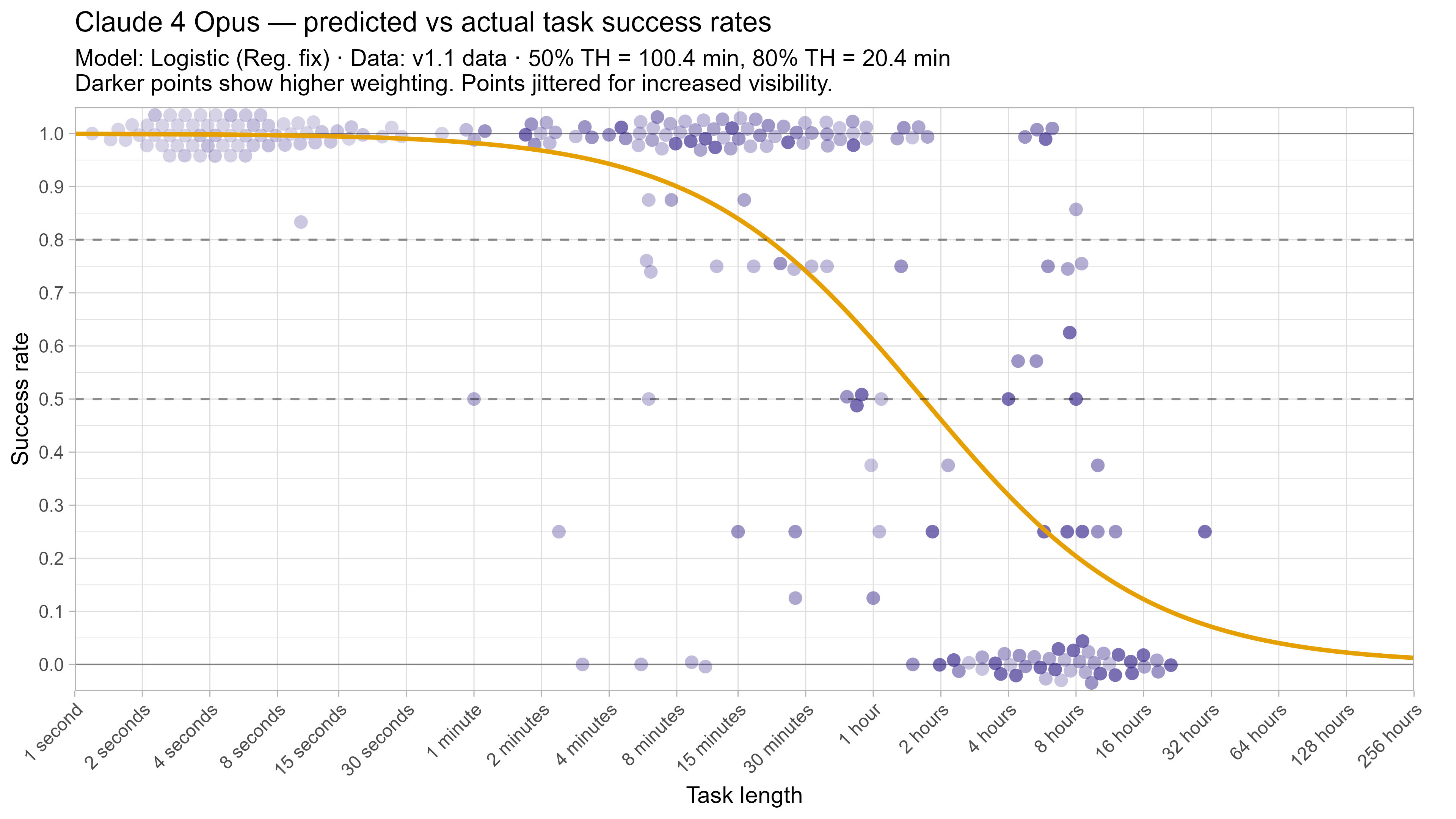
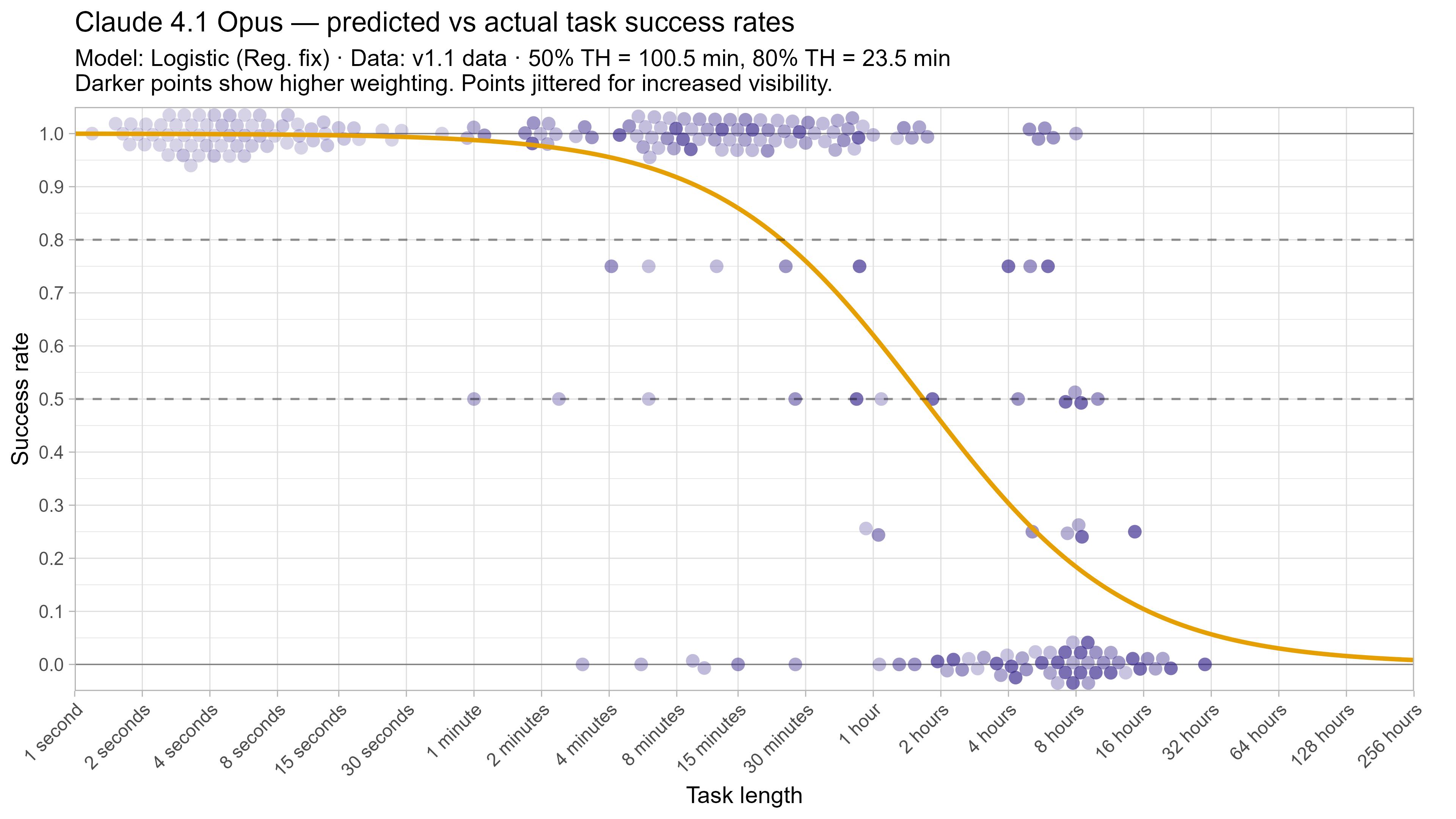
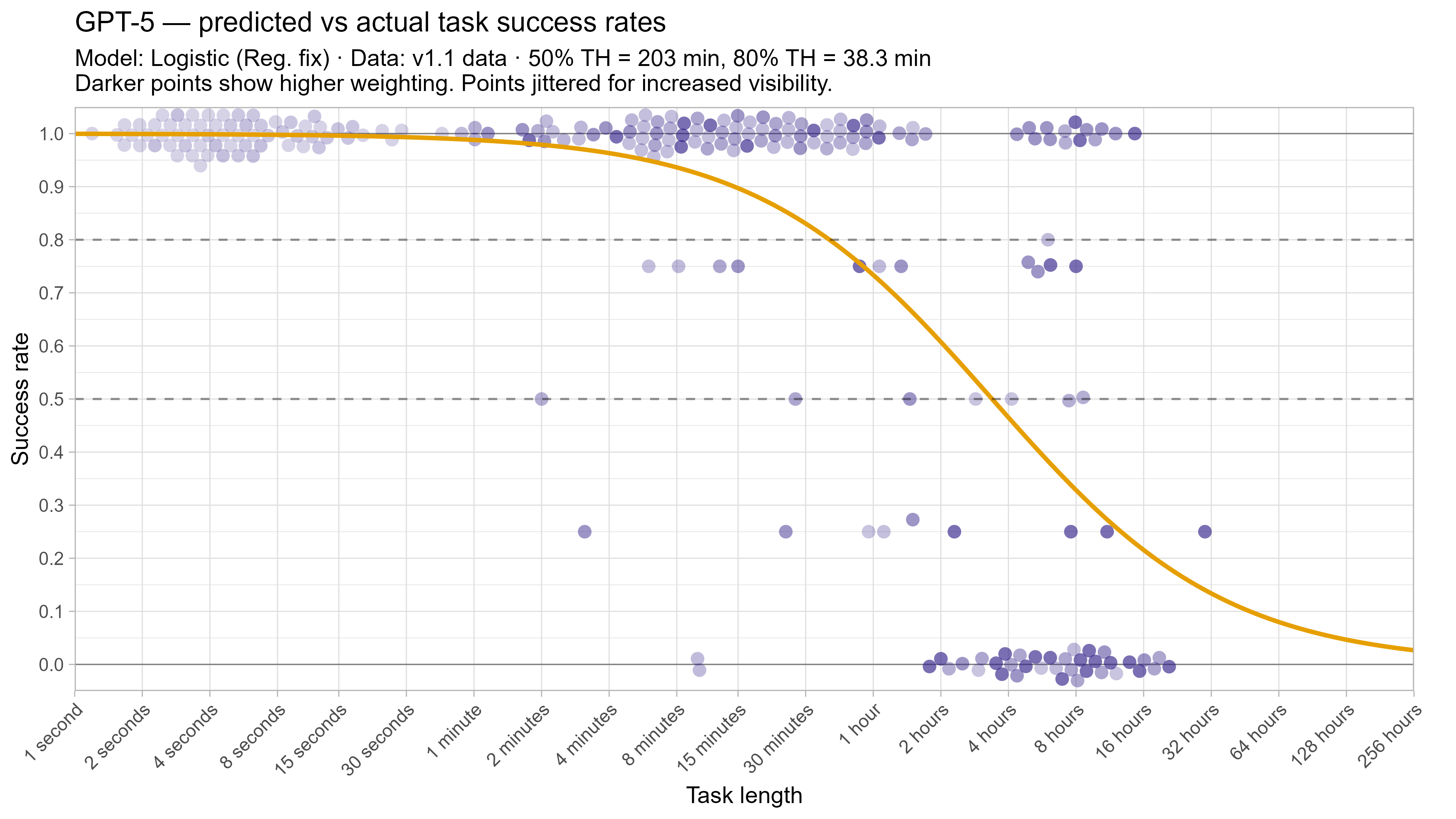
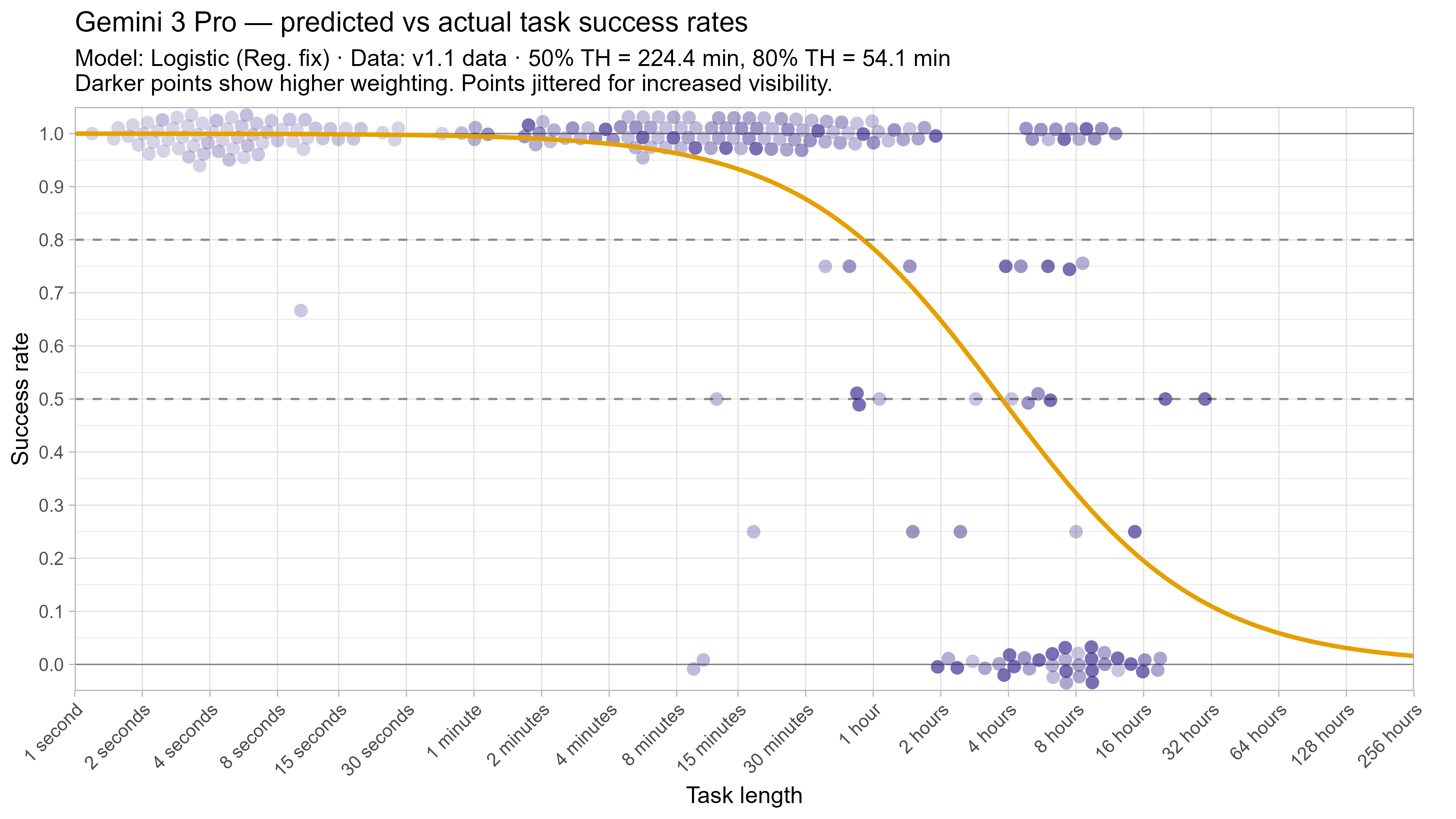
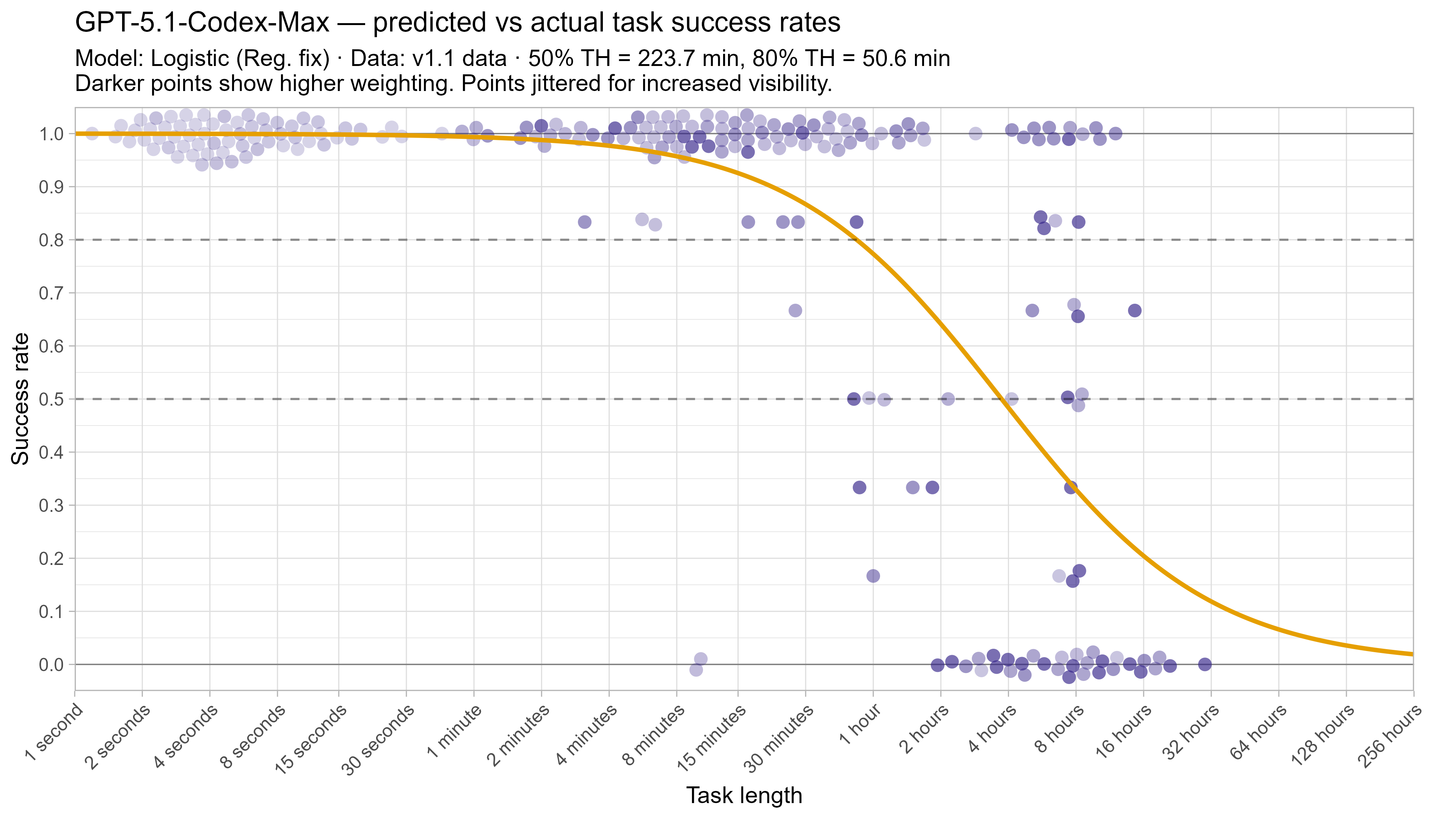
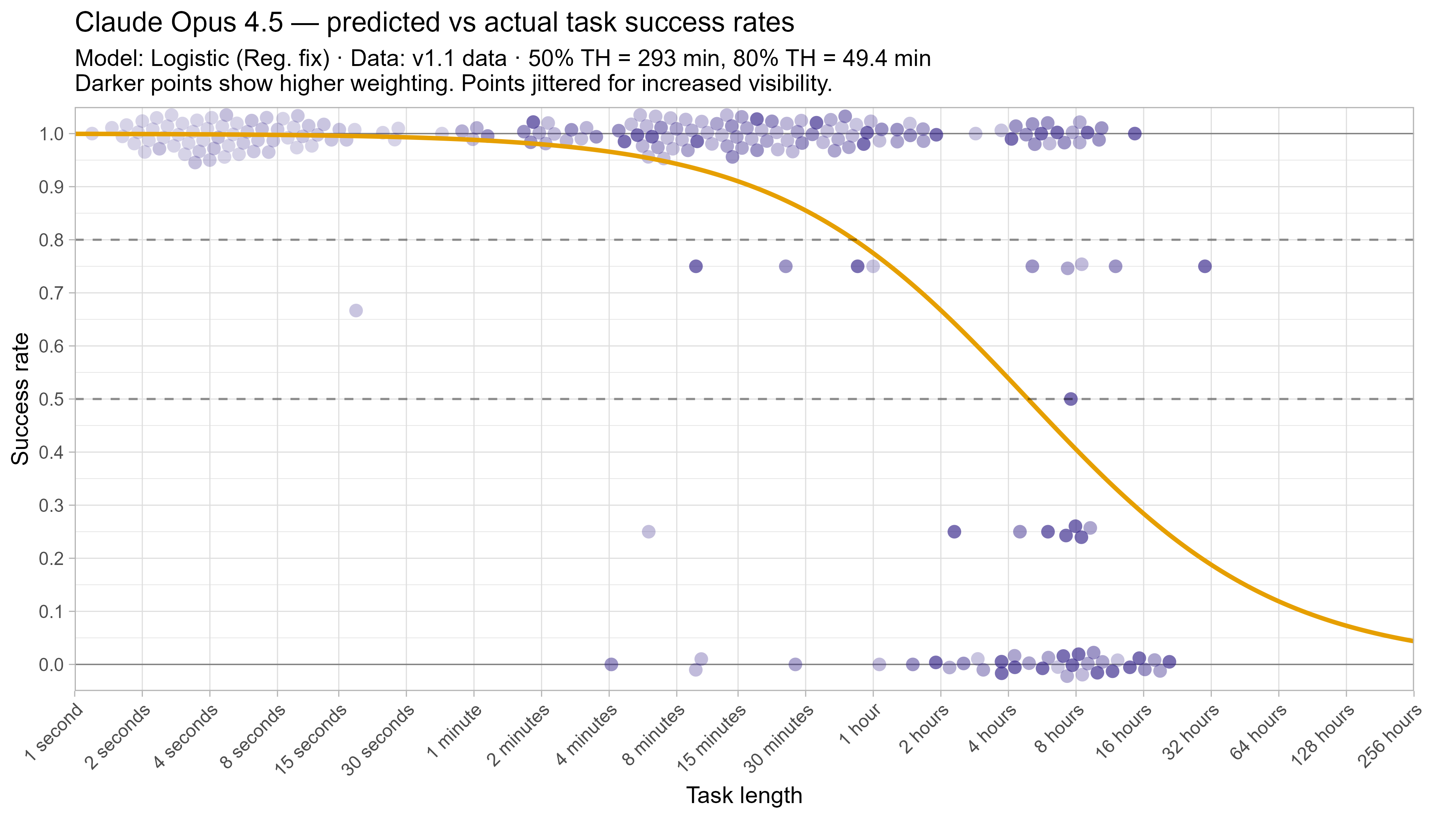
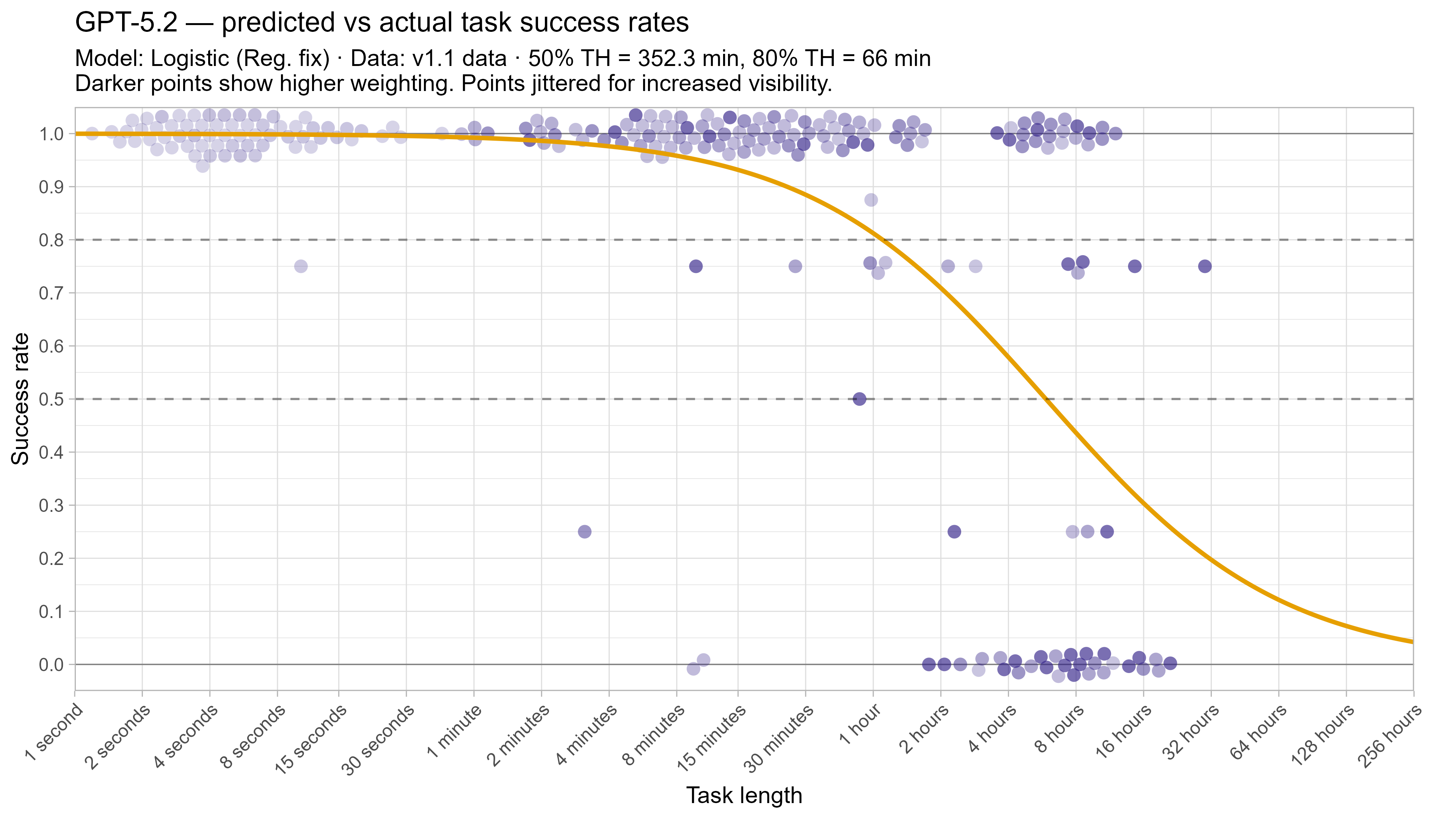
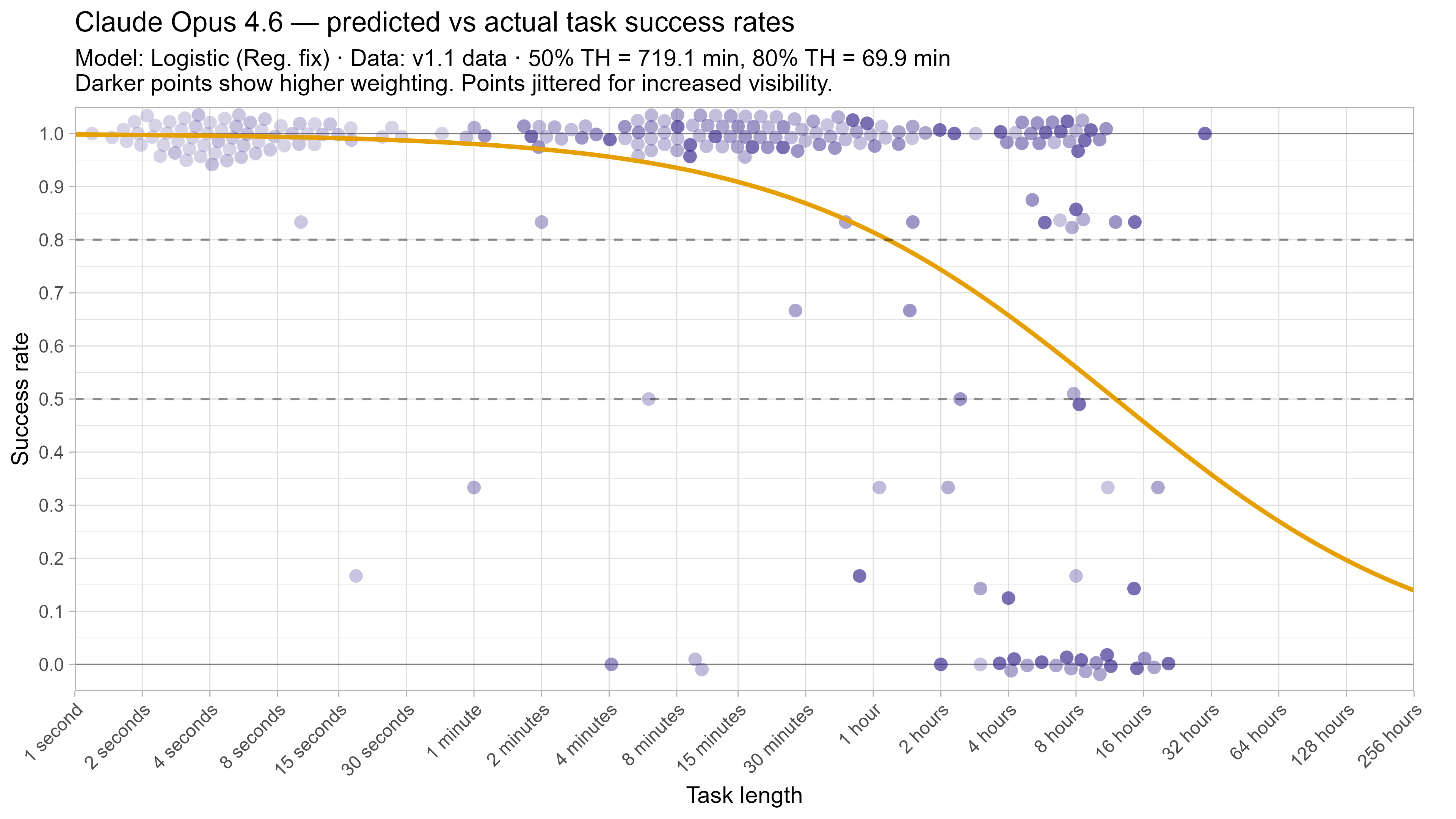
A3. SIMEX noise extrapolation curves — 50% Time Horizon
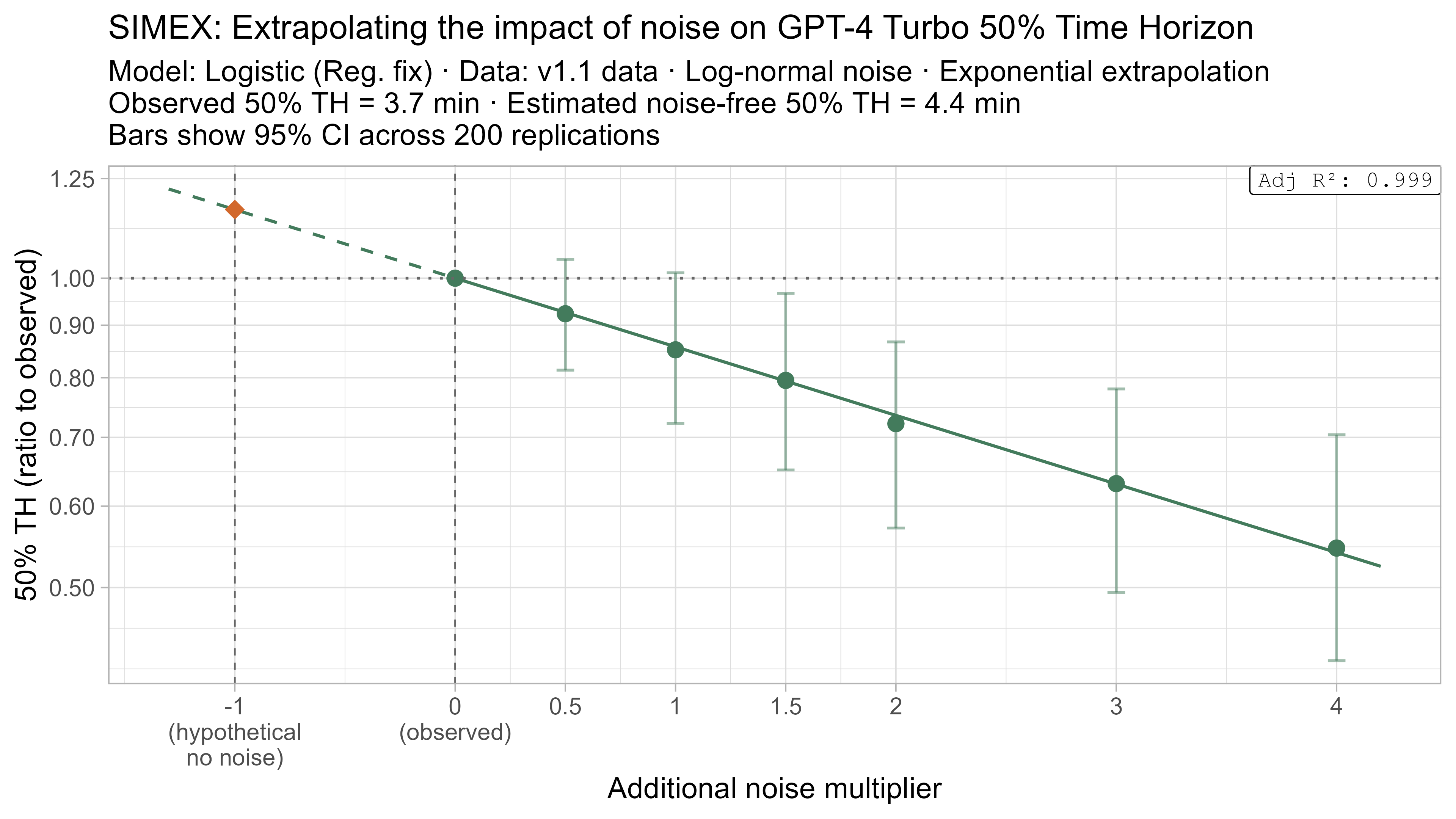
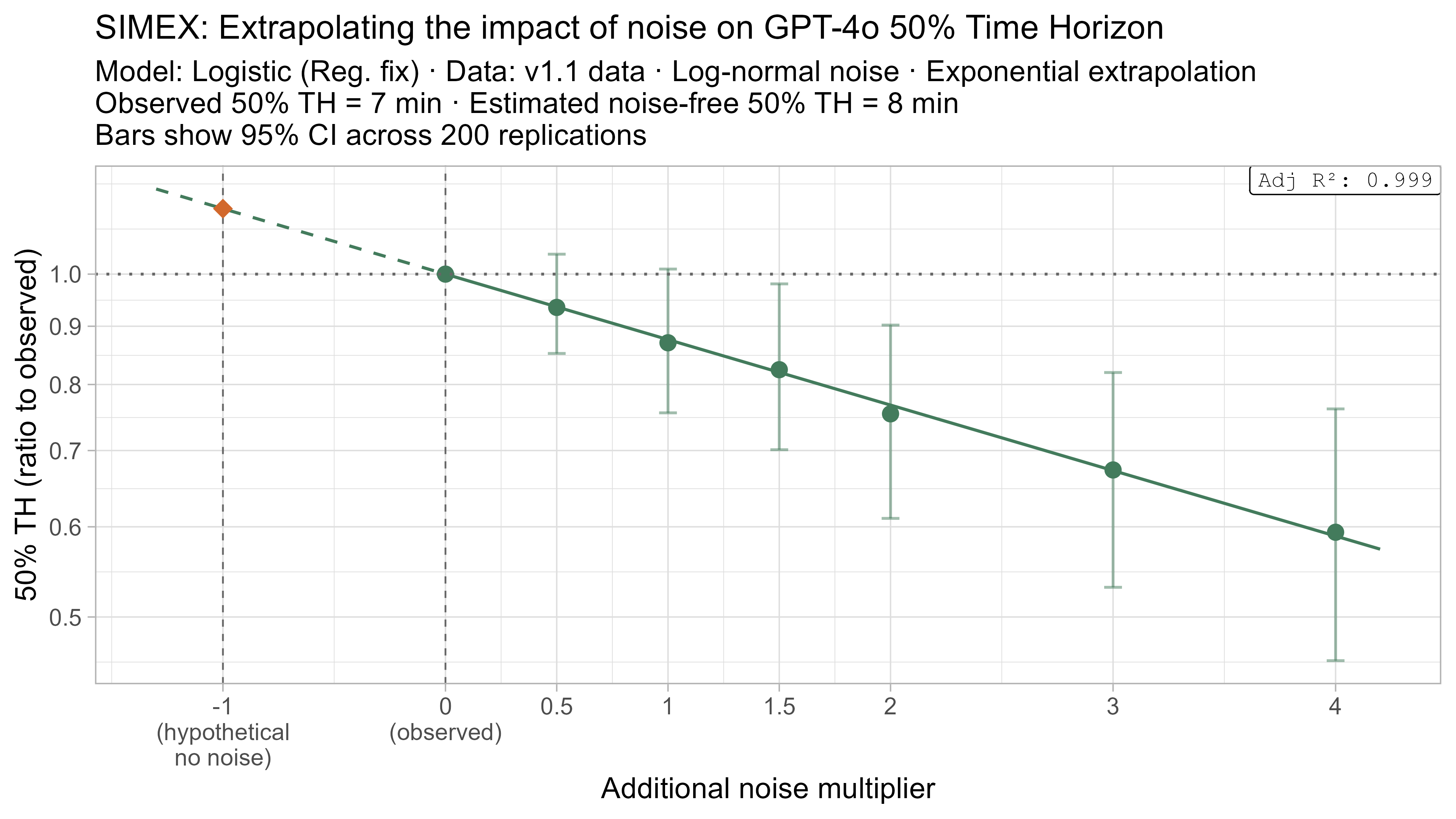
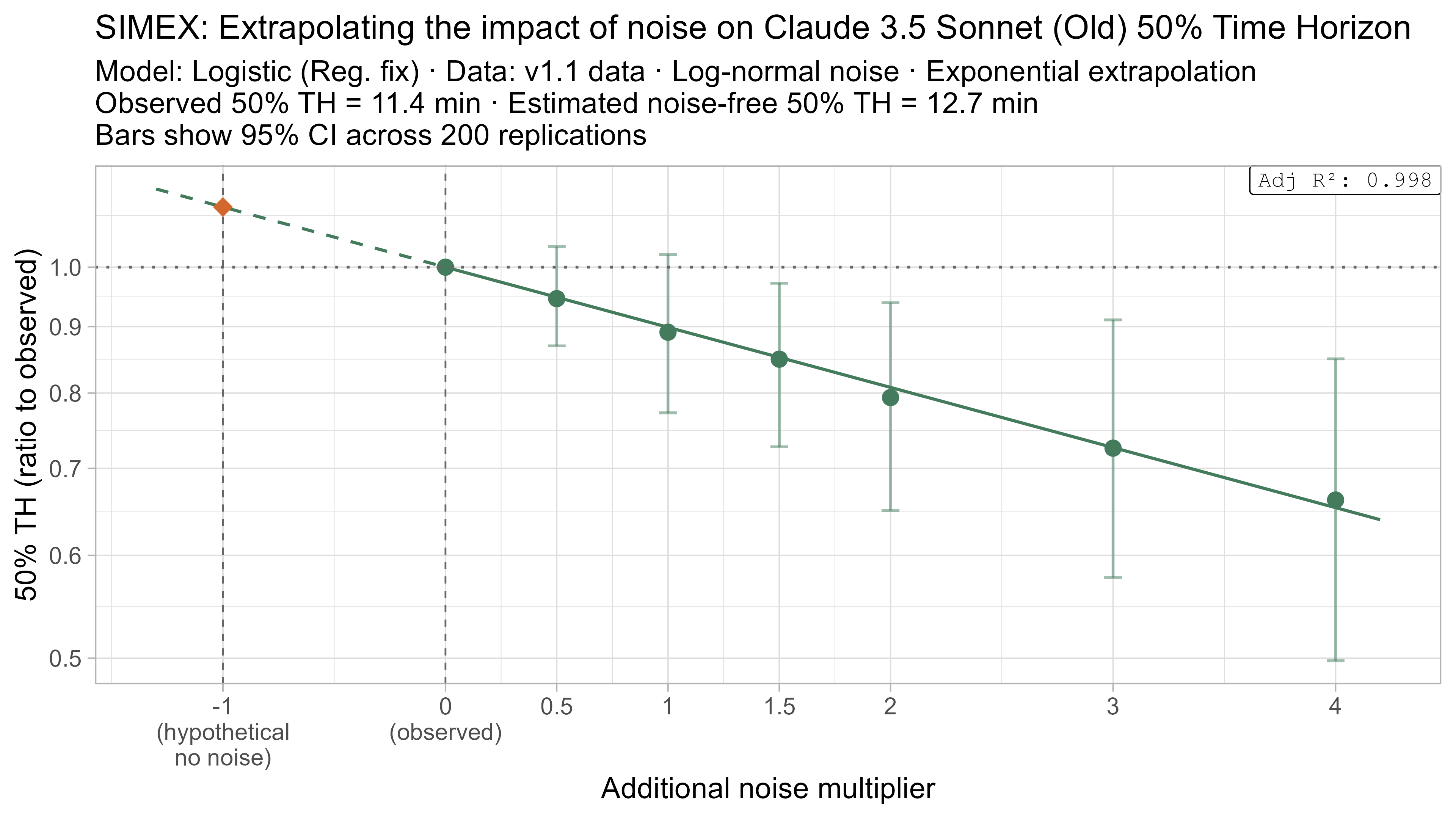
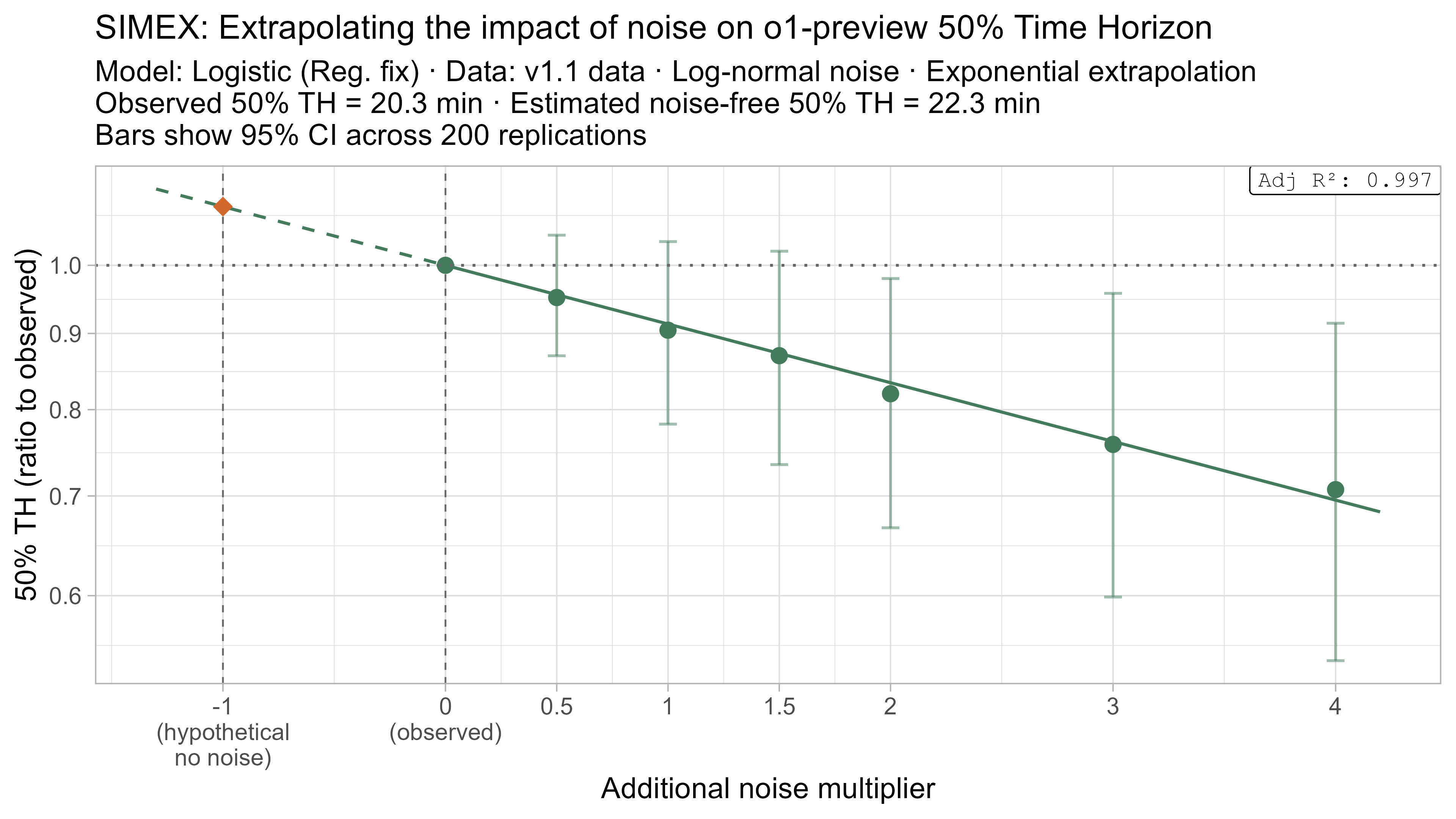
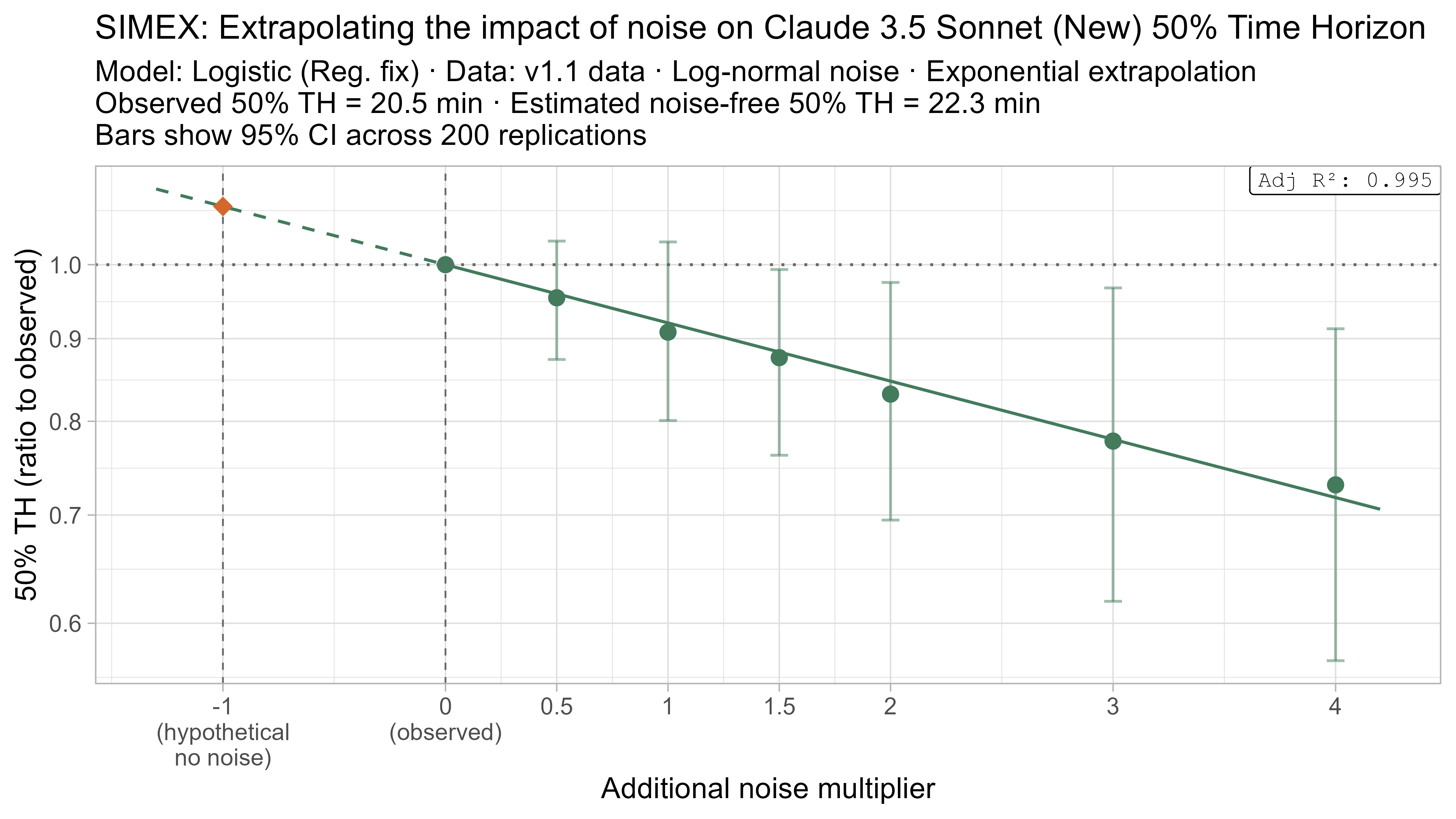
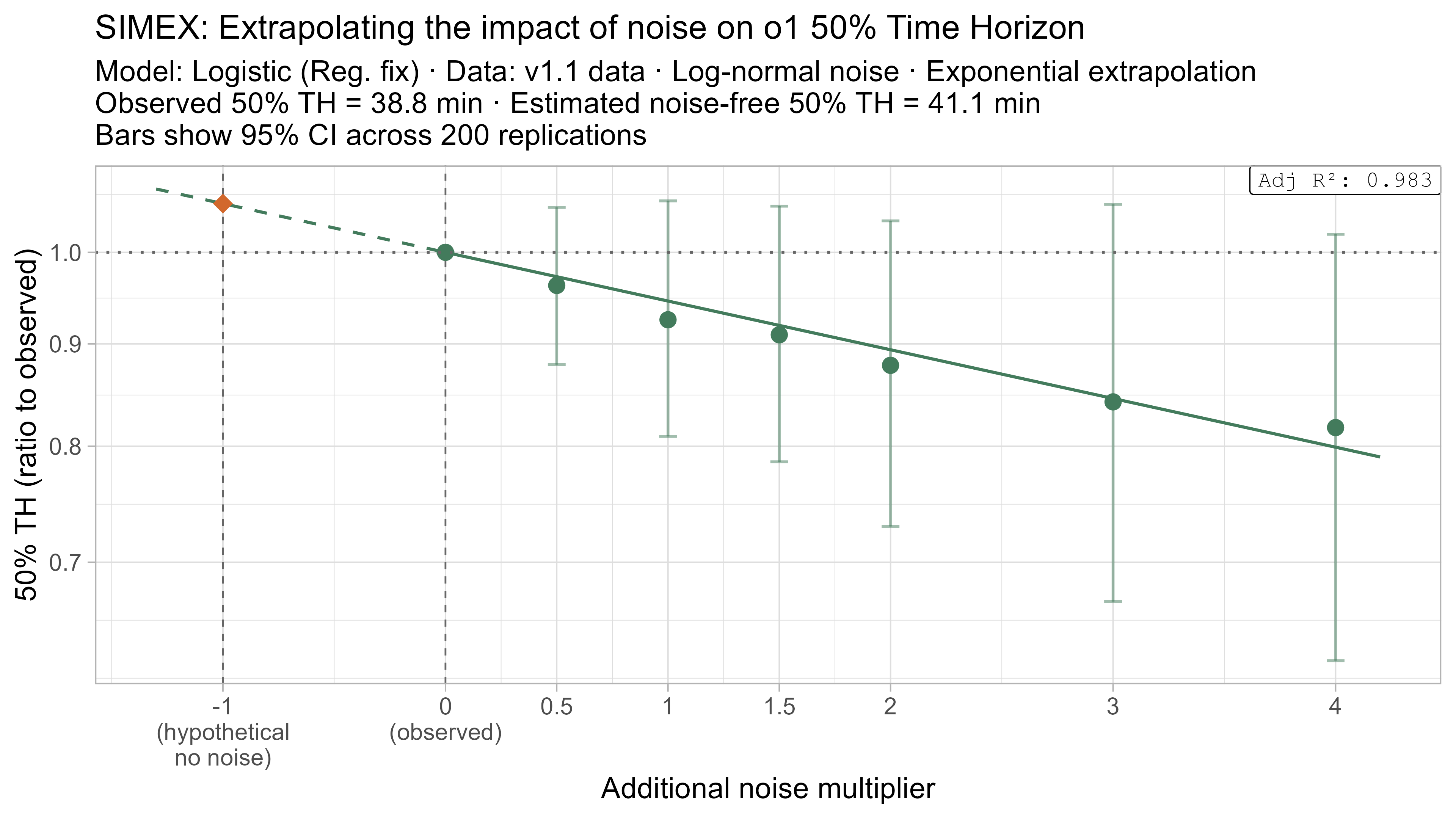
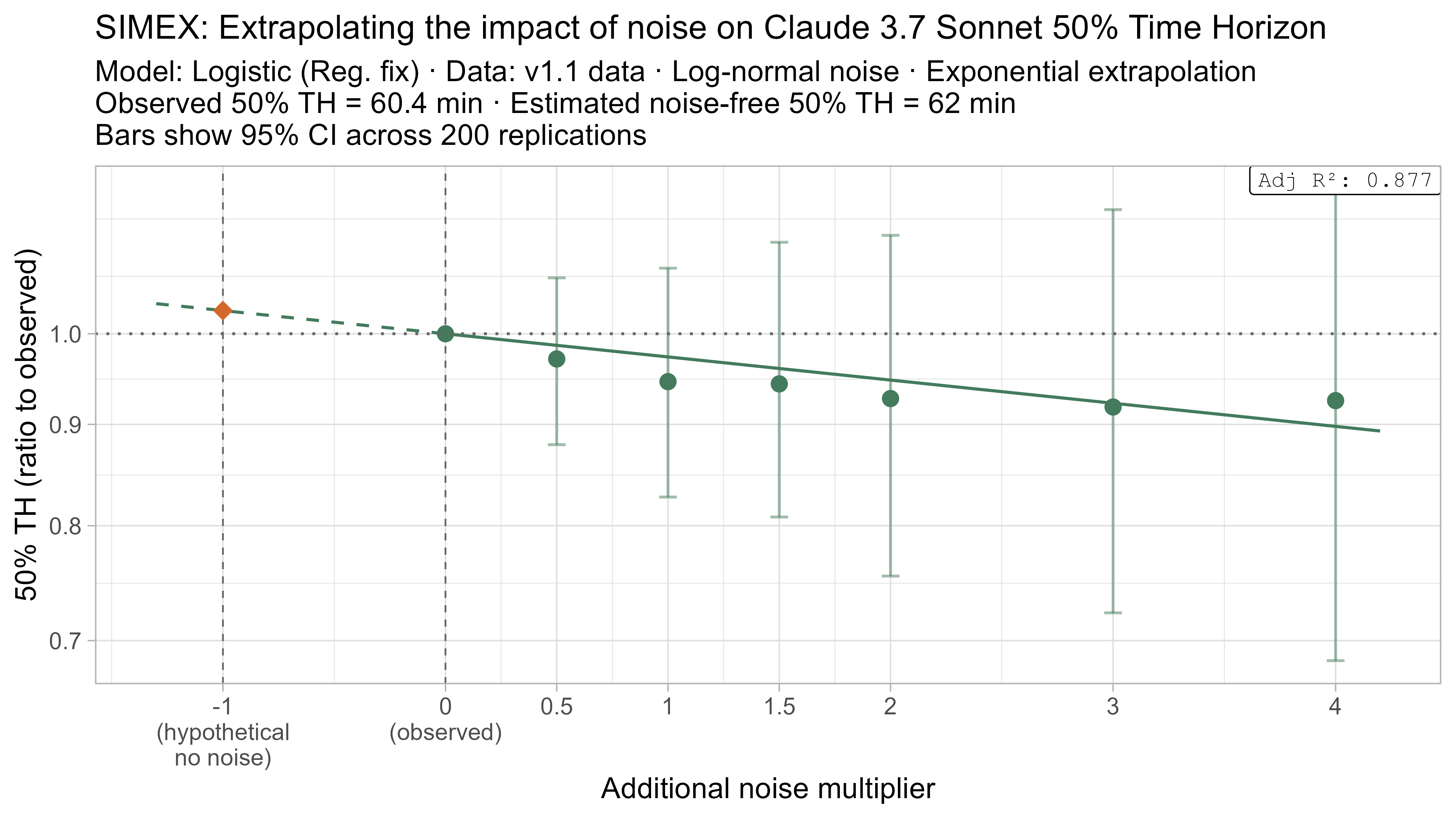
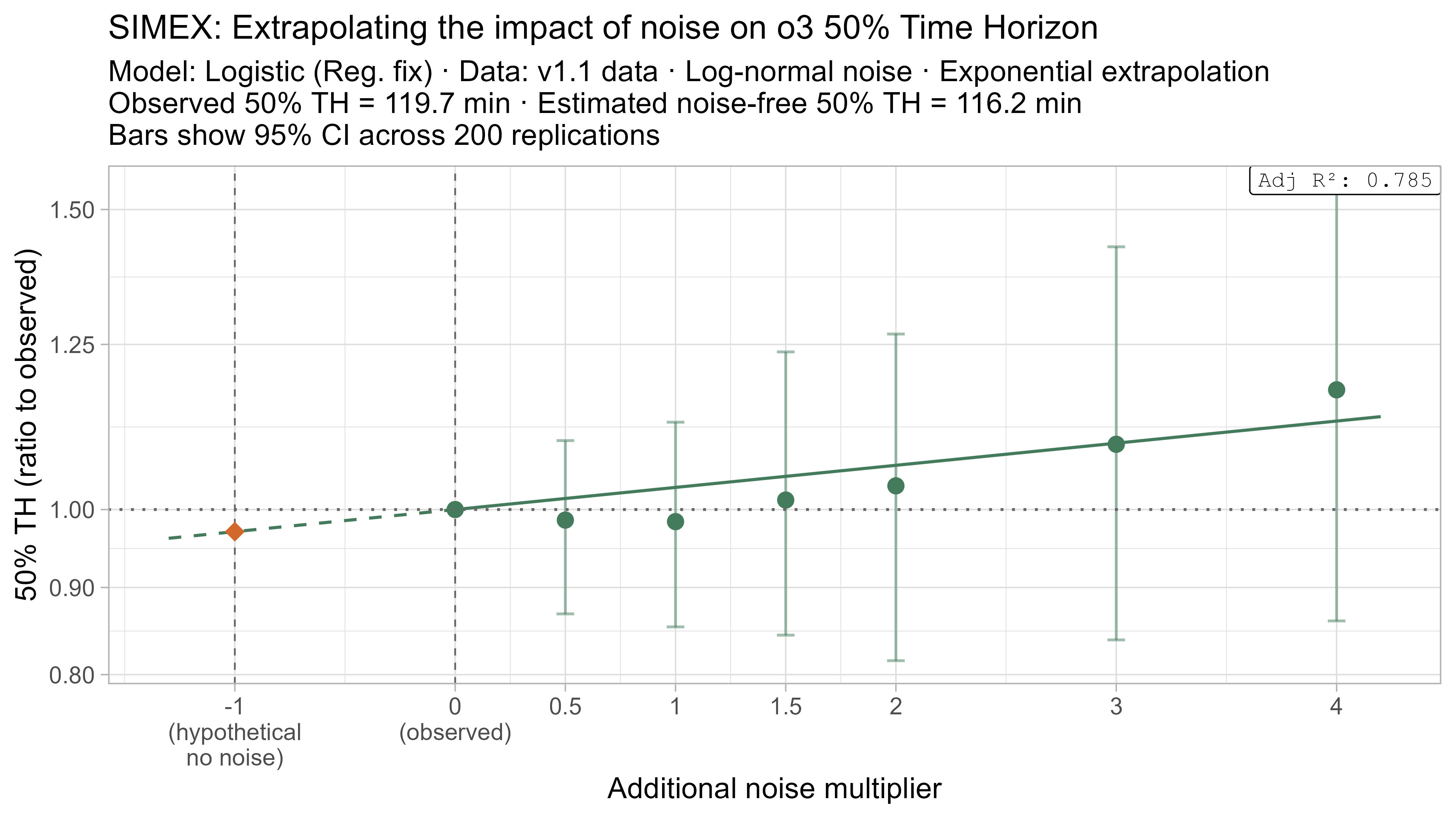
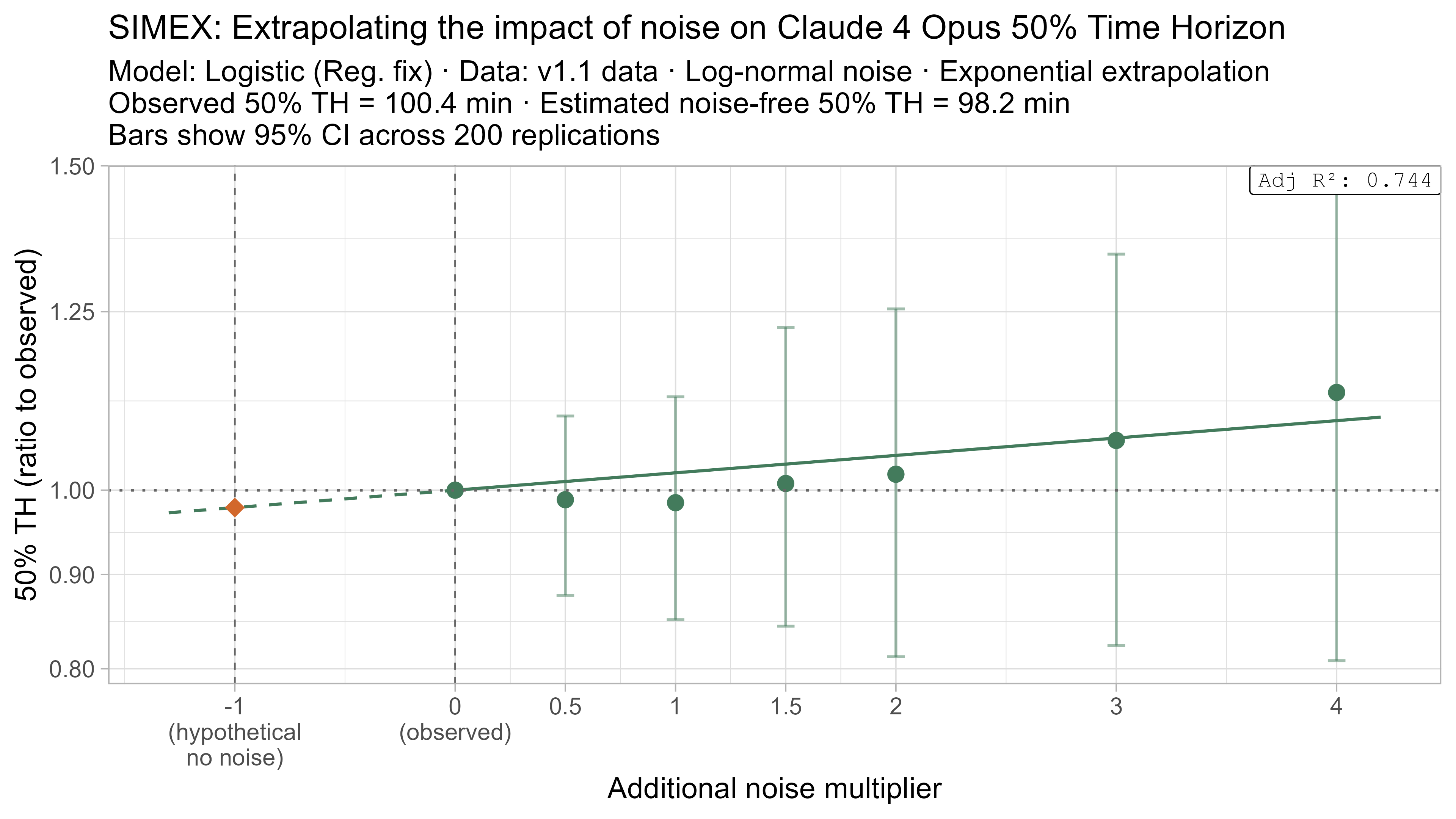
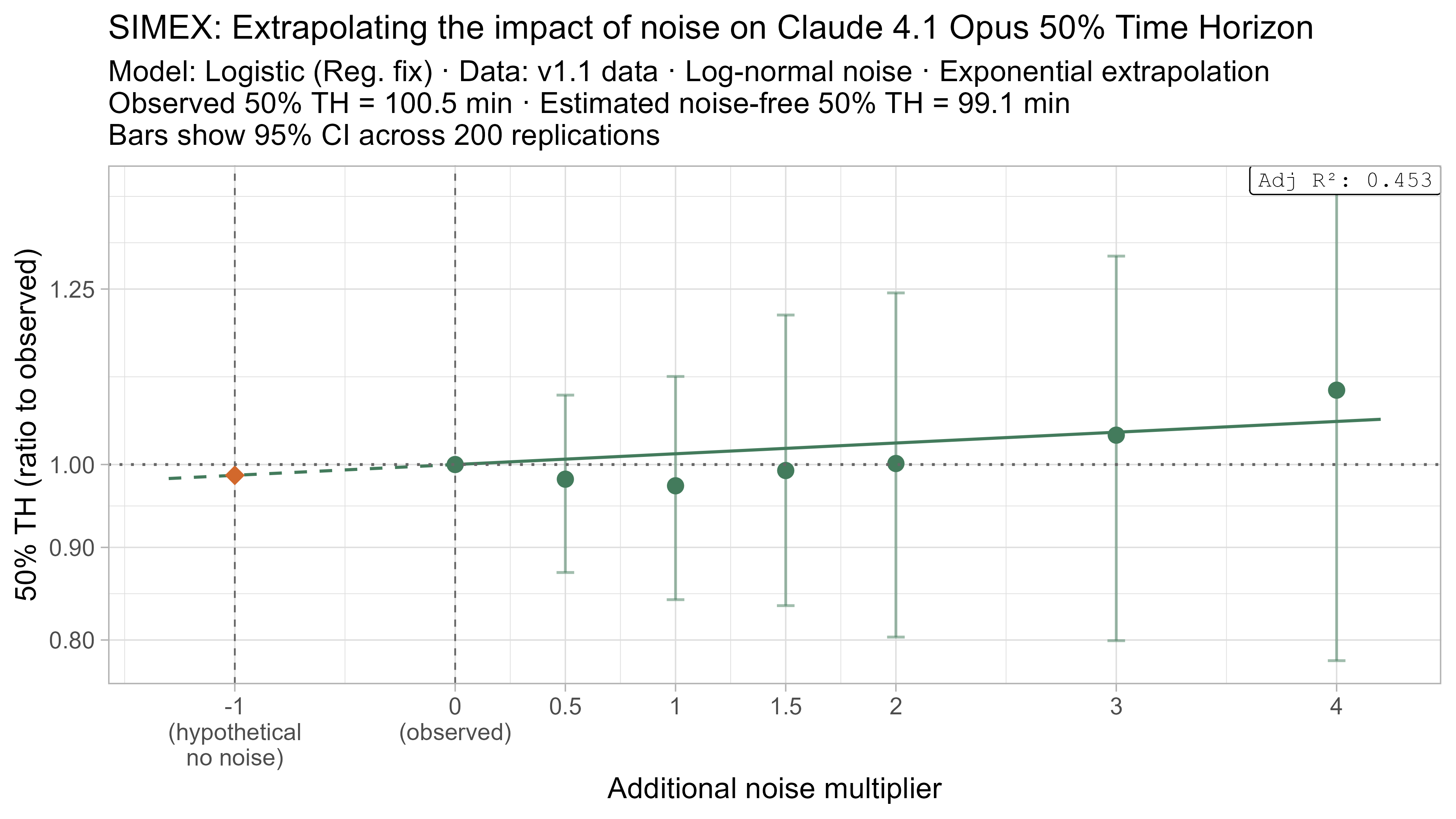
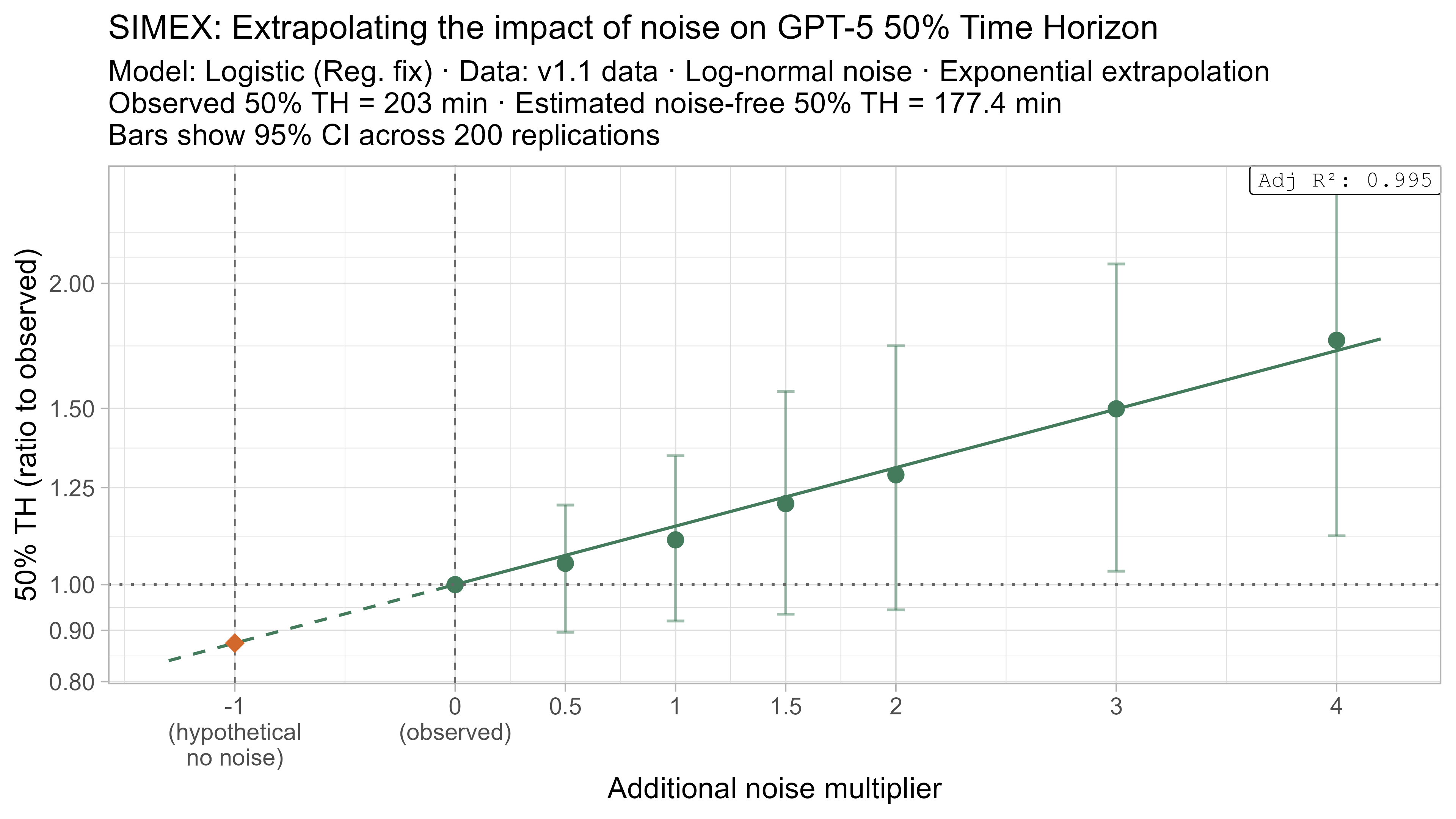
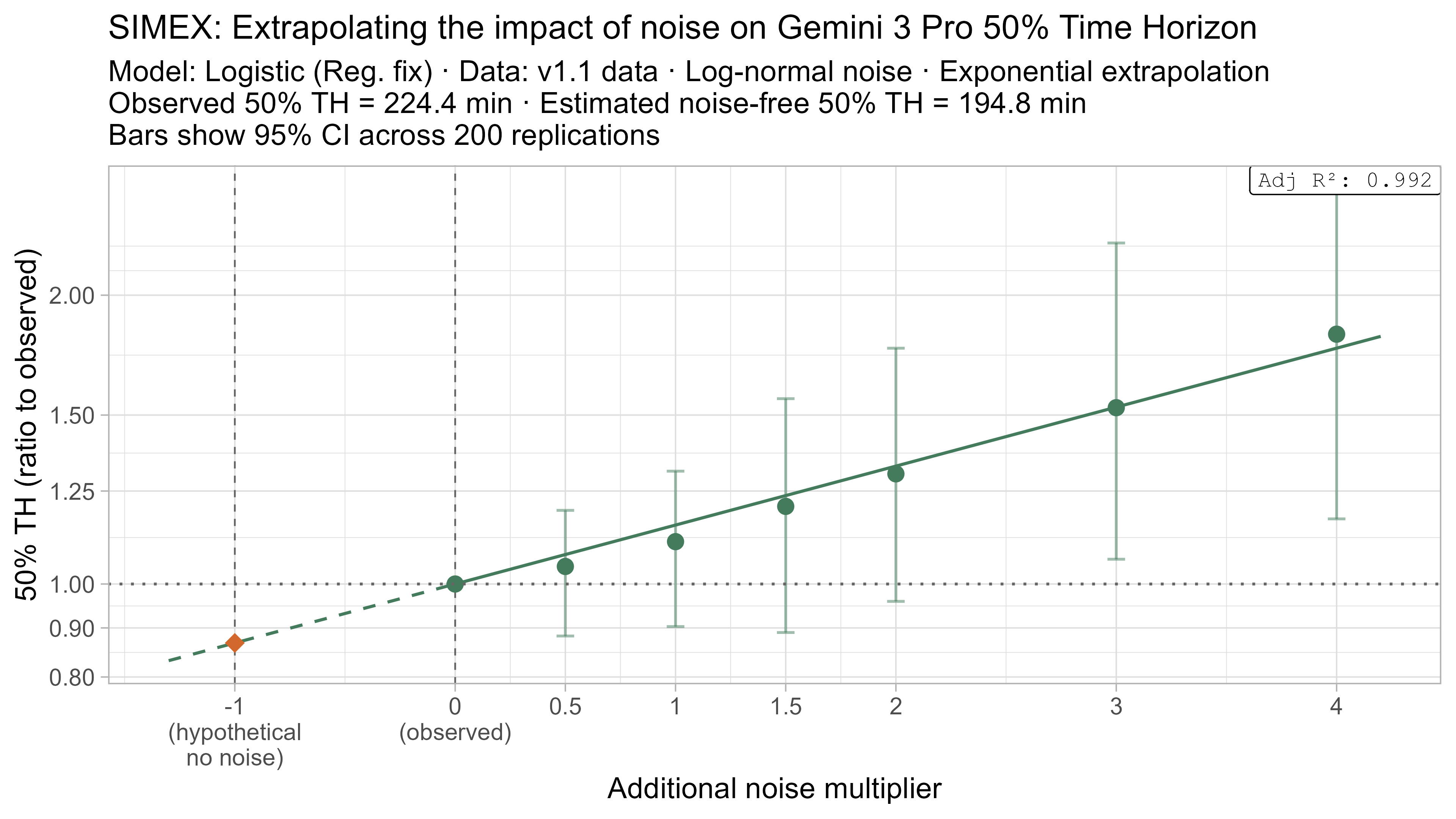
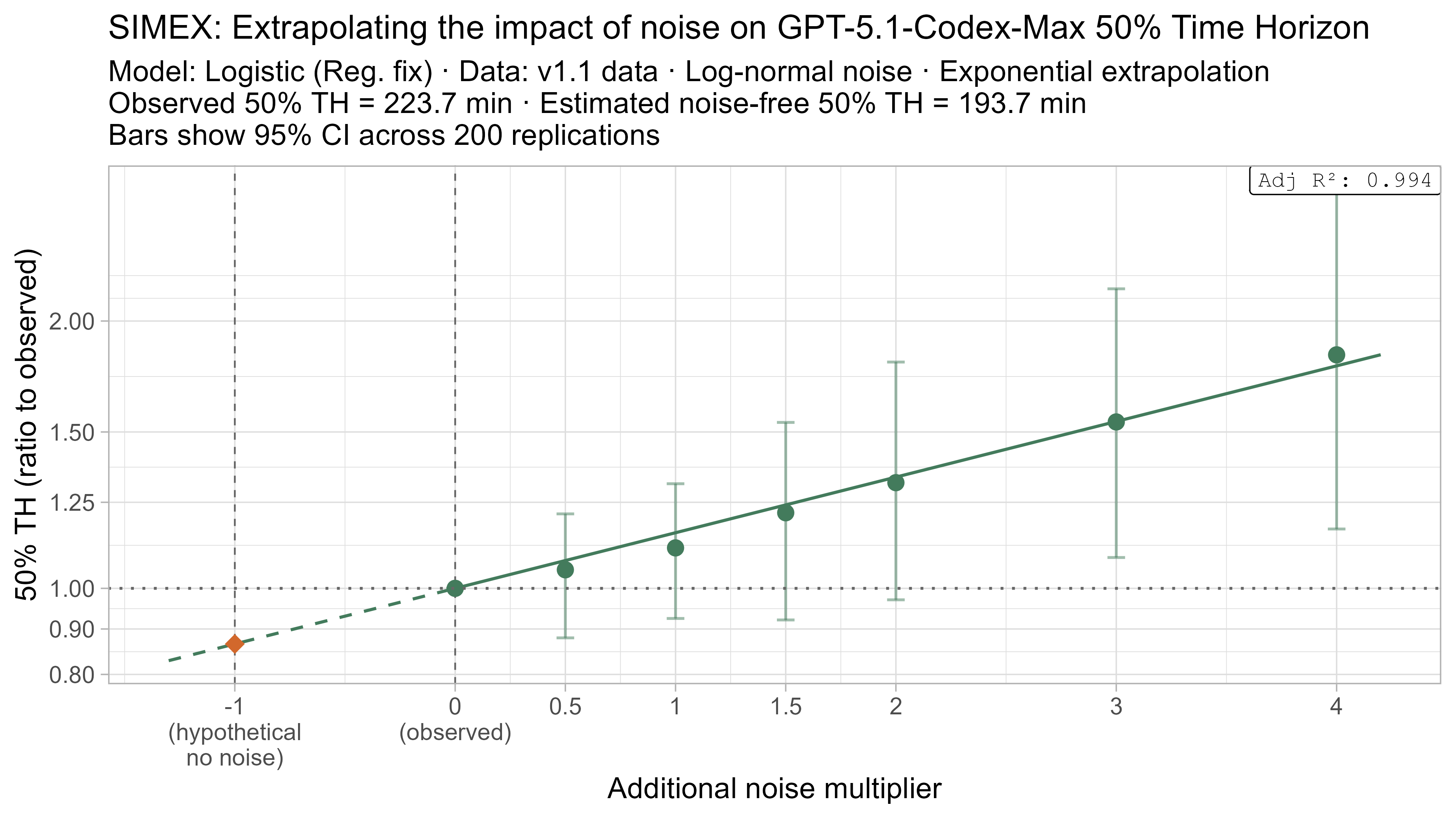
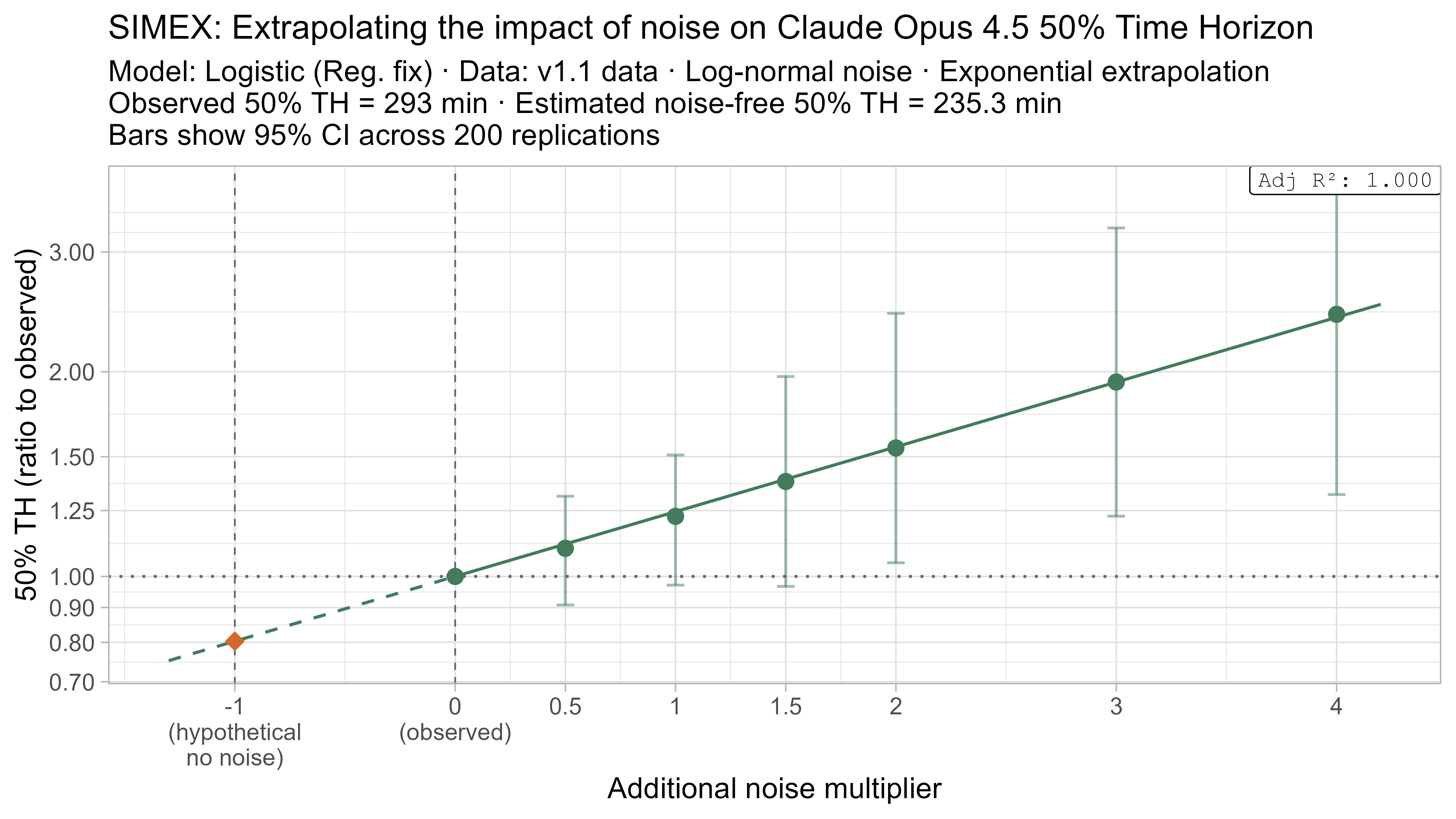
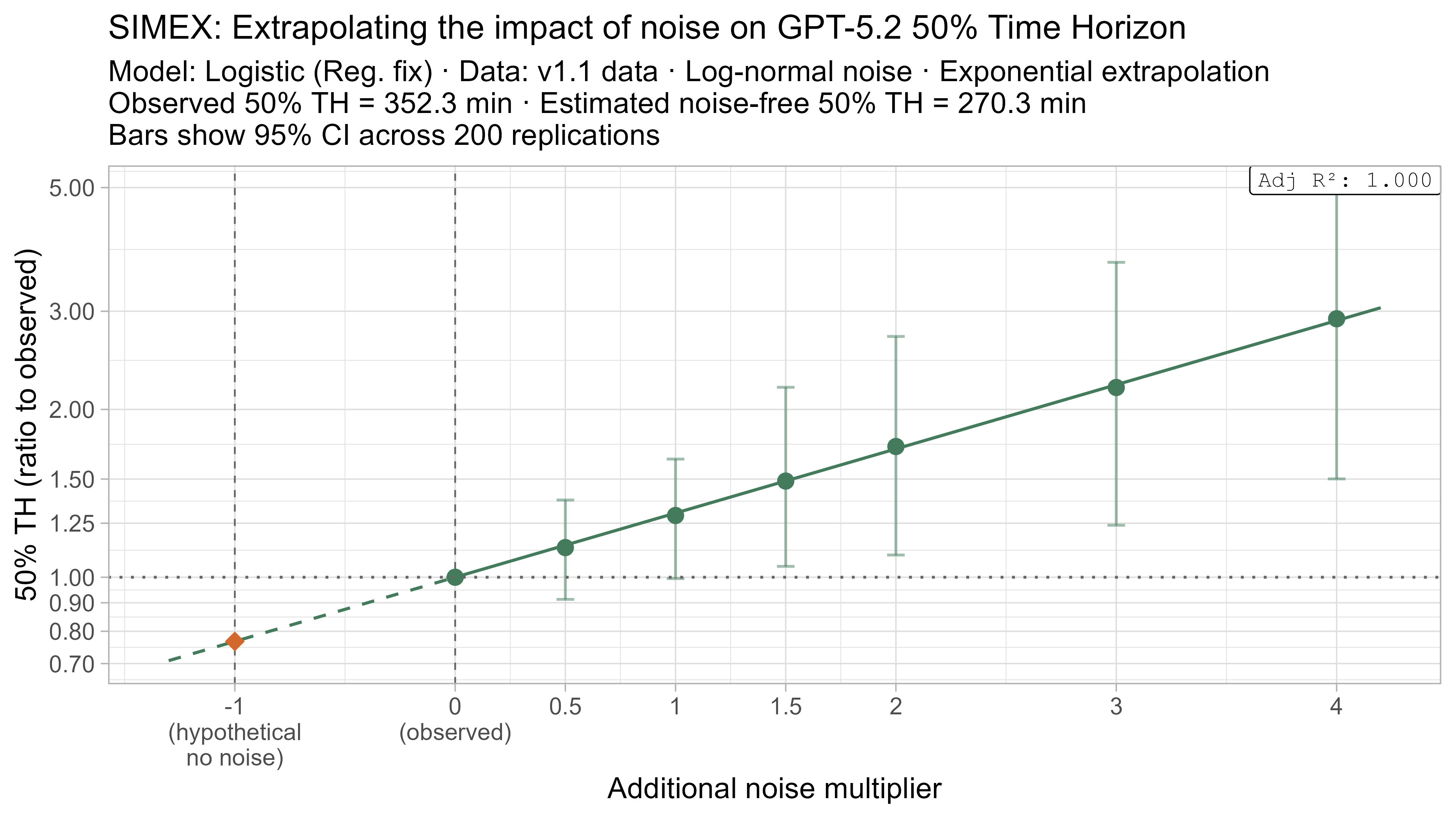
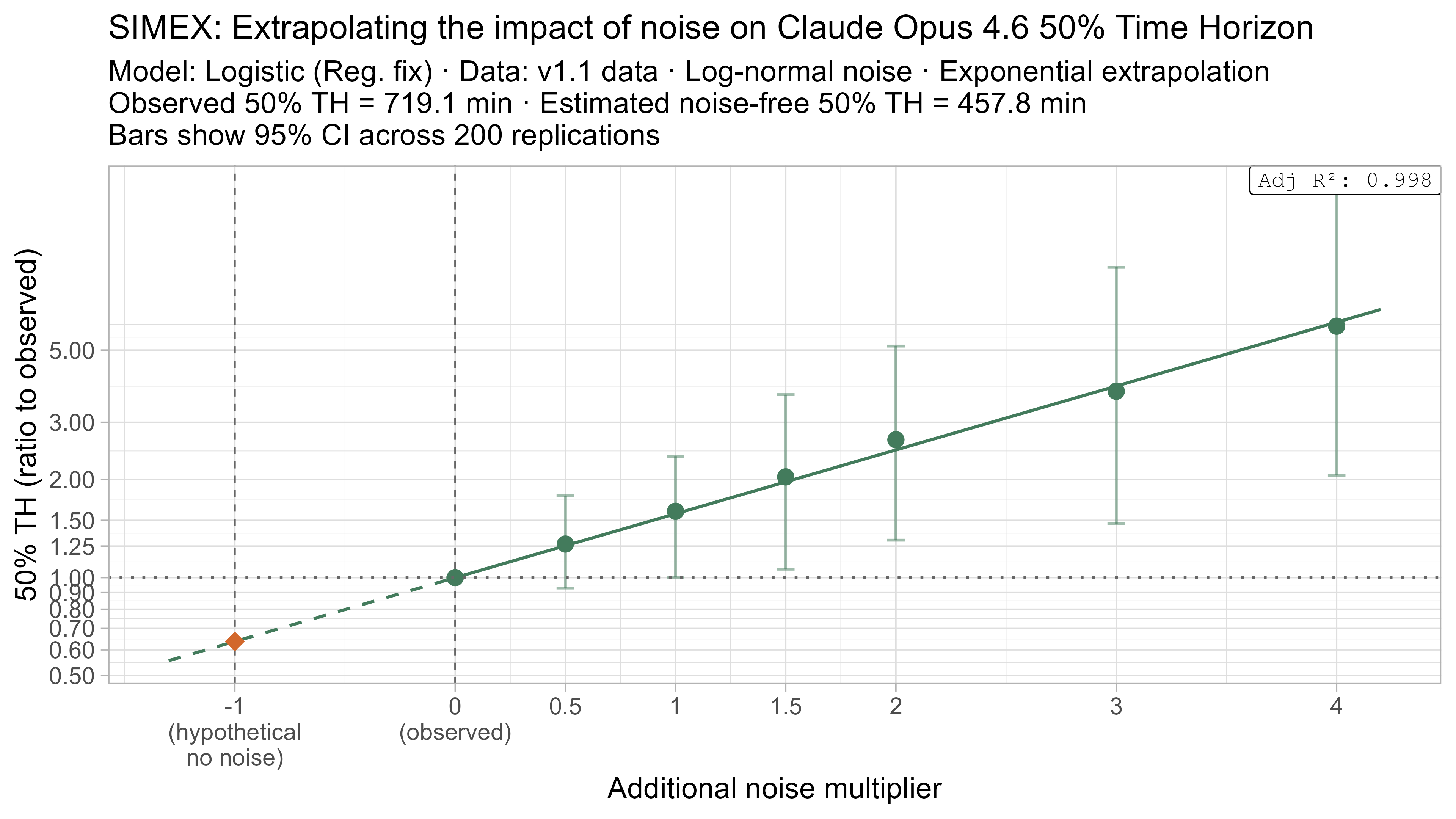
A4. SIMEX noise extrapolation curves — 80% Time Horizon
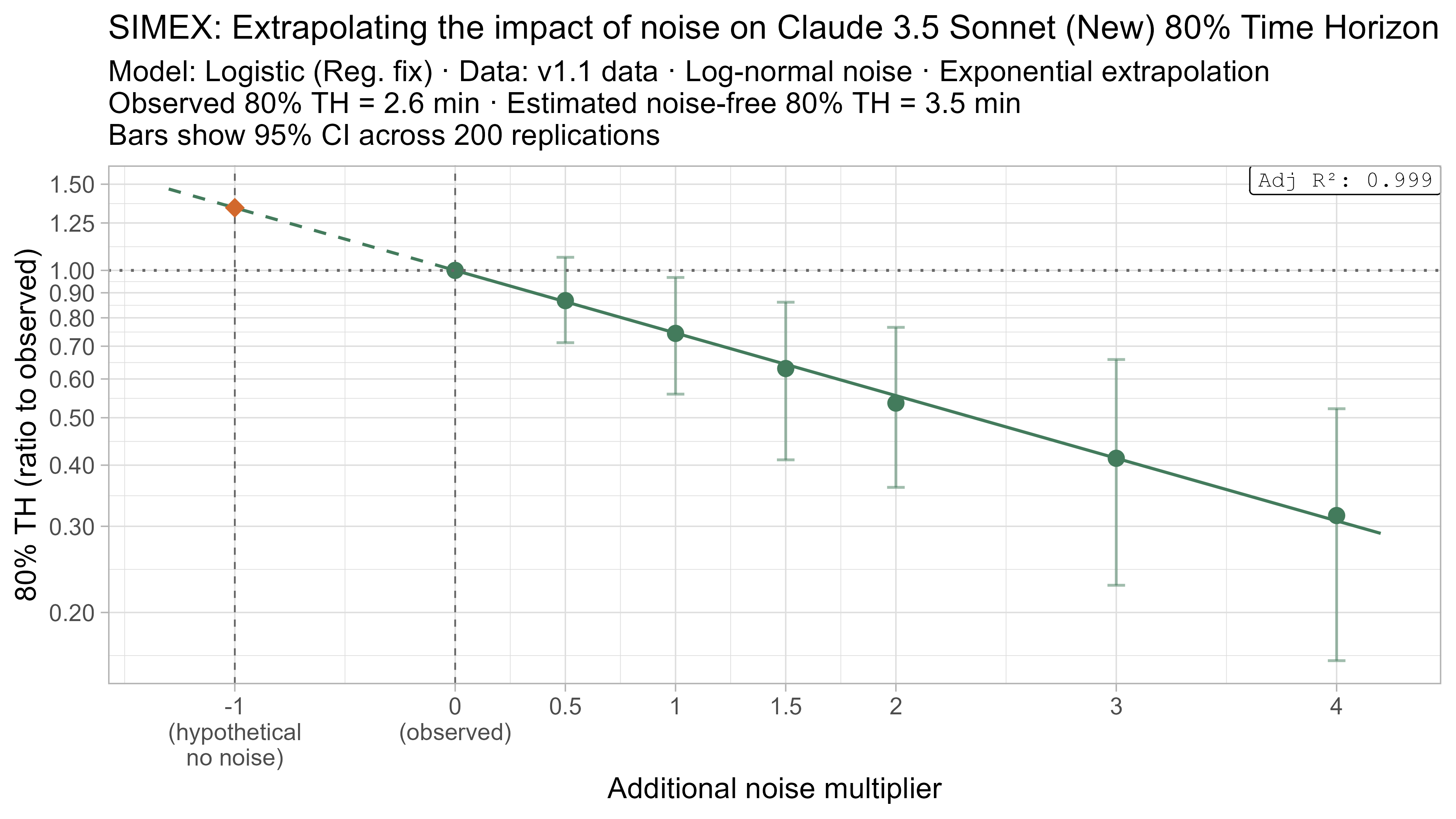
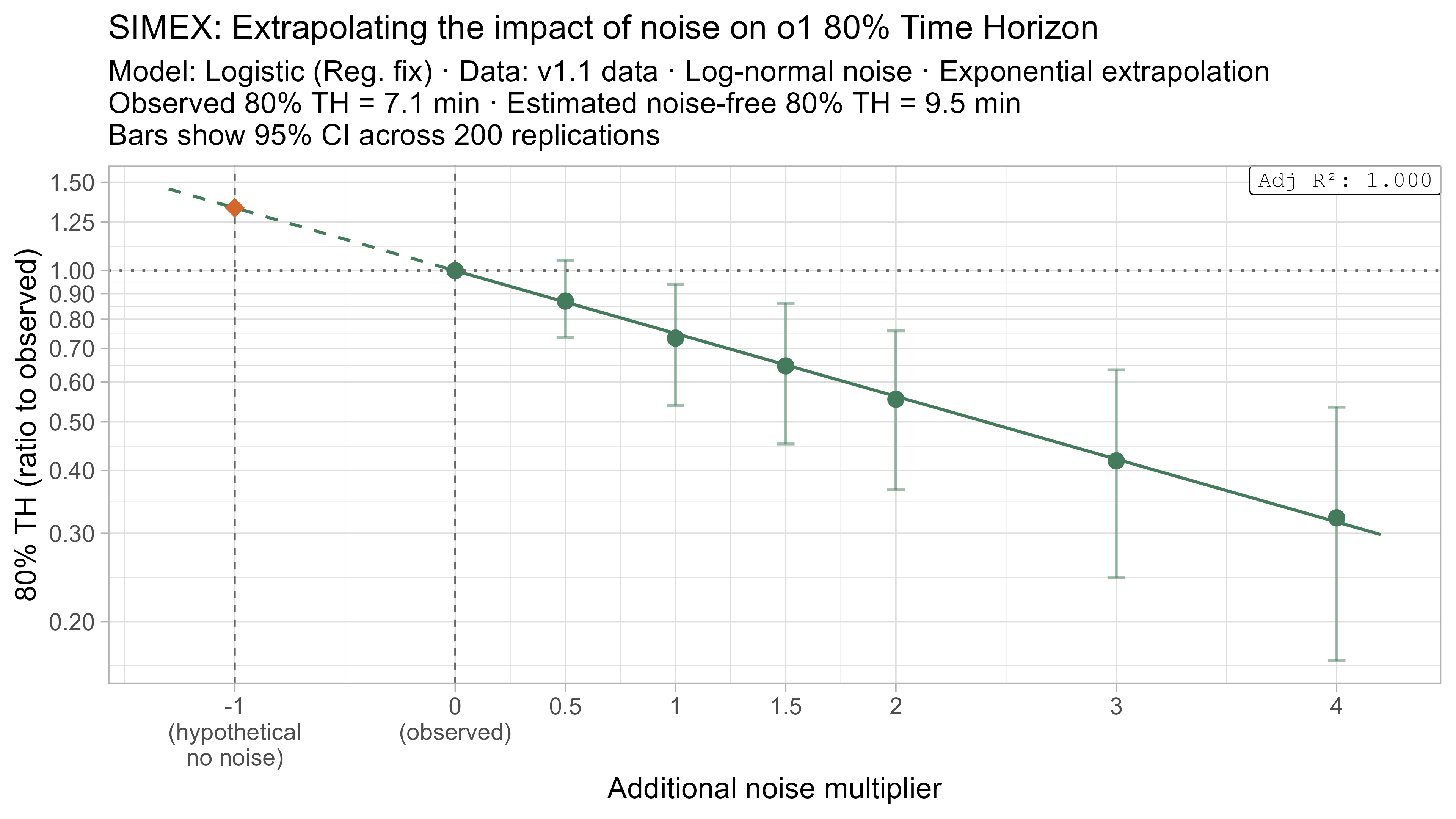
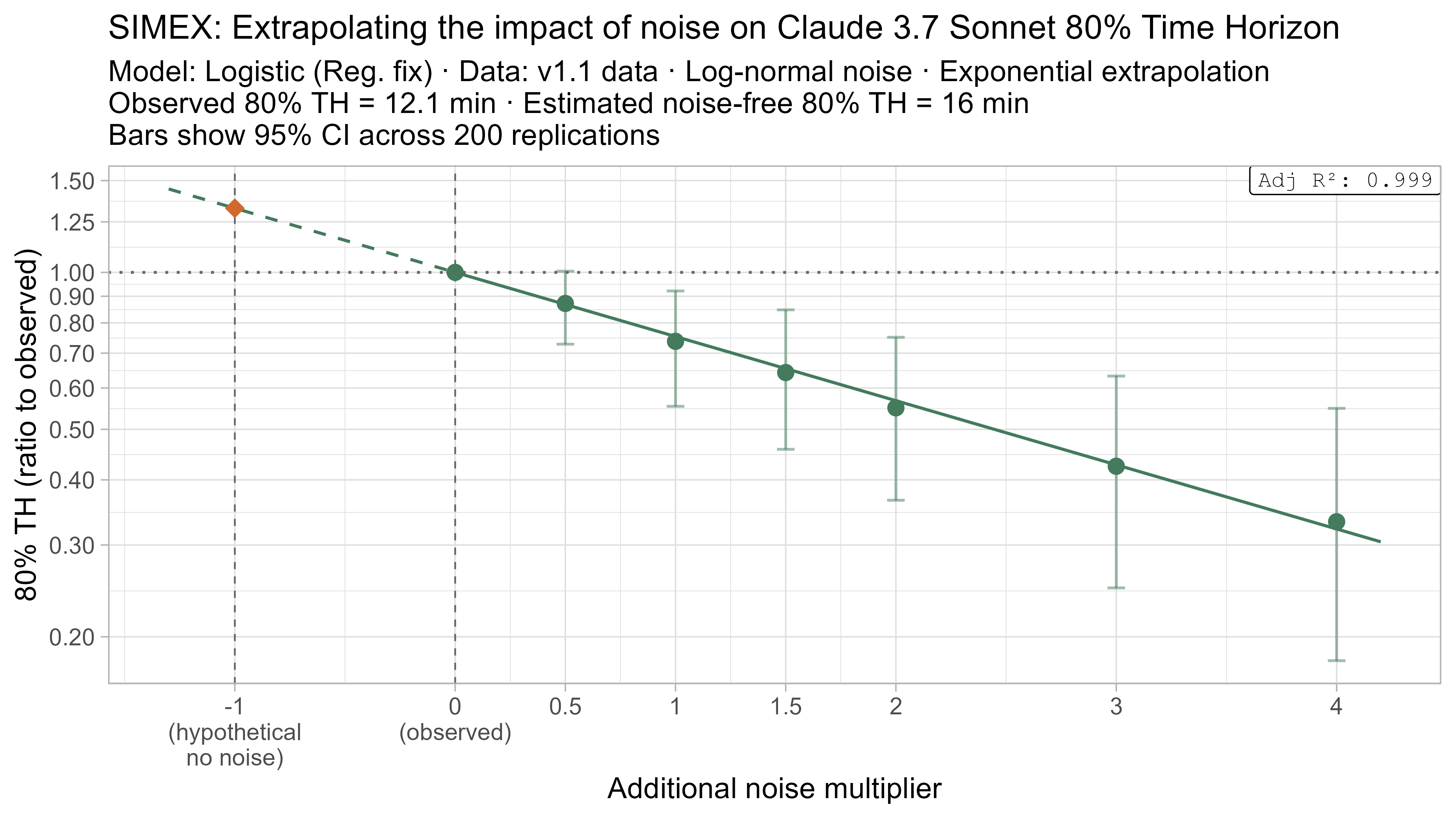
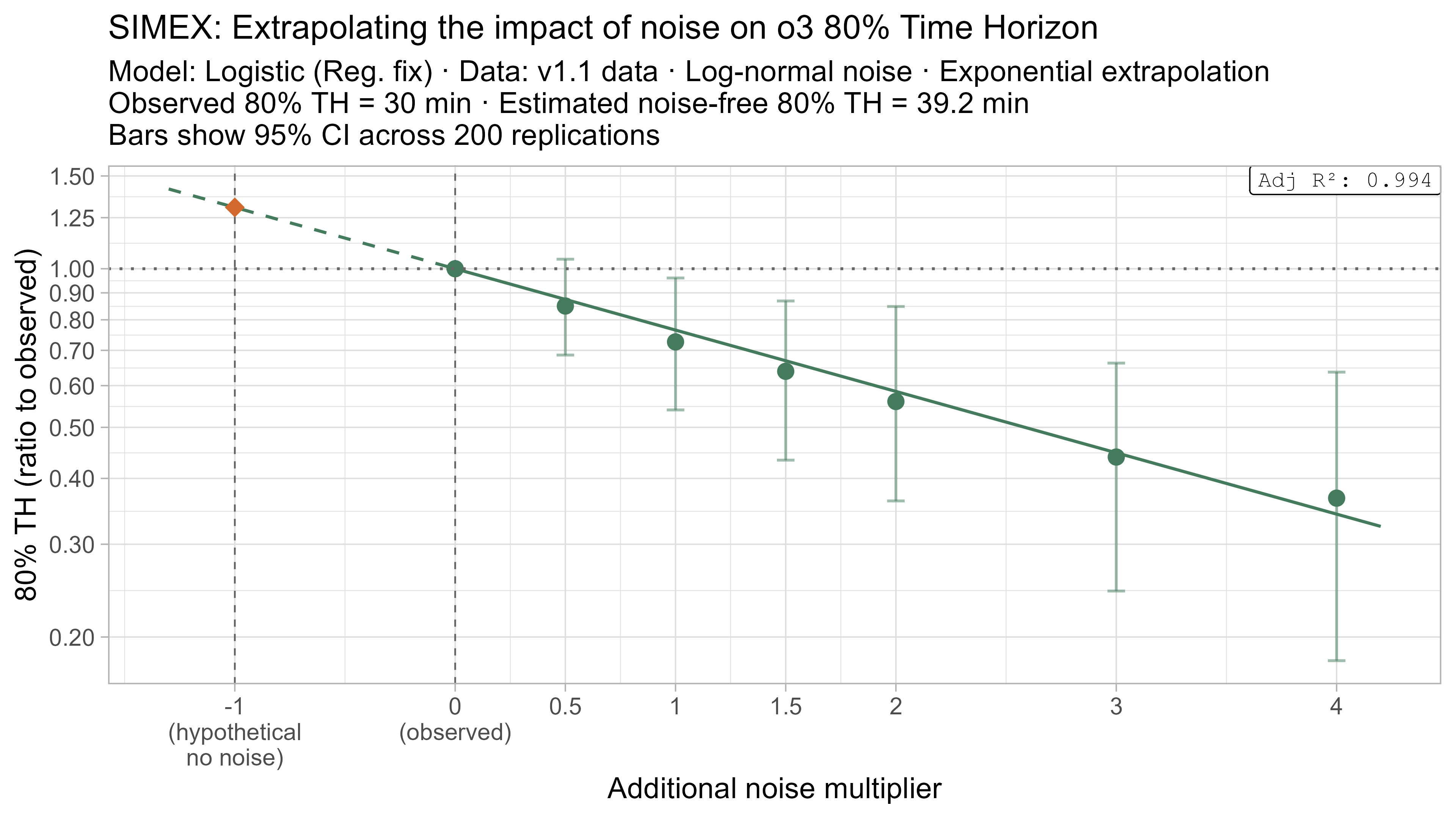
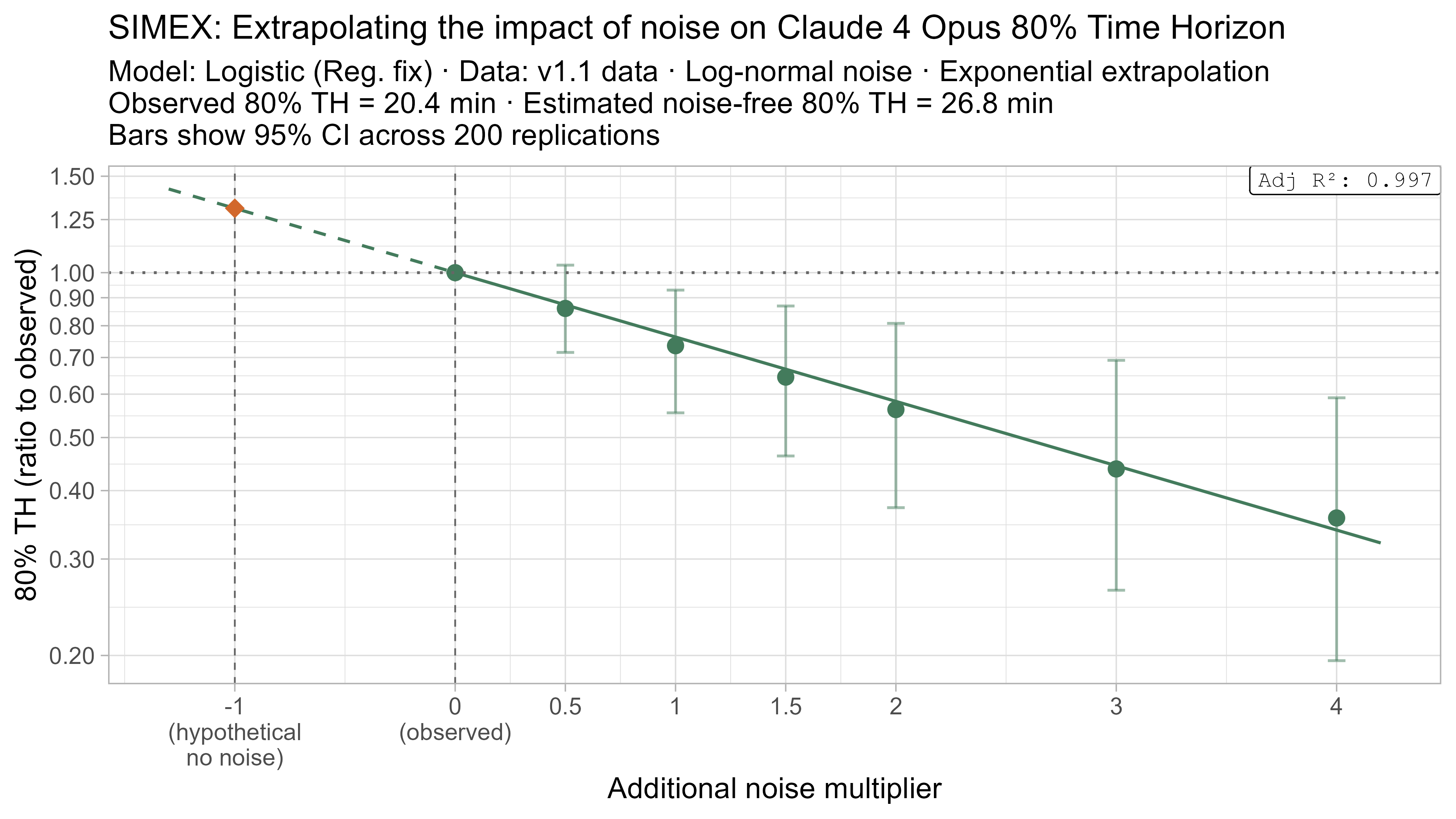
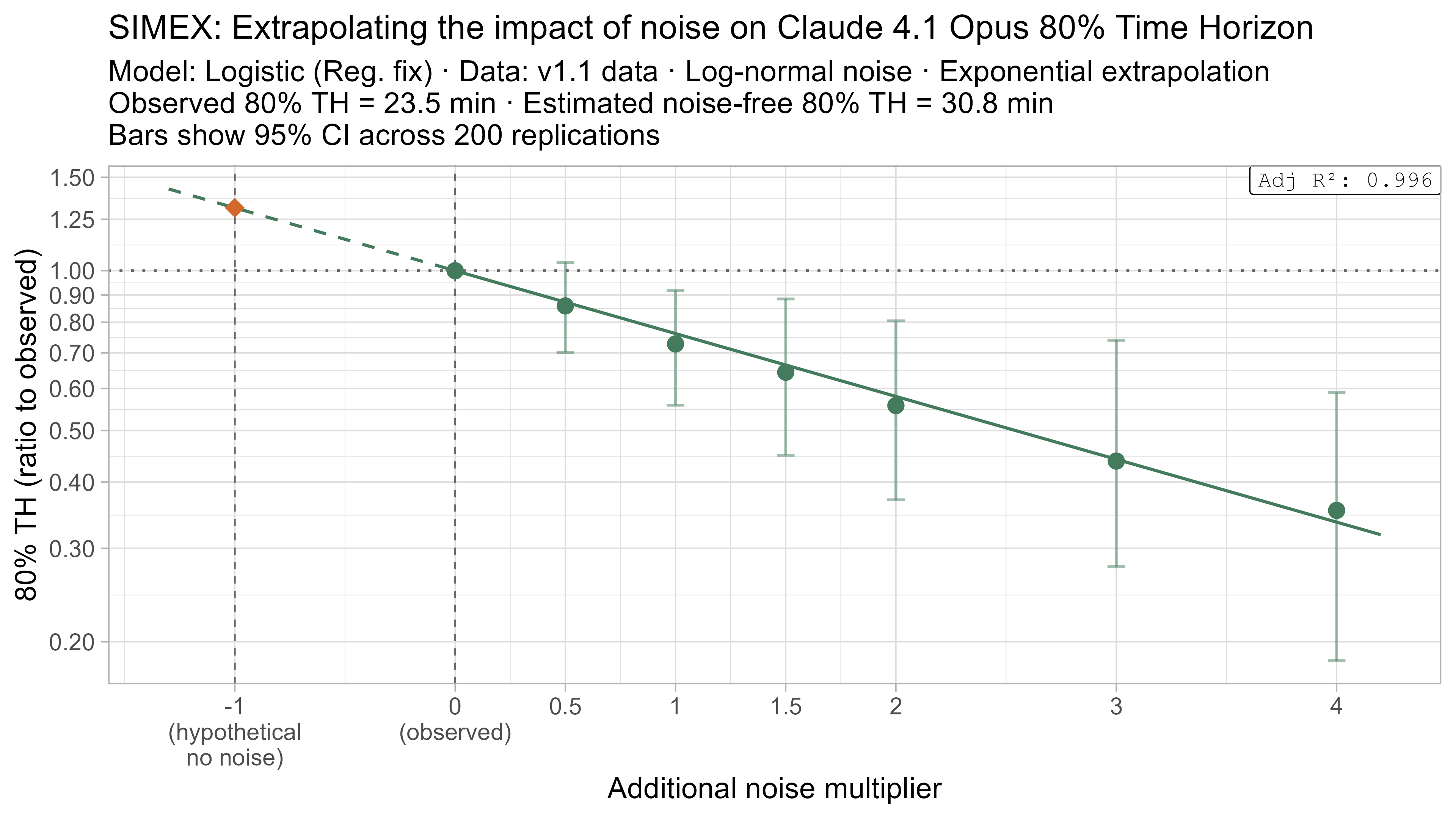
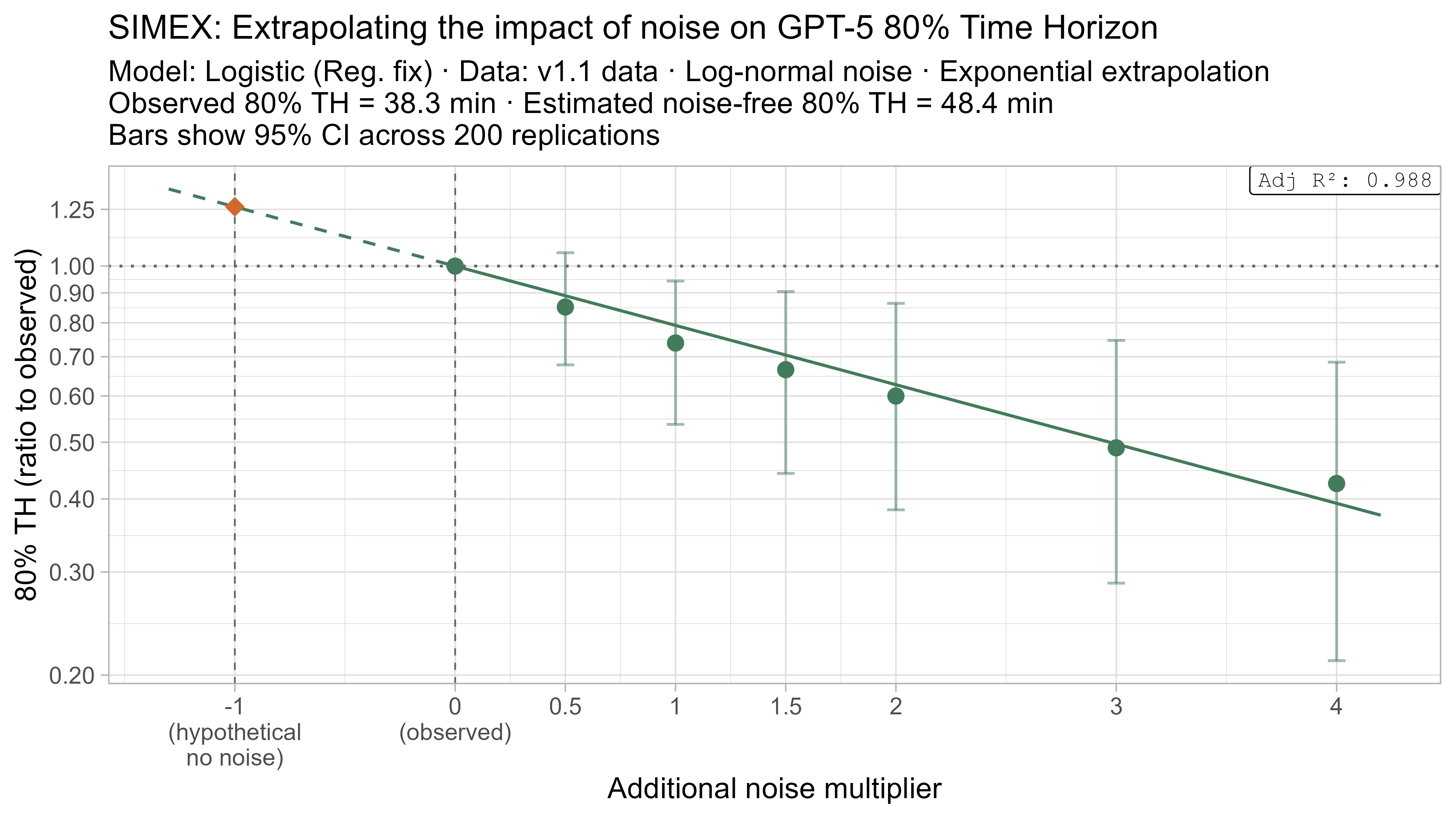
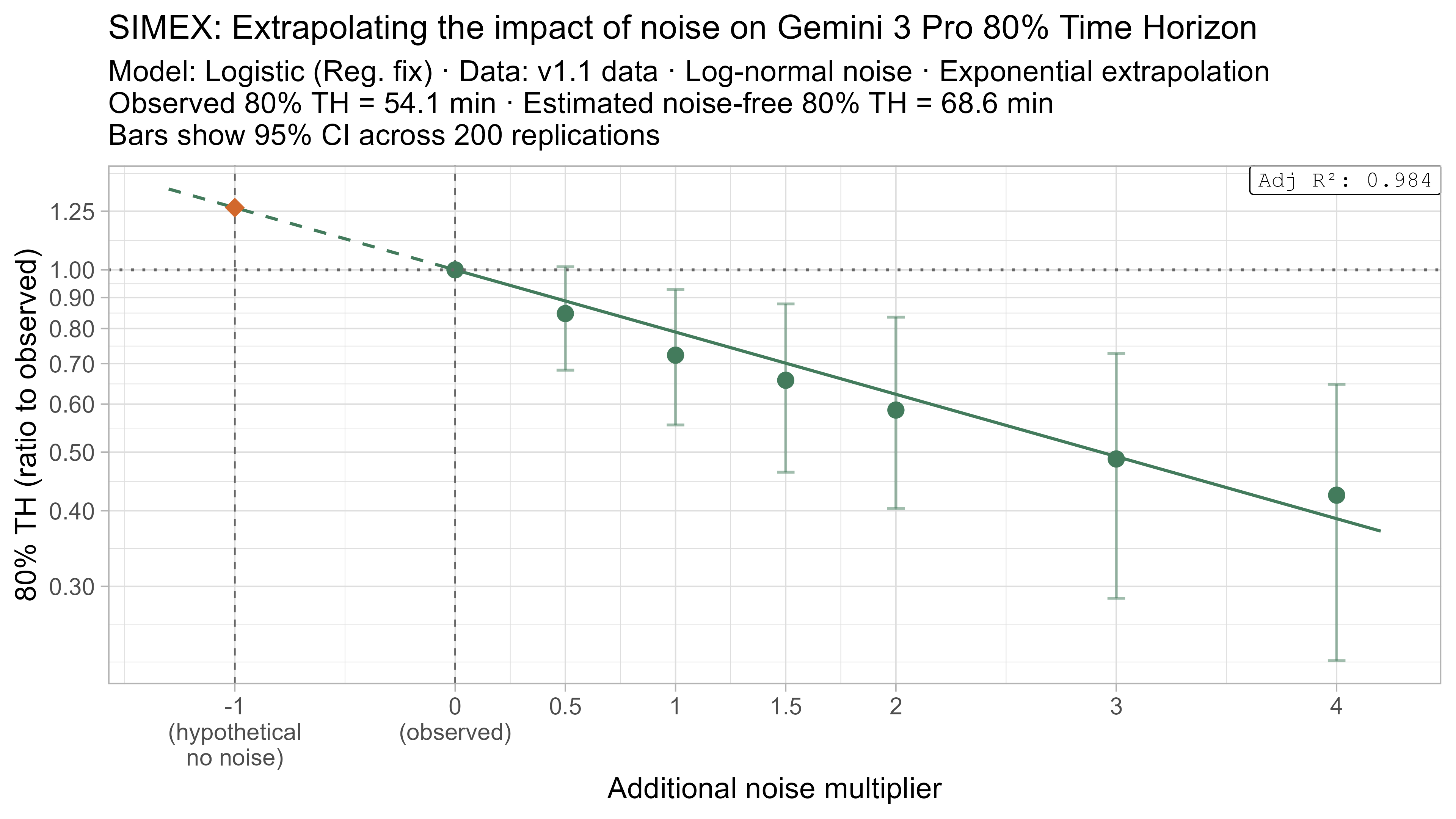
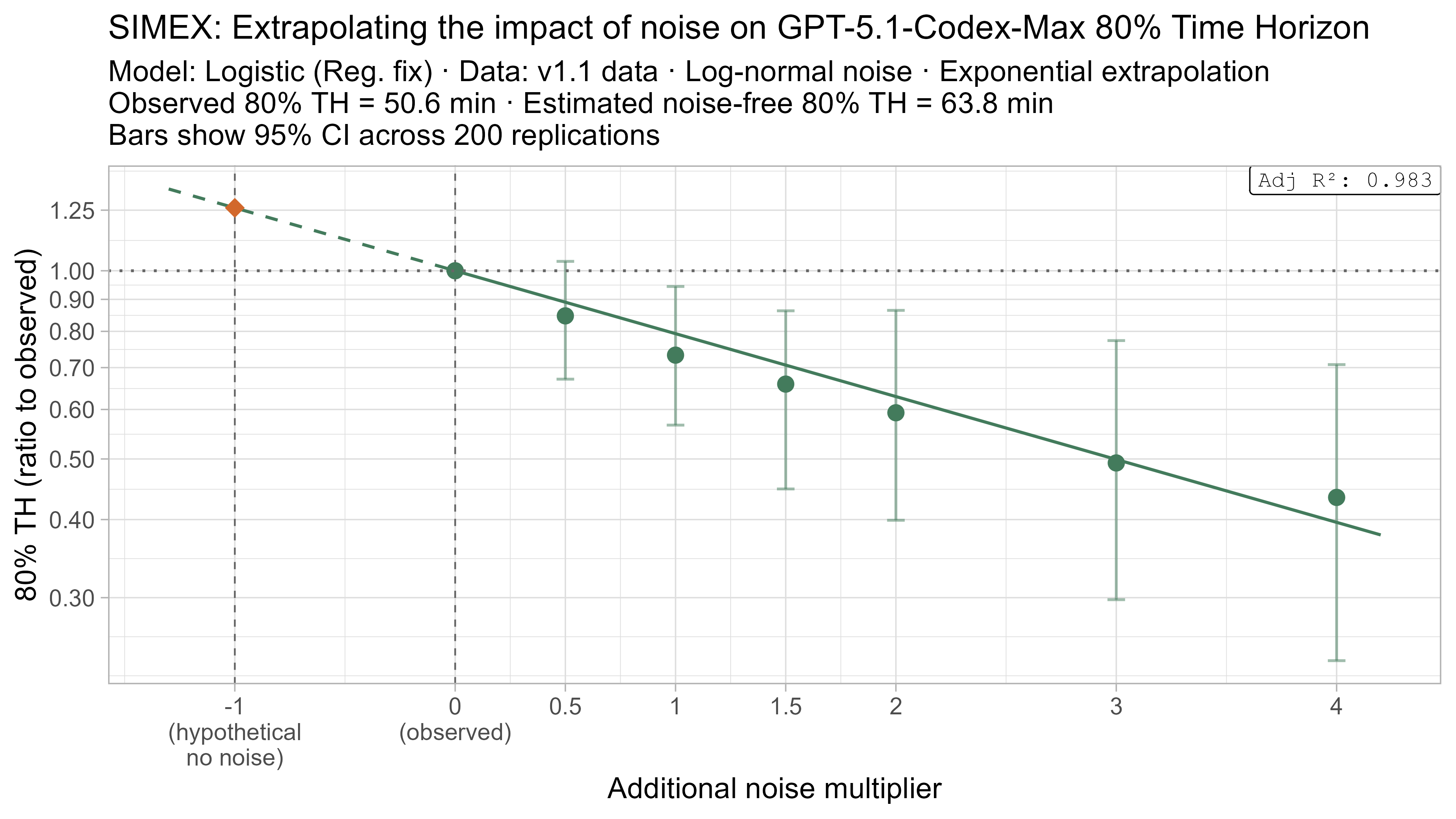
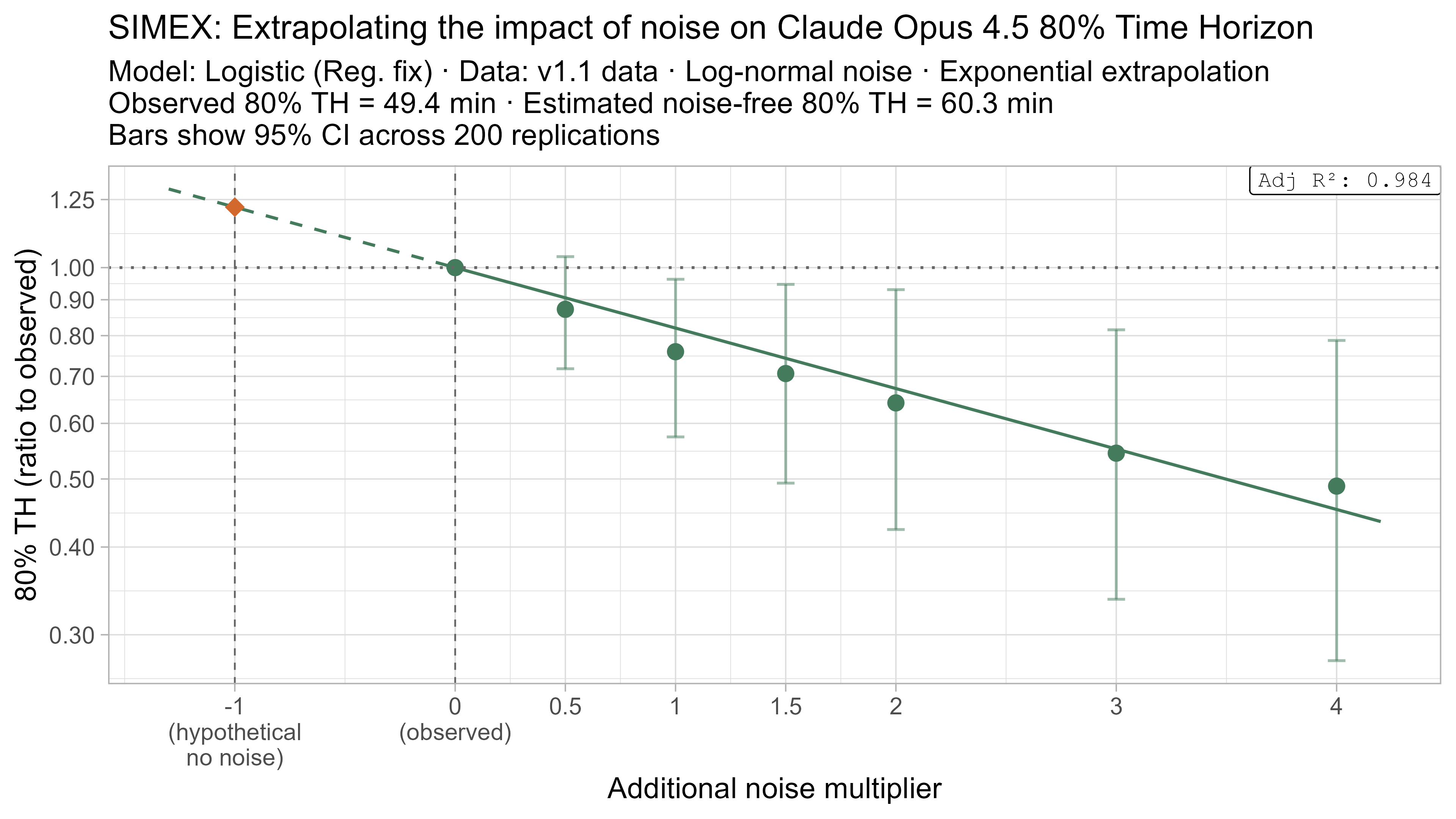
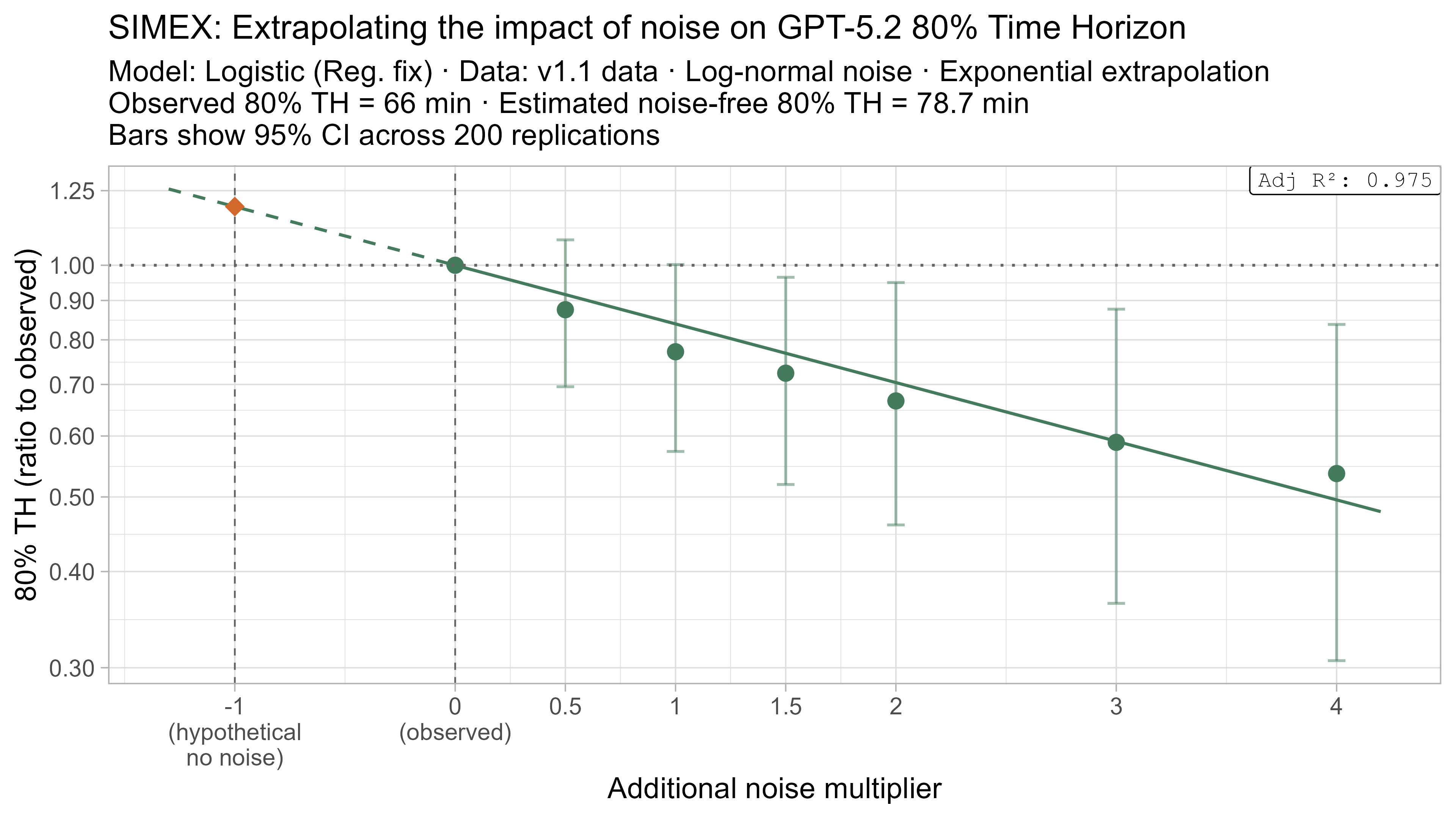
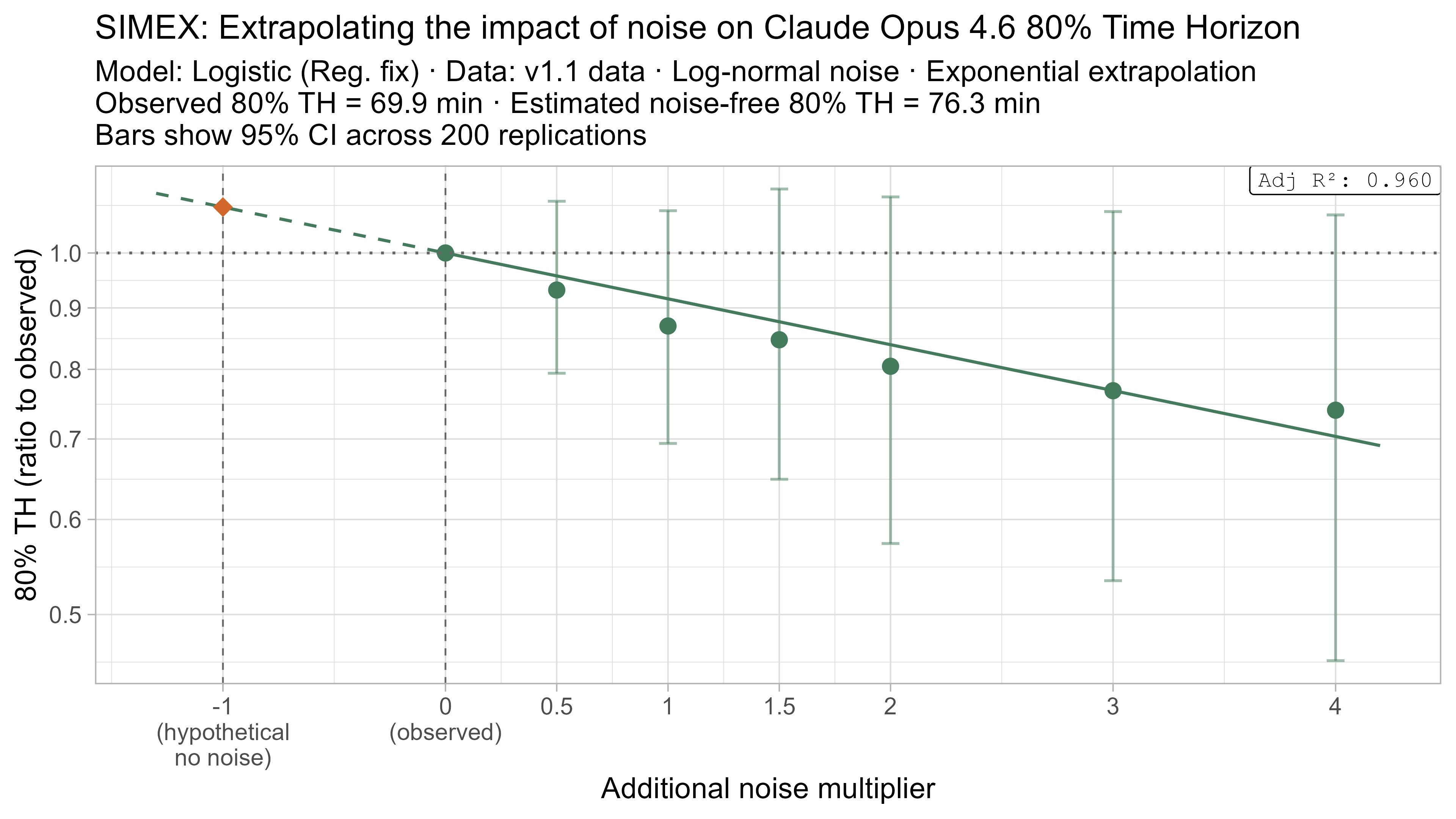
-
Although it had a larger impact on earlier models’ 80% time horizons. ↩
-
The current model actually still includes the regularization term, but with C=100,000, which is so large that the regularization has no practical effect. This was done for simplicity with integrating into the current code. ↩
-
Even achieving only 90% on a set of tasks that was predicted to have a 99.9% success rate can substantially impact the likelihood, and thus the model learns a shallow success rate curve in response. This overly shallow curve then biases 50% TH estimates up and 80% TH estimates down. This is especially pronounced as the TH1.1 task suite does not contain any very long (>30 hour) tasks, and so the right hand tail of the curve is not meaningfully constrained. ↩
-
Changing short tasks in this way only causes a substantial reduction in 50% time horizon for Opus 4.6, likely due to it being closest to the edge of the task suite, as discussed above. ↩
-
And from simple checks 4.6 does not seem to have memorised the RE-Bench task information. ↩


