
In this post, I describe a simple model for forecasting when AI will automate AI development. It is based on the AI Futures model, but more understandable and robust, and has deliberately conservative assumptions.
At current rates of compute growth and algorithmic progress, this model’s median prediction is >99% automation of AI R&D in late 2032. Most simulations result in a 1000x to 10,000,000x increase in AI efficiency and 300x-3000x research output by 2035. I therefore suspect that existing trends in compute growth and automation will still produce extremely powerful AI on “medium” timelines, even if the full coding automation and superhuman research taste that drive the AIFM’s “fast” timelines (superintelligence by ~mid-2031) don’t happen.
Why make this?
- The AI Futures Model (AIFM) has 33 parameters; this has 8.
- I previously summarized the AIFM on LessWrong and found it to be very complex. Its philosophy is to model AI takeoff in great detail, which I find admirable and somewhat necessary given the inherent complexity in the world. More complex models can be more accurate, but they can also be more sensitive to modeling assumptions, prone to overfitting, and harder to understand.
- AIFM is extremely sensitive to time horizon in a way I wouldn’t endorse.
- In particular, the “doubling difficulty growth factor”, which measures whether time horizon increases superexponentially, could change the date of automated coder from 2028 to 2049! I suspect that time horizon is too poorly defined to nail down this parameter, and rough estimates of more direct AI capability metrics like uplift can give much tighter confidence intervals.
Scope and limitations
First, this model doesn’t treat research taste and software engineering as separate skills/tasks. As such, I see it as making predictions about timelines (time to Automated Coder or Superhuman AI Researcher), not takeoff (the subsequent time from SAR to ASI and beyond). The AIFM can model takeoff because it has a second phase where the SAR’s superhuman research taste causes further AI R&D acceleration on top of coding automation. If superhuman research taste makes AI development orders of magnitude more efficient, takeoff could be faster than this model predicts.
Second, this model, like AIFM, doesn’t track effects on the broader economy that feed back into AI progress the way Epoch’s GATE model does.
Third, we deliberately make two conservative assumptions:
- No full automation: as AIs get more capable, they never automate 100% of AI R&D work, just approach it. In the AIFM, automation of coding follows a logistic curve that saturates above 100% (by default 105%), meaning that there is a capability level where they automate all coding.
- No substitutability: Automation follows Amdahl’s law (speedup = $1/(1-f)$ when automated tasks are much faster than manual tasks)
This was constructed and written up fairly quickly (about 15 hours of work), so my opinions on parameters and some of the modeling assumptions could change in the future.
The model
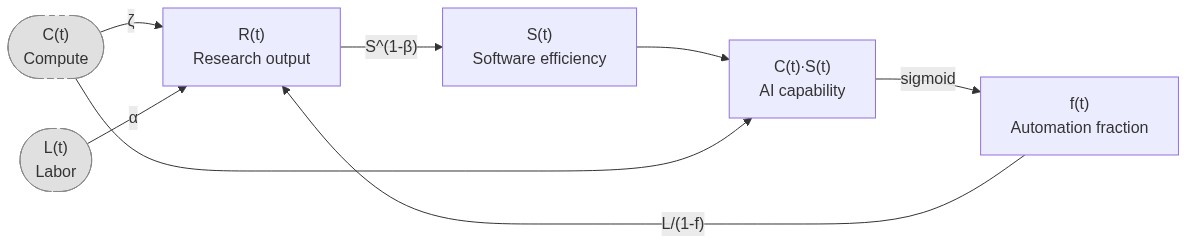
We assume that AI development has the following dynamics:
- Research progress is Cobb-Douglas between labor and compute
- Software efficiency S follows a Jones model
- The key metric we want to predict, fraction of automatable tasks $f$, increases as a sigmoid in log(effective compute)
- Zero substitution between tasks
- Labor
- Humans work on ONLY non-automated tasks
- Human labor on each task is $L/(1-f)$
- AI labor on each task is $CS/f$, but this doesn’t matter because we assume human labor is the bottleneck (since humans work slower than AIs)
This implies the following model:
\[S'(t) = R(t) S^{1 - \beta} = \left(\frac L {1-f}\right)^\alpha C^\zeta S^{1 - \beta}\] \[f(t) = \sigma(v(\log (C(t)S(t)) - \log E_{hac}))\]where
- $S(t)$ is the algorithmic efficiency multiplier (I assume that training and inference efficiency improve at the same rate)
- so $C(t)S(t)$ is the effective compute of the best AI
- $f(t)$ is the fraction of automated tasks at time $t$
- $R(t)$ is research production at time $t$
- $L(t)$ is human labor, specified as an input time series
- $C(t)$ is compute, also an input time series
- $\alpha, \beta, \zeta$ are constant
- $\alpha$ is diminishing returns to more labor.
- $\beta$ is the difficulty exponent for software improvement
- $\zeta$ is direct returns to compute. This is not relevant for a software intelligence explosion, but it’s highly relevant when looking at how much capabilities will improve given future compute investment.
- $E_{hac}$ is the effective compute level of an AI that can automate half of AI R&D tasks.
- $v$ is the automation velocity: S must increase by factor of $e^{1/v}$ to get from 50% to 73% automation. This is essentially how easy it is to translate capability gains into more automation.
None of the components of this model are novel to the AI forecasting literature, but I haven’t seen them written up in this form.
Parameter values
The parameters are derived from these assumptions, which are basically educated guesses from other AI timelines models and asking around:
- The rate of change of S in Jan 2026 is 5x/year
- 1/v is between 1.5 and 4.2
- NB David Rein thinks 2.1 to 4.2
- f was between 0.25-0.5 in Jan 2026, implying between 1.33x and 2x uplift. This informs the value of $E_{hac}$.
- $\alpha/(\alpha + \zeta)$ is between 0.12 and 0.35
- $\alpha + \zeta$ is between 0.8 and 1
- $\beta$ is 0.3 to 1
- L doubles every year until 2029, after which it increases 10%/year
- C grows 2.6x every year until 2029, after which the growth rate linearly decreases from 2x to 1.25x/year between 2030 and 2058. (This is consistent with Epoch estimates in the near term, and approximates the AIFM’s time series after 2030)
All parameters are independently distributed according to a triangular distribution. Due to the transforms performed to get alpha, zeta, and v, v will not be triangular and alpha and zeta will not be triangular or independent.
For more information see the notebook: takeoff_simulation.ipynb
Graphs
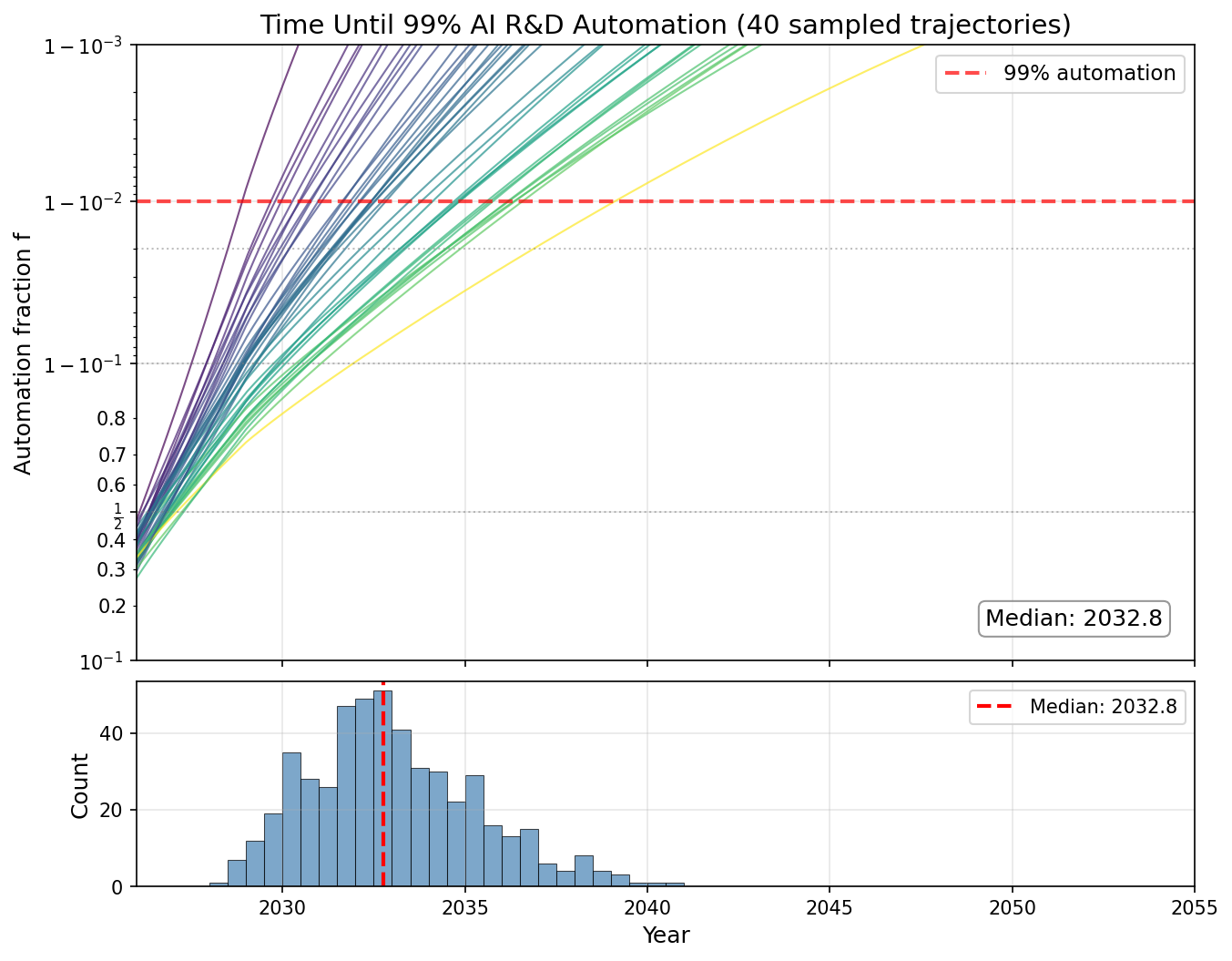
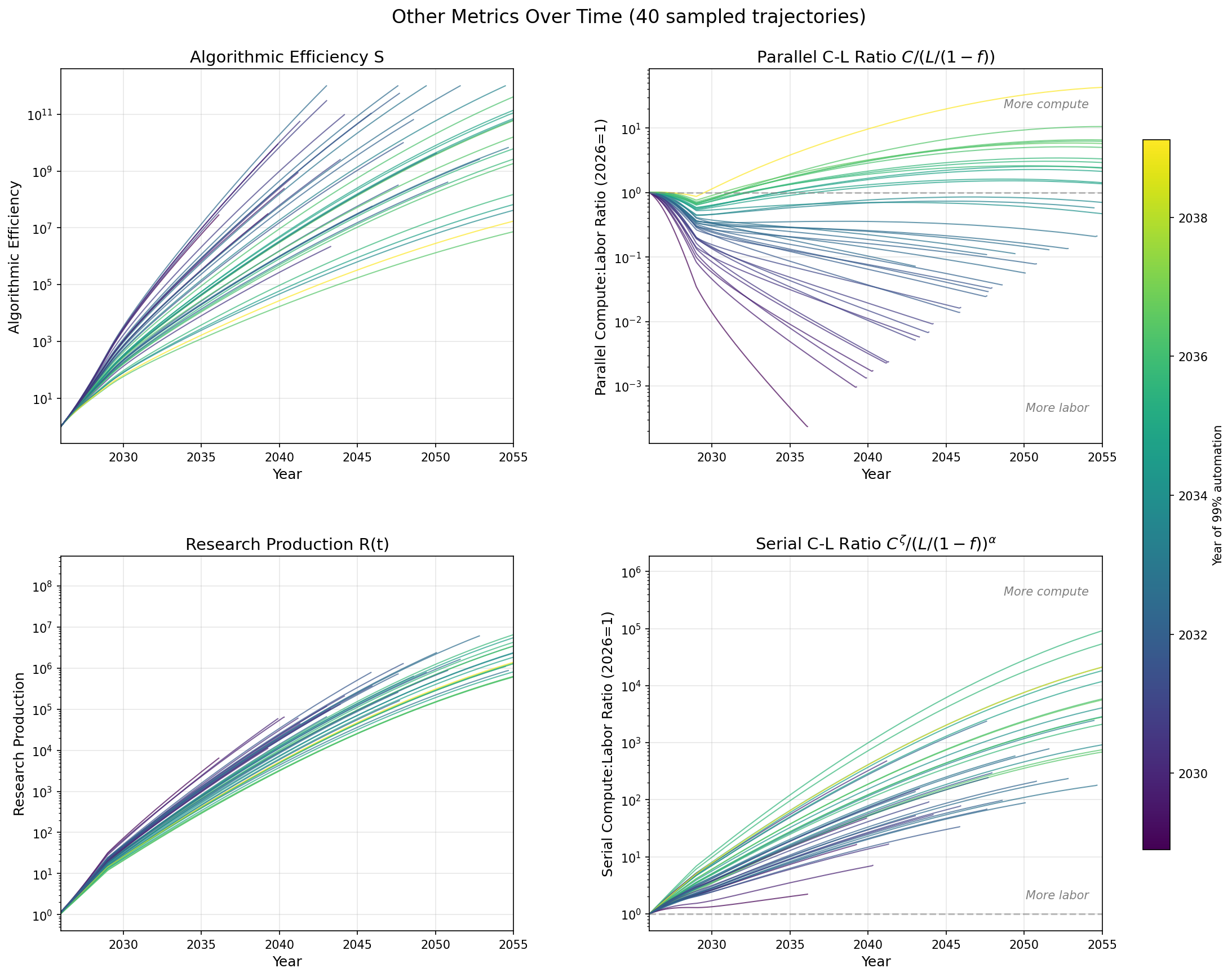
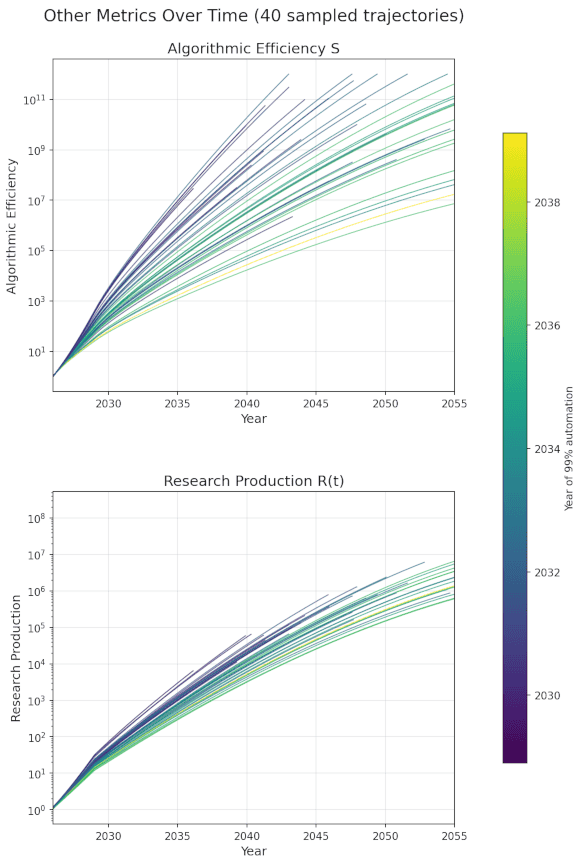
All graphs display 40 trajectories with parameters sampled according to the section Parameter Values.

Observations
- The AI Futures model is complex, but its conclusions are fairly robust to simplifications.
- The two key uncertainties behind timelines are
- how to measure algorithmic progress (our estimates are still highly uncertain)
- how effective compute relates to % automation of real tasks
- At current rates of compute growth and algorithmic progress, there will be >99% automation of AI R&D, 1e3 to 1e8 software efficiency gain, and 300x-3000x research output by 2035, even without full automation or automated research taste. This is clearly transformative AI
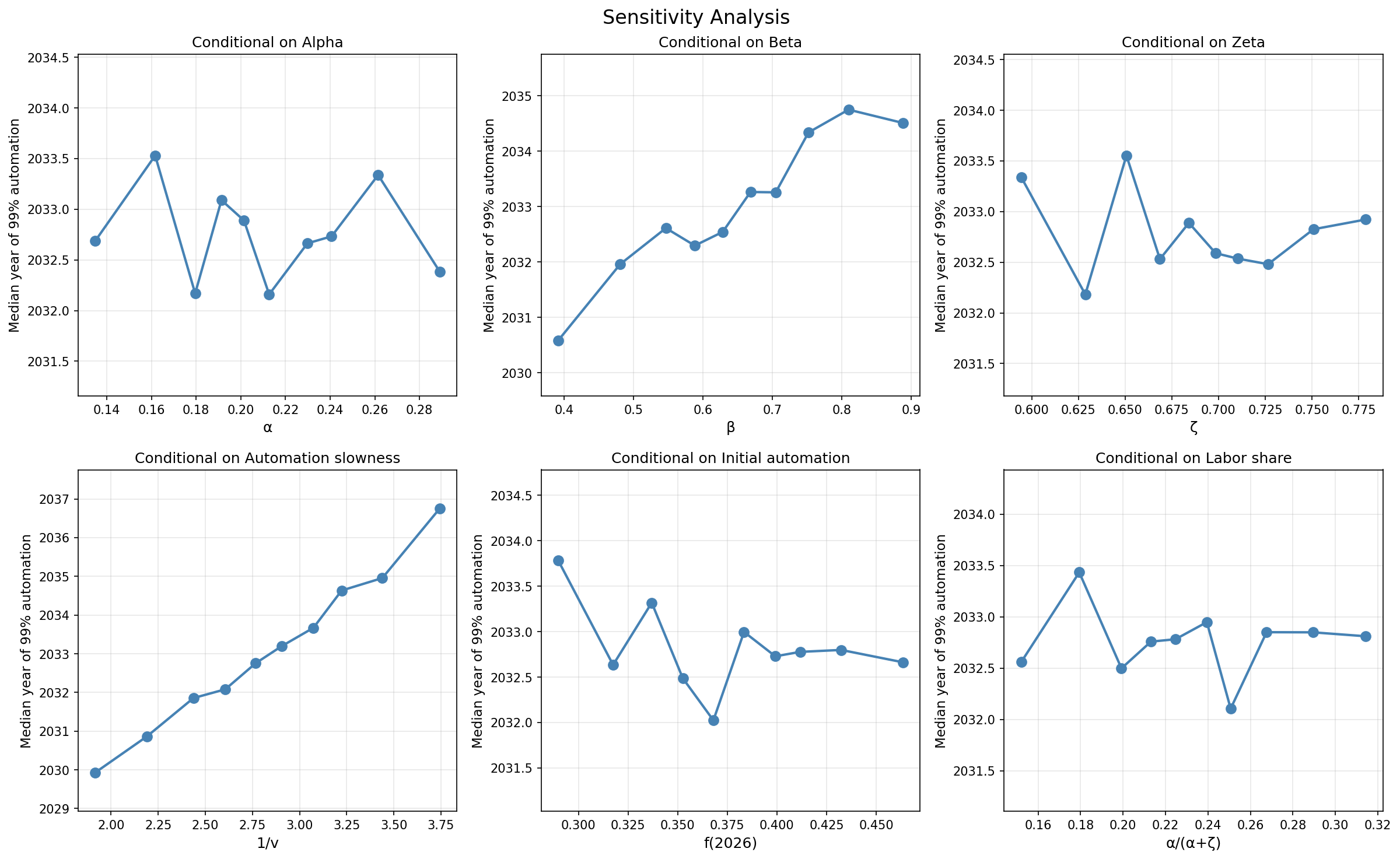
- The median date of 99% automation is mid-2032. However, I don’t put too much weight on the exact predicted timelines because I haven’t thought much about the exact parameter values.
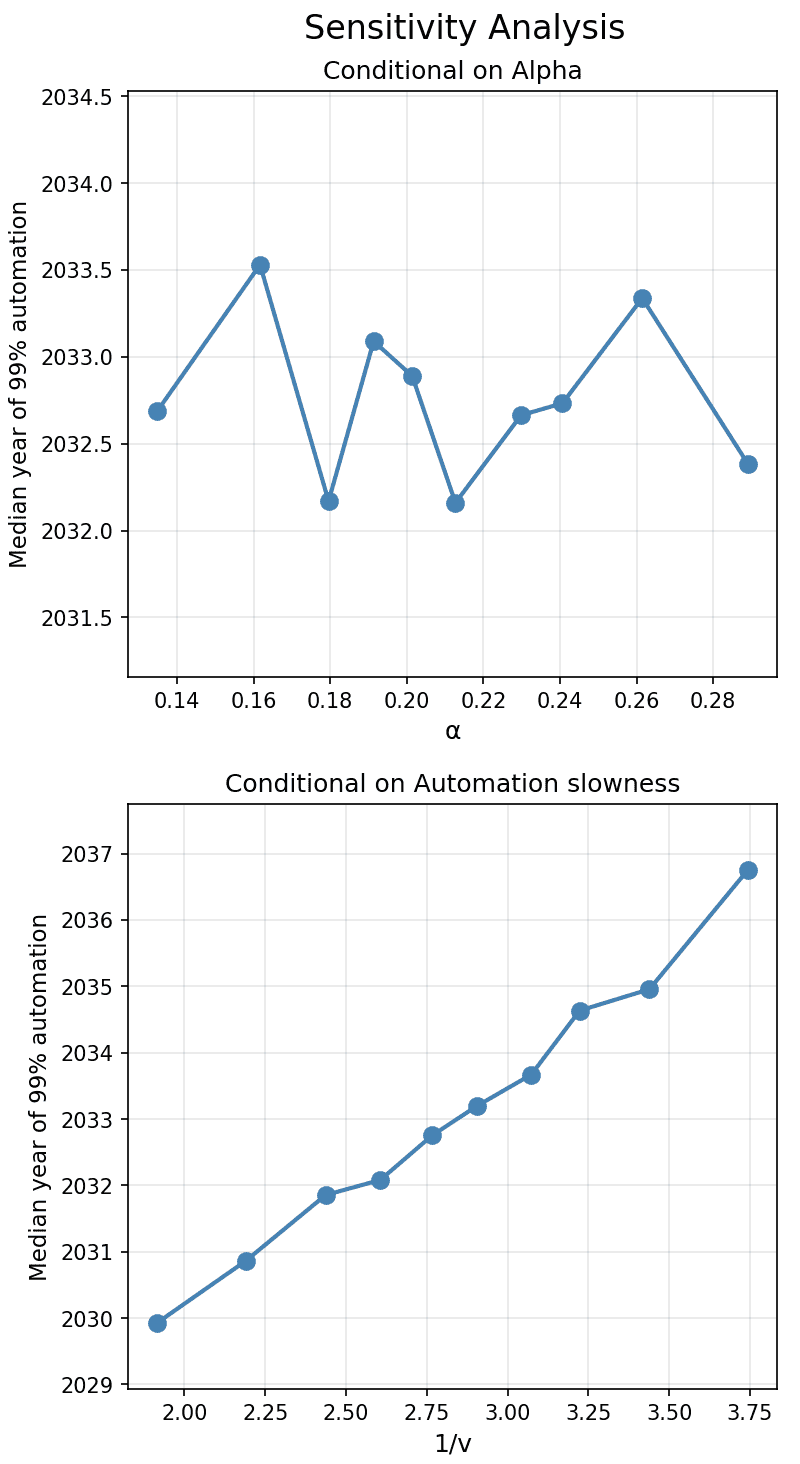
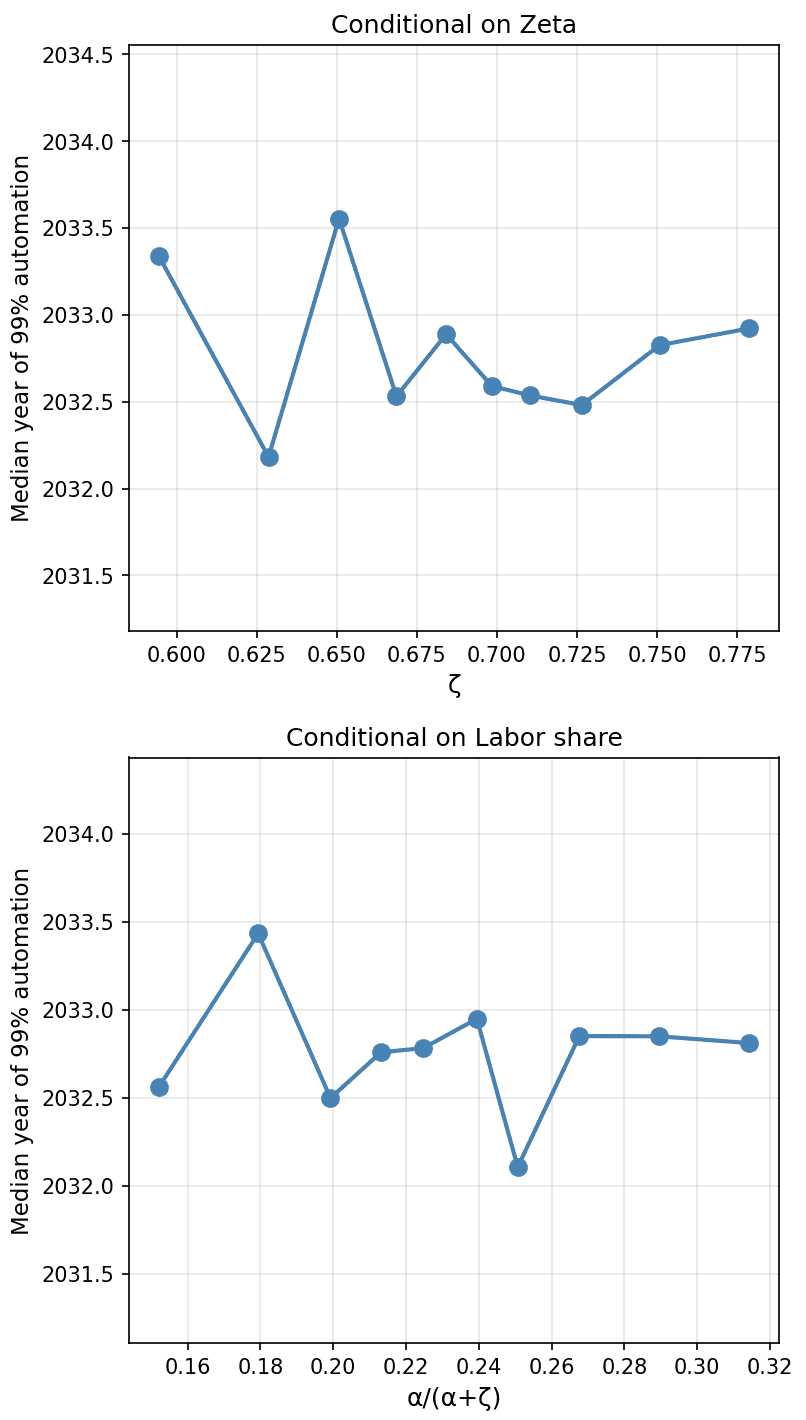
- A basic sensitivity analysis shows that higher beta (diminishing returns) and lower v (automation velocity) make 99% automation happen later, and the other parameters don’t affect things much.
- One might expect the “labor share” $\alpha / (\alpha + \zeta)$ to have a large effect on timelines. The reason it doesn’t affect timelines much is that both labor (through automation) and compute (through exogenous compute growth) are scaling quickly and contribute to AI progress.
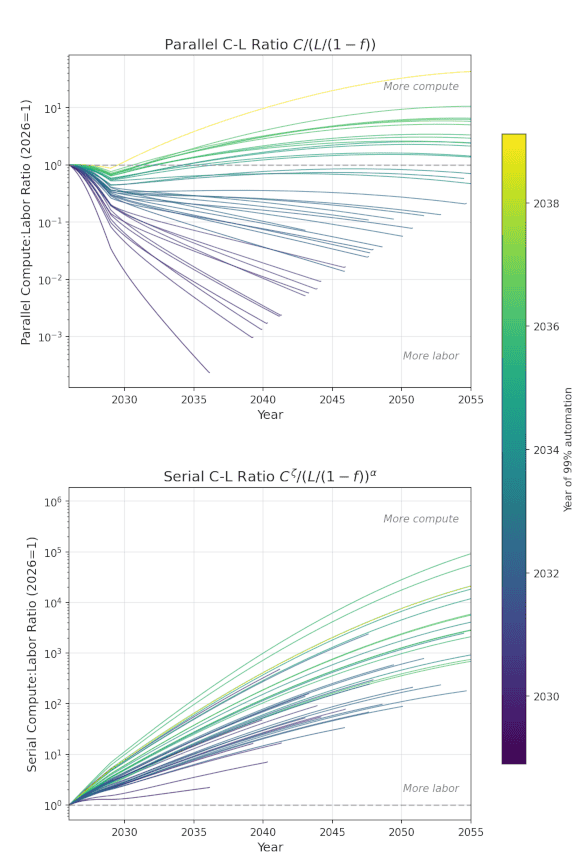
- The parallel compute:labor ratio, measuring the amount of compute per AI or human coder, decreases in the average trajectory and is ~flat in long-timelines trajectories. So in 2030 timelines, the pool of human and AI coders has much less compute than today, while in 2035 timelines, they have about the same amount.
- The serial compute:labor ratio goes UP, meaning that compute growth has a larger impact on research output than labor growth. This is because compute is increasing so fast and the parallel labor added by automation doesn’t effectively translate into serial labor.
Discussion
From playing around with this and other variations to the AI Futures model I think any reasonable timelines model will predict superhuman AI researchers before 2036 unless AI progress hits a wall or is deliberately slowed.
- By progress hitting a wall, I mean something like compute and human labor growth slowing down in ~2030, no architectural breakthroughs, and AI labs not finding anything new to usefully spend resources on to improve performance. We have scaled pretraining, RLHF, RL for agency, and inference, and even one or two more dimensions could keep progress going.
- In the sensitivity analysis, automation slowness doesn’t push timelines into 2036 unless it’s greater than 3.6 (37x efficiency gain required to increase automation from 50% to 73%). As for diminishing returns (beta), we get 2034 timelines even if you assume it’s 0.9. So we would need both high automation slowness and high beta to get timelines after 2036.
In addition to refining the parameter values with empirical data, I would ideally want to backtest this model on data before 2026. However, a backtest is likely not feasible because automation was minimal before 2025, and automation of AI R&D is the main effect being modeled here.
More on modeling choices
List of differences from the AIFM
It may be useful to cross-reference this with my AIFM summary
- No substitutability: Automation follows Amdahl’s law (speedup = $1/(1-f)$ when automated tasks are much faster than manual tasks). AIFM assumes a small degree of substitutability ($\rho_c = -2$).
- Automated tasks don’t bottleneck: Once a task can be automated, we assume it’s much faster than humans and is never the bottleneck– either because AIs will run much faster than humans in series or somewhat faster in parallel. AIFM assumes automated tasks initially run somewhat faster than human coding and speed up over time.
- No full automation: as AIs get more capable, they never automate 100% of AI R&D work, just approach it. In the AIFM, automation of coding follows a logistic that saturates above 100% (by default 105%, a number which seems somewhat arbitrary), meaning that there is a capability level where they automate all coding.
- Labor and compute are Cobb-Douglas. Unlike other differences, this one pushes in the direction of shorter timelines. In the AIFM, they are CES and slight complements, so that infinite labor doesn’t produce infinite progress. See below for more thoughts.
- No use of time horizon: Software efficiency is a direct input to our model rather than being estimated using time horizon. We model automation fraction as strictly logistic in log effective compute, related via rough uplift estimates that we hope to refine in the future. See “Why make this” for why. AIFM estimates the required effective compute for an Automated Coder using a time horizon threshold.
- No research taste: We don’t model research taste separately; I think of early research taste as continuous with the planning involved in coding, and ignore late research taste. Given the lack of research taste model and certain parameter choices, capability growth happens to be subexponential (so I don’t attempt to model whether there will be a taste-only singularity). AIFM has a rich model of research taste that needs another 6 or so parameters and informs the second phase of takeoff, from Automated Coder to ASI and then to the ultimate physical limits of intelligence.
How could we better estimate the parameters?
We can get $f(2026)$ [uplift fraction in 2026] from
- transcripts of realistic coding agent usage + success judge + difficulty judge calibrated on tasks of known lengths
- uplift RCTs
- asking lab employees about their current uplift (since parallel uplift and 1/(1-f) are equivalent in the simple model)
v [velocity of automation as capabilities improve] can be obtained by
- guessing the distribution of tasks, using time horizon, maybe using a correction factor for real vs benchmark time horizon
- multiple uplift studies over time
- comparing older models to newer ones, or having older models try things people use newer models for
- listing how many things get automated each year
Why is automation logistic?
- A logistic is the simplest choice for anything that maps the reals to (0, 1).
- Intuitively, when AIs are already automating >50% of human research, each unit of capabilities progress will allow automating a constant fraction of remaining labor. The logistic has an exponential tail, which matches this intuition.
Why are labor and compute Cobb-Douglas?
In the AIFM, the median estimate for substitutability between labor and compute is -0.15, and the plausible range includes zero (which would be Cobb-Douglas). I asked Eli why they didn’t just say it was Cobb-Douglas, and he said something like Cobb-Douglas giving infinite progress if one of labor/compute goes to infinity while the other remains constant, which is implausible. I have two responses to this:
- It doesn’t seem so implausible to me– for infinite compute, it would take days to weeks to get to ASI given infinite compute, meaning a 100x-1000x speedup, but once there, infinite compute might allow developers to develop algorithms in months that would take humans billions of years with current compute levels. As for infinite labor, a literally infinite pool of labor could just do training runs by manual calculation and write down the optimal AI weights without using any experiment compute.
- Effective labor/compute ratio only changes by 10-100x during the period in question, so it doesn’t affect results much anyway. The fastest trajectories are most affected by compute:labor ratio, but for trajectories that get to 99% automation around 2034, the ratio stays around 1:1.
Why is there no substitutability between tasks?
The AIFM’s median was something like $\rho = -2.0$, meaning very weak substitution effects. To be conservative, I assumed no substitution effect.
(edit 2/11: revised some language on comparison to the AIFM)


