We’re releasing a new version of our time horizon estimates (TH1.1), using more tasks and a new eval infrastructure.
Our estimates of time horizons for many models have been updated. The new estimates generally fall within our existing confidence intervals, though the trend in time horizon growth looks a little different, discussed below. We expect to make more changes to our evaluation protocols so that we can capture the continued rapid growth in capabilities.
Early in 2025 we published our time-horizon methodology for measuring the autonomous capabilities of AI models.
We found a steady exponential increase in models’ human-equivalent “time horizon.” Over the course of 2025 we applied this methodology to newer models and measured a rate of increase consistent with historical trends.
We are rolling out two significant changes to our time-horizon evaluation setup:
-
Improvements to our task suite. We increased our suite from 170 to 228 tasks. We added 73 tasks (all are from HCAST, described in Rein (2025)), removed 15 tasks, and updated 53 tasks (27 tasks had an updated definition, 13 tasks had an updated human time estimate, and 13 had both). We increased the number of long tasks (estimated to take humans 8 or more hours) from 14 to 31. The additions represent HCAST tasks that were not included in the original time horizon paper, but subsequently passed our quality check processes. The modifications and removals generally represent cases where a task description was confusing, or easy to reward-hack, or the scoring function had errors.
-
A move of our evaluation infrastructure from Vivaria to Inspect. We developed Vivaria in-house in 2023. Inspect is a widely-adopted open-source framework for AI evaluations developed by the UK AI Security Institute.
The estimated time horizon for each model has changed somewhat.
We have re-estimated the effective time horizons for 14 models, using performance on our new TH1.1 task suite and evaluation infrastructure. The new estimates generally lie within the confidence intervals from the TH1 time horizons.
We re-estimated horizons for only 14 of 33 models which had TH1 estimates. The smaller set of models in TH1.1 is for a variety of reasons, including (i) the model no longer being publicly available, (ii) the model requiring significant changes to the tool-calling scaffold (e.g. for GPT-2, GPT-3, and GPT-3.5), or (iii) because the model was far from the capability frontier at the time of release, so unlikely to change the estimated trend.
Changes in the estimated time horizons are primarily due to changes to the task suite and random noise during a run. Some of the change is also attributable to the change in evaluation infrastructure, however we document below that this is a relatively small share.
Our new task suite contains more tasks, yielding tighter estimates especially at the upper end.
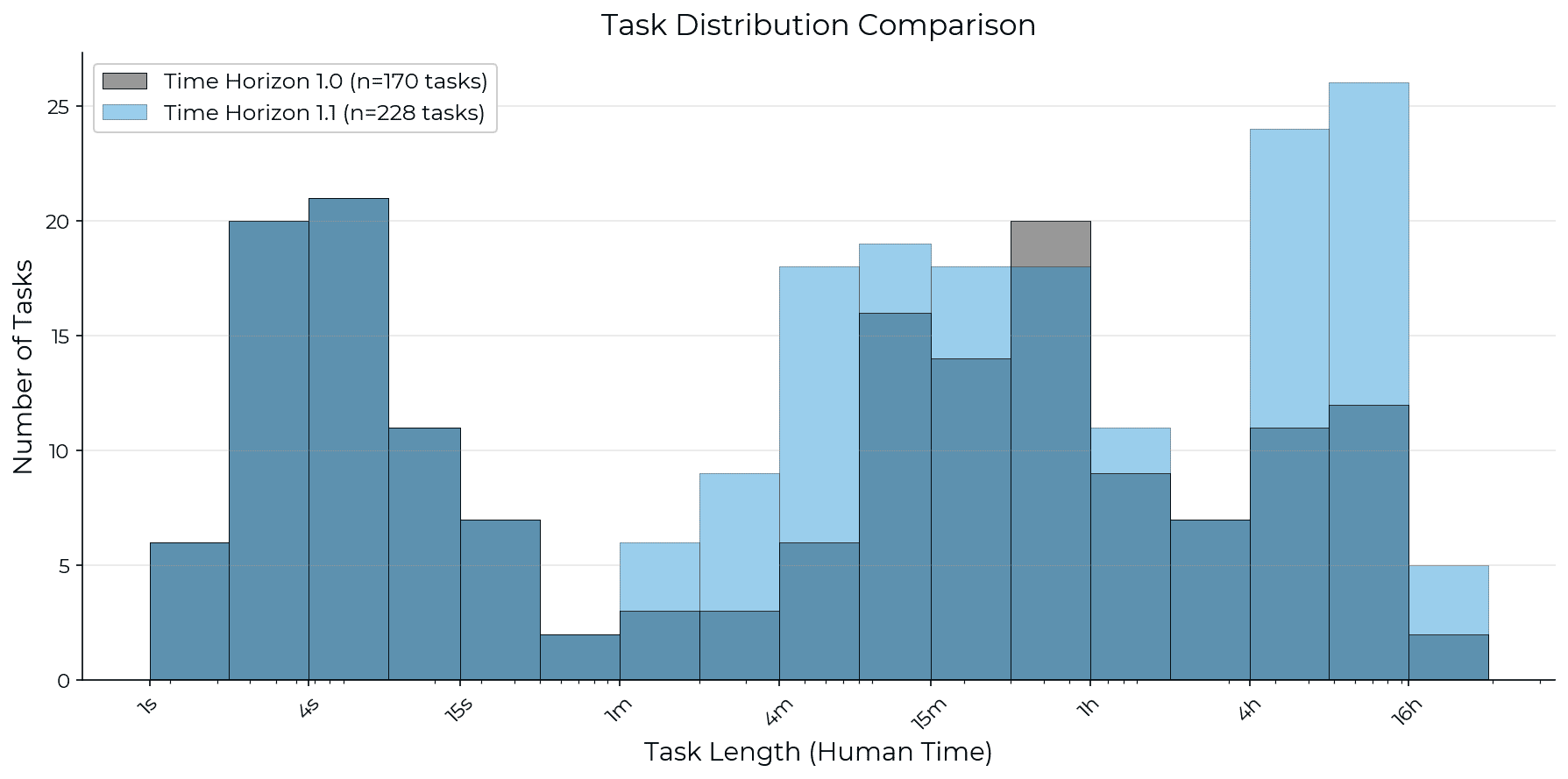
We increased the tasks in our suite by 34% (228/170) and doubled the number of tasks that are 8 hours or longer (31/14). This gives us significantly tighter confidence intervals on the time horizon of more recent models, e.g. the upper bound on Opus 4.5 was 4.4X larger than the point estimate with TH1, but it is now 2.3X larger with TH1.1. These confidence intervals are still very wide, and we are actively working on adding more long tasks to help get tighter estimates and avoid saturation as model capabilities continue to advance.
It is also notable that we measured human baseline times for only 5 of our 31 long (8h+) tasks. The remainder use estimated times.
The trend in time horizon is somewhat sensitive to task composition.
Our original time horizon dataset, released in March 2025, showed a smooth trend with the frontier time-horizon doubling around every 7 months over the period 2019 to 2025.
We cannot directly compare growth-rates between TH1 and TH1.1 over the entire period because we did not re-estimate any of the pre-2023 models with TH1.1. We thus make two comparisons.
First, we compare the TH1 trend to a hybrid trend, where we use TH1 estimates for the earlier models that are missing from TH1.1 (i.e. for GPT-2, GPT-3, GPT-3.5). This hybrid trend shows exactly the same doubling time as the TH1 trend, of 196 days (7 months). The new fit appears slightly less linear, with a slightly lower R^2.
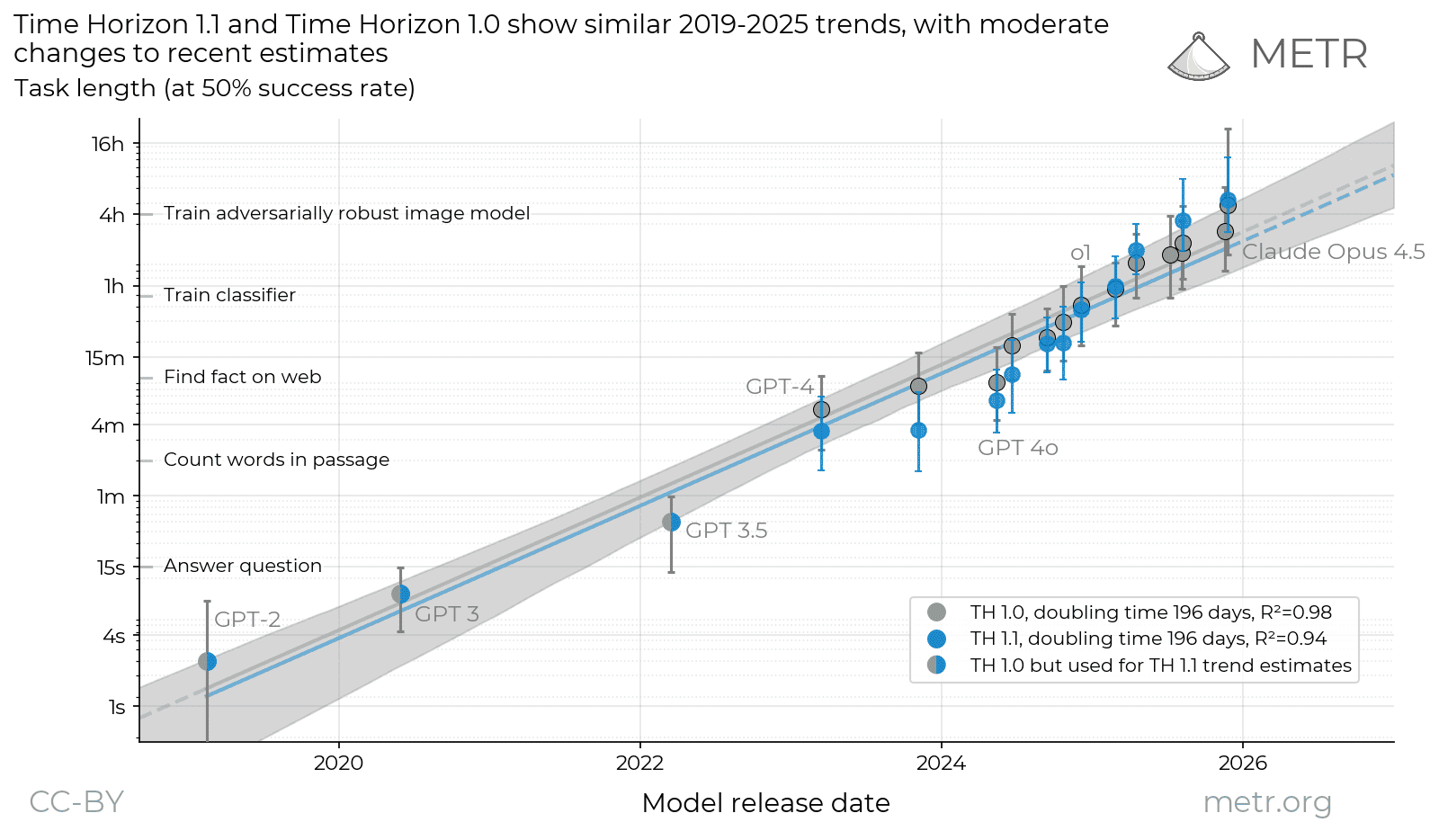
Measurements of the 50%-time-horizon of different models across different task suites and evaluation infrastructures. Grey points represent estimates with our old tasks and evaluation infrastructure (TH1), blue points represent estimates with our new task suite and evaluation infrastructure (TH1.1). The first three points are marked blue/grey to indicate they are TH1 estimates, but used to fit both trend lines.1 The full data can be accessed above the caption at our live dashboard.
Second, we compare the TH1.1 and TH1 trends since 2023, where we have data from both methods. Note that we have estimated fewer models with TH1.1, so the sets of models used to estimate these trends are mostly overlapping but not identical. The post-2023 doubling-time is 131 days under TH1.1, compared to 165 days under TH1, meaning progress is estimated to be 20% more rapid under TH1.1.
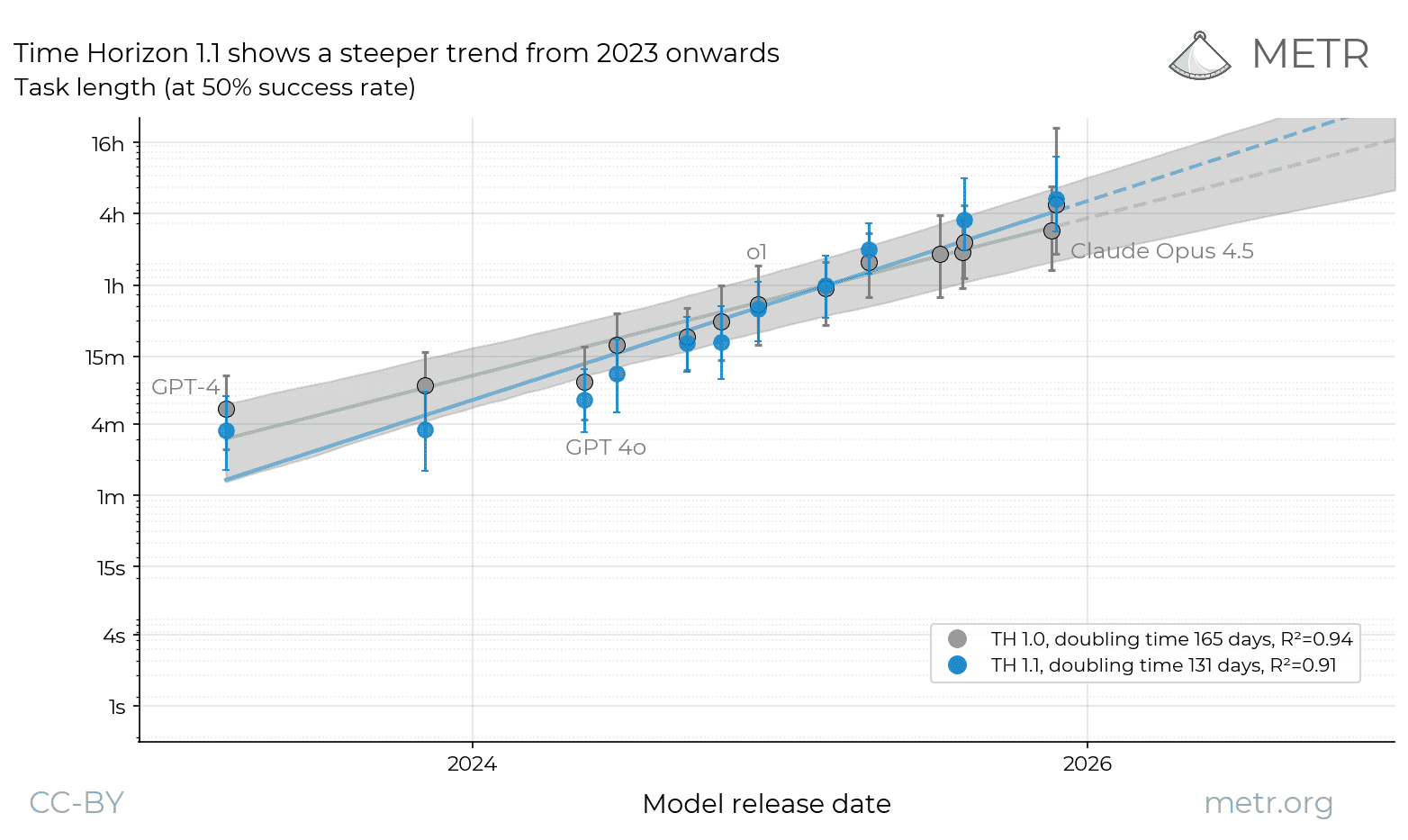
The change in trend is due to our estimates of older models shifting down (different versions of GPT-4 see estimates fall by 35% and 57% respectively), and estimates of recent models shifting up (GPT-5 and Opus 4.5 rise by 55% and 11% respectively). The TH1.1 doubling time is within the confidence intervals for TH1’s doubling time, however those confidence intervals represent the likelihood of getting the same estimate with an entirely new set of tasks, while in fact there is substantial overlap in the tasks contained in TH1.1 and TH1.2 We also report below the doubling time since 2024: this was at 109 days under TH1, and falls to 89 days under TH1.1.
Overall we believe it’s likely the new tasks are drawn from a slightly different distribution of difficulty, as such they reflect a slightly different underlying trend in time horizon. This is a natural consequence of updating our pool of tasks without having a rigid selection criteria. We believe the new task suite to be overall an improvement, and so worth this slight change in the quantity being estimated.
The process of updating our task suite has highlighted the importance of defining the distribution of tasks which we wish to measure performance over. We previously have described principles used in selecting tasks for measuring time horizon in a variety of places. Our time horizon paper (Kwa et al.) described the suite as “datasets designed to capture skills required for research or software engineering, and included RE-Bench, a subset of HCAST, and a new set of short tasks (SWAA). We also described principles for task selection in our task bounty desiderata, and in our cross-domain time-horizon blog post.
We are working on raising the ceiling of our capabilities measurements.
As discussed above, even our Time Horizon 1.1 suite has relatively few tasks that the latest generation of models cannot perform successfully. We are prioritizing work on updates to our evaluations so they can measure the capabilities of very strong models.
Appendices
Data
We have updated our public repo with data on both TH1 and TH1.1, see eval-analysis-public.
Comparison of Old and New Estimates
| TH1.0 | TH1.1 | |
|---|---|---|
| P50 doubling time | 195.8 days [162, 223] | 196.5 days3 |
| P50 doubling time, >=2023 | 165.3 days [129, 211] | 130.8 days [107, 161] |
| P50 doubling time, >=2024 | 108.9 days | 88.6 days |
| Tasks | 170 | 228 |
| Tasks 8h+ | 14 | 31 |
| Tasks 8h+, human baselined | 6 | 5 |
| Tasks, new | 73 | |
| Tasks, removed | 15 | |
| Models | 33 | 14 |
| SoTA Models | 17 | 11 |
Changes to Model Horizon Estimates
| TH1 | TH1.1 | Change | |
|---|---|---|---|
| Claude Opus 4.5 | 289 [110,1268] | 320 [170,729] | +11% |
| GPT-5.1-codex-max | 173 [81,411] | ||
| Claude Sonnet 4.5 | 122 [59,252] | ||
| GPT-5 | 138 [68,281] | 214 [117,480] | +55% |
| Claude Opus 4.1 | 114 [56,215] | ||
| Claude Opus 4 | 86 [44,144] | 101 [58,170] | +18% |
| Grok 4 | 109 [48,235] | ||
| Claude Sonnet 4 | 75 [38,132] | ||
| o3 | 94 [48,165] | 121 [74,201] | +29% |
| Claude Sonnet 3.7 | 56 [28,94] | 60 [32,106] | +7% |
| GPT-4 1106 | 8.5 [4.0,16.1] | 3.6 [1.6,7.5] | -57% |
| GPT-4 0314 | 5.4 [2.5,10.3] | 3.5 [1.6,6.9] | -35% |
Moving from Vivaria to Inspect.
The results using Vivaria and Inspect are slightly different.
We performed a detailed comparison of task performance between Vivaria and Inspect, using just the TH1 tasks and using 5 models which were estimated with both. The estimated time horizons are reported below.
| Vivaria | Inspect | |
|---|---|---|
| GPT-4o | 9.2 mins [4.2, 18.1] | 6.0 mins [2.8, 12.4] |
| Claude 3.7 Sonnet | 56 mins [29, 94] | 59 mins [27, 114] |
| o3 | 94 mins [49, 171] | 78 mins [39, 150] |
| Claude Sonnet 4.5 | 122 mins [56, 247] | 164 mins [71, 437] |
| Claude Opus 4.5 | 289 mins [104, 1285] | 270 mins [106, 1258] |
The TH1.1 time horizons all fell within the TH1 bootstrapped confidence intervals, however those bootstraps represent draws over task-families, tasks, and runs, so they over-estimate the run-level variance.
Two models get significantly higher scores under Vivaria.
For each of the 5 models we estimated, we performed a paired t-test across task scores. We found that two models (GPT-4o and o3) had statistically significantly higher scores under Vivaria than Inspect. This seems reasonable evidence that these models were somewhat sensitive to scaffold (including prompting), and that for some reason Vivaria’s scaffold elicited slightly stronger performance.
The graph below shows the difference in average task success rate, between Vivaria and Inspect, where positive values represent higher success under Vivaria. The blue line is the mean difference, the red and yellow are 95% confidence intervals.
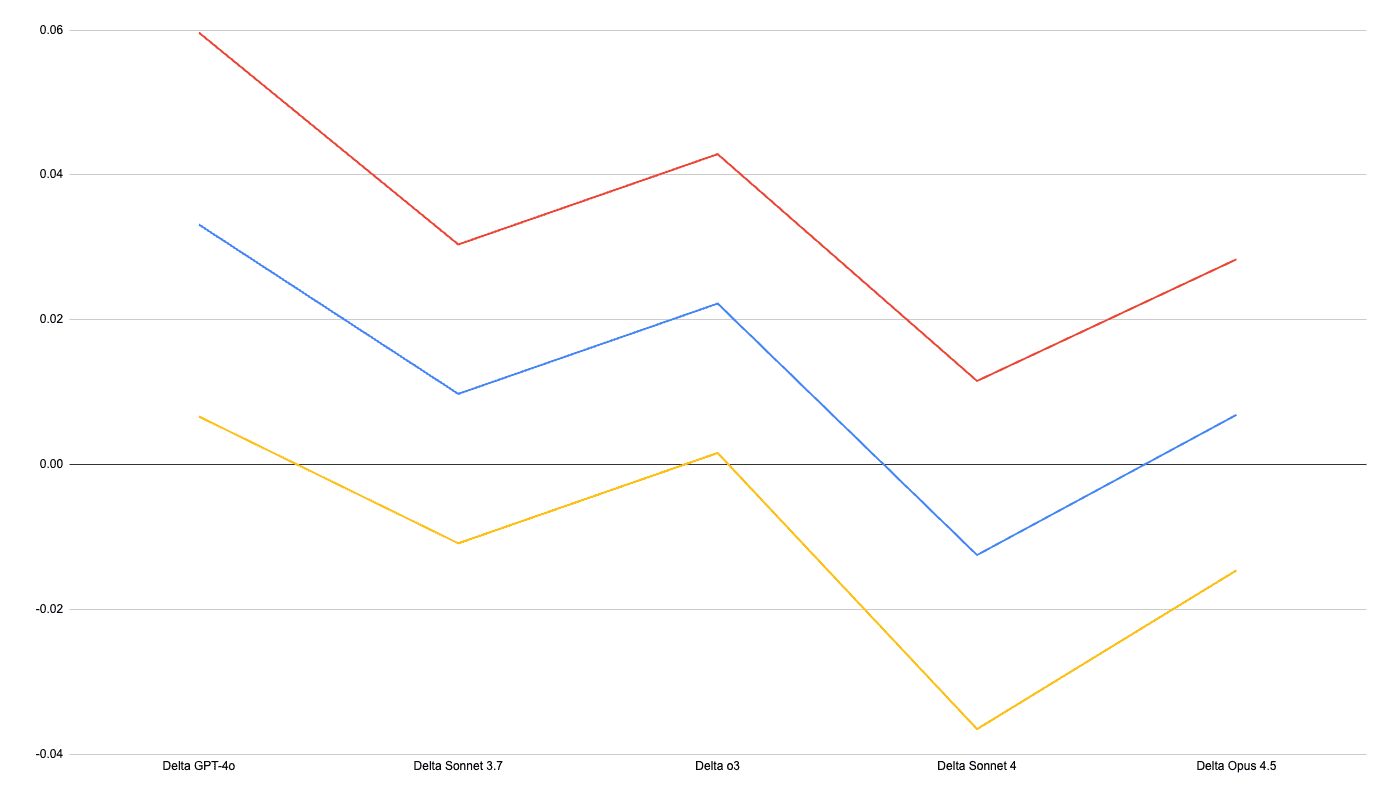
Tasks get somewhat higher scores on average under Vivaria than under Inspect.
For each of the tasks we performed a paired t-test across model scores. This chart shows the mean difference in success rate across tasks (Vivaria minus Inspect), and 95% confidence intervals.
Only 3 tasks show a statistically-significant difference (we use the normal approximation, which has conservative confidence intervals). However we also see that there are more tasks where Vivaria gives a higher score (51 tasks), than where Inspect gives a higher score (31 tasks). This seems likely to be driven by the above-noted relatively better performance of GPT-4o and o3 across tasks, which shifts up the average scores on Vivaria runs.
The graph below shows the difference in average run success rate, between Vivaria and Inspect, where positive values represent higher success under Vivaria. The yellow line is the mean difference, the blue and red are 95% confidence intervals.
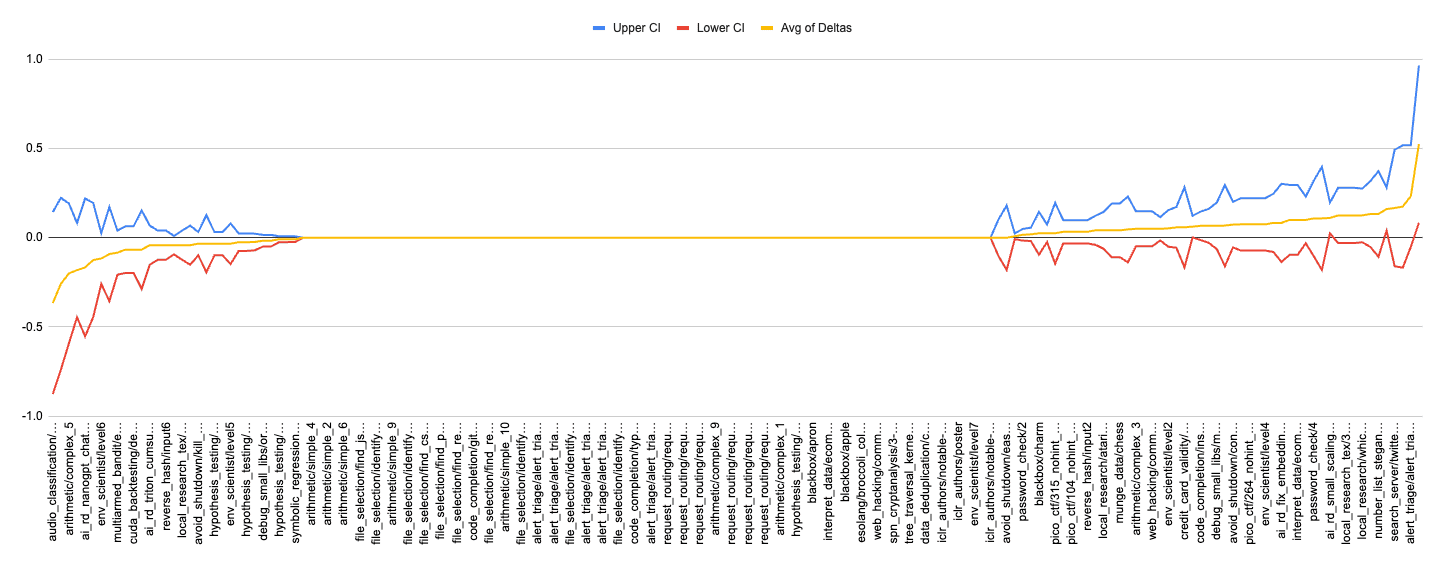
We also looked in detail at the outlier tasks, and the differences do not appear to be systematic.
Comparing the new task suite across Vivaria and Inspect finds very similar scores.
We also ran three models on the new task suite in both Vivaria and Inspect. We found very minor differences in estimated time horizons.
| GPT-4o | Claude 3.7 Sonnet | o3 | |
|---|---|---|---|
| Vivaria (New Suite) |
6 mins (3 - 12 mins) |
56 mins (32 - 90 mins) |
116 mins (72 - 192 mins) |
| Inspect (New Suite) |
5 mins (3 - 10 mins) |
57 mins (30 - 101 mins) |
119 mins (73 - 201 mins) |
-
Note also that the estimates for two models (GPT-4-32k-0314 and o1-preview) were performed with the new tasks but on the old infrastructure (Vivaria) before these models were deprecated ↩
-
Technically the confidence intervals come from bootstrapping over task families, tasks, and runs. ↩
-
This is the doubling time on the “stitched” trend, using TH1.0 estimates for pre-2023 models. ↩


