Introduction
AI agents are improving rapidly at autonomous software development and machine learning tasks, and, if recent trends hold, may match human researchers at challenging months-long research projects in under a decade. Some economic models predict that automation of AI research by AI agents could increase the pace of further progress dramatically, with many years of progress at the current rate being compressed into months. AI developers have identified this as a key capability to monitor and prepare for, since the national security implications and societal impacts of such rapid progress could be enormous.
While some progress is being made on measuring AI R&D capabilities, significant disagreement remains in interpreting the implications of these measurements. There are reasons to think that if AI systems become able to automate AI R&D, the resulting acceleration of progress would be economically transformative, but others are skeptical of such dramatic effects. To better understand how to interpret relevant evaluation results, and identify where experts have the greatest disagreements, we have worked with the Forecasting Research Institute to conduct an initial pilot survey of 8 AI forecasting domain experts1 (henceforth “experts”) and 10 “superforecasters”2, eliciting their predictions of future acceleration and societal impacts conditional on several hypothetical evaluation results.
This pilot study tasked experts and superforecasters with estimating the likelihood of (several variations on) two key events:
- Rapid acceleration from automated AI R&D: If AI achieves parity with top human researchers on various AI R&D tasks by 2027, what is the probability that a >3X increase in the rate of AI progress follows (where we start to see the equivalent of the past 3 years of AI improvements, from before ChatGPT through to the recent release of GPT-5, every year)?
- Transformative impacts of rapid acceleration: If such a dramatic increase in the rate of AI progress occurs, will it lead to extreme effects on society, such as unprecedented changes in global energy consumption (halving or doubling in one year) or an increase in the likelihood of catastrophic outcomes?
We believe these would be unprecedented outcomes if realized, with far-reaching consequences for the world. If we saw a three-fold increase in the pace of AI progress—when maintaining the current rate of progress is already demanding a potentially unsustainable pace of investment—it might indicate that AI systems are having truly transformative effects on R&D productivity, which could rapidly propagate to other parts of the economy. Because we are very uncertain about where this might lead and how it would change society, we picked a few robust and broad indicators of extremely rapid growth (unprecedented increases to global energy consumption) and instability (increase in risk of COVID-level disasters and unprecedented reductions in global energy consumption) as forecasting targets, to serve as proxies for the possibility of broad transformative changes to society.
We worked with FRI and other experts to operationalize these questions as carefully as we could for this pilot. This involved developing a definition of “3X acceleration of progress” in terms of acceleration of the pace of growth in “effective compute” (see below) that hopefully gets close to our intended meaning. Despite these efforts we still see indications that some participants may have interpreted these concepts differently in their rationales (see the full write-up for details on the operationalization and reviews of participant rationales).
What does a “3X acceleration of effective compute scale-ups” mean?
We asked forecasters to predict:
Intuitively, we are attempting to capture the idea that during some two year period before 2029, the amount of progress that happened in one year between 2018 and 2024 now happens every 4 months. “Effective compute” defines the progress made between two models as the compute scale-up factor that would have been needed to match the more powerful models capabilities without algorithmic innovations.
In more detail, we define the effective compute scale-up between an earlier weak model and a later more capable one as “what factor more compute would have been needed to reach the performance of the more powerful model using algorithms available at the time when the earlier model was developed, if a team had ~3 months to make adaptations to the increased amount of compute?”
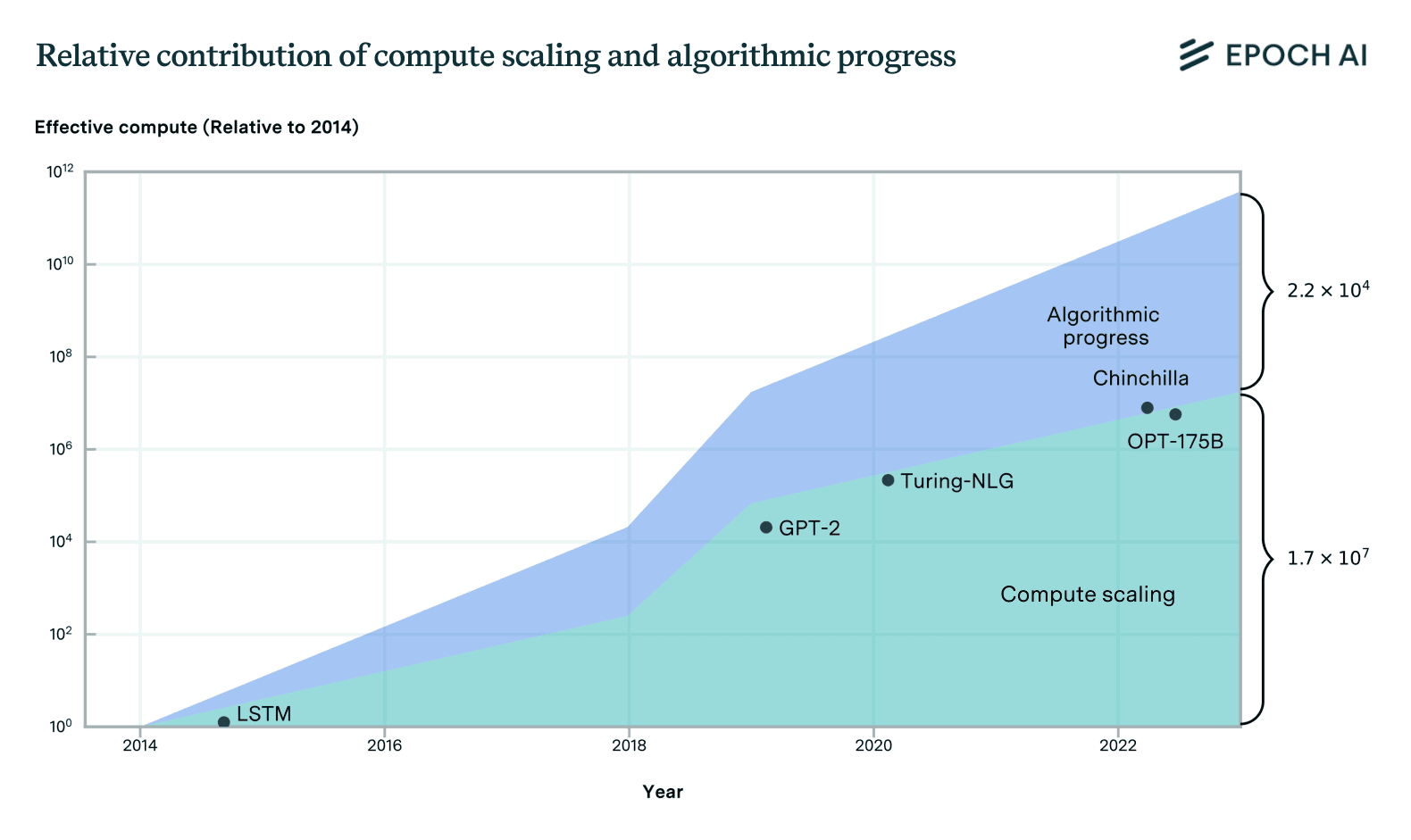
This definition combines progress from larger compute spend and improvements to algorithms into one metric (if the later model used twice the compute and had algorithms that could achieve the same performance with half the compute cost, then this represents an overall “effective compute” scale-up of 4X).
A key challenge for defining this metric is defining what it means for two models developed with different algorithms to have “the same performance”, especially when comparing models of drastically different levels of capability where no individual benchmark can provide direct faithful comparisons. The previous literature has often used the perplexity of text prediction as the grounding performance measurement, but this doesn’t capture improved post-training approaches like reasoning models. For our purposes we instead ground this through a (theoretical) panel of experts using benchmarks and other investigations to determine the relative economic value of the models. See the full write-up from FRI for details.
Results
Here we present some of the key results from the survey. For more details of the operationalizations of the forecasting questions and more detailed results see FRI’s write-up.
Probability of rapid acceleration from AI R&D
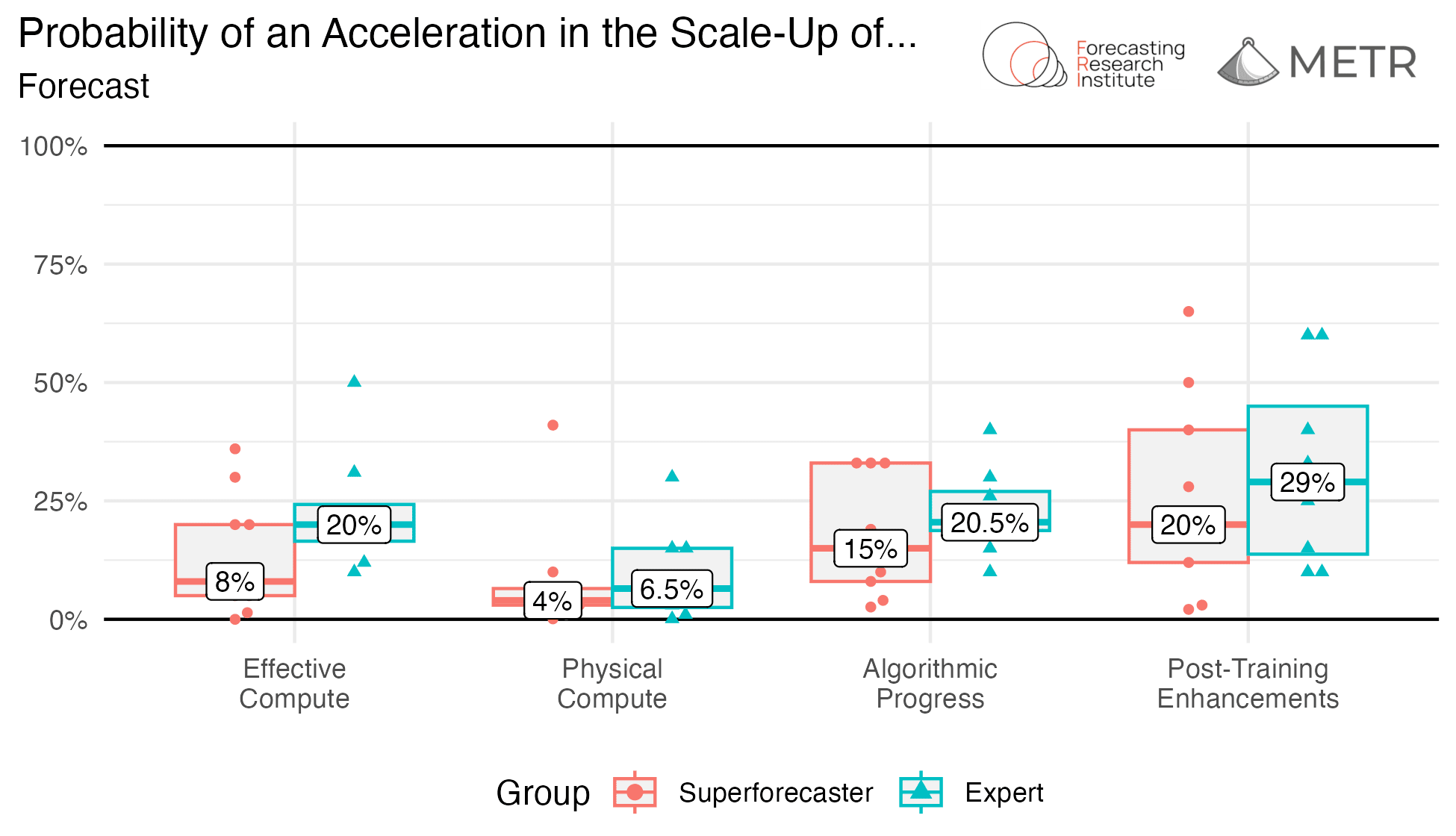
Experts and superforecasters both find a three-fold acceleration of effective compute scale-up by 2029 plausible but unlikely, with experts giving it a median 20% chance and superforecasters 8%. They both agree that a significant acceleration in physical compute scaleup looks unlikely, while post-training enhancements are most likely to accelerate rapidly.
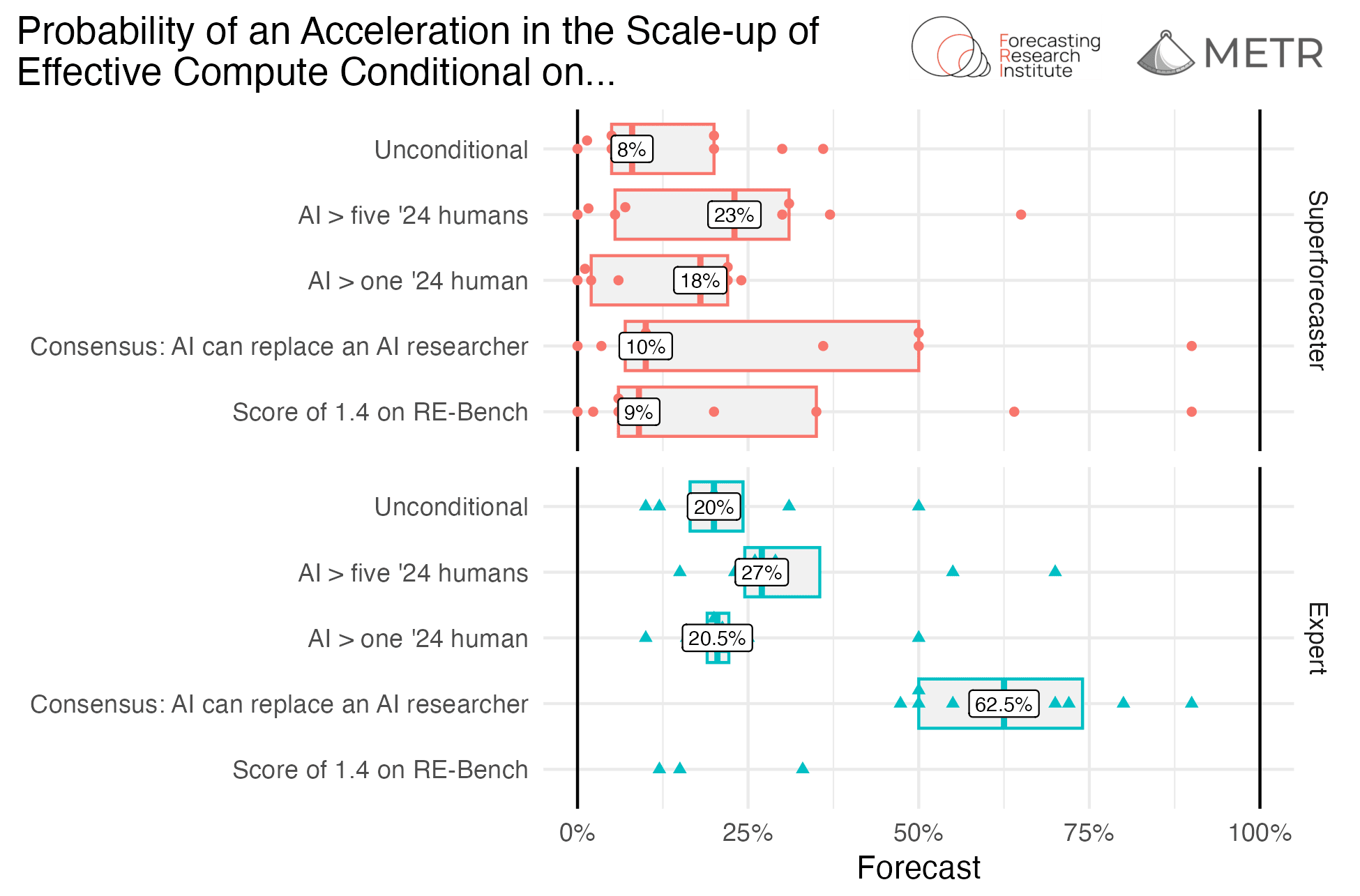
We find that experts and superforecasters converge somewhat toward a higher likelihood of three-fold acceleration (to a median of 20.5% and 18% respectively, see Fig. 2) when conditioning on evaluations showing AI systems doing better than human researchers at open-ended month-long research projects. On the other hand, both experts and superforecasters agree that scores exceeding human performance on the day-long tasks in RE-bench would not be significantly informative, since many already expect the benchmark to be saturated by 2027.34 This provides some partial support for thinking that longer horizon lengths are predictive of the ability to automate AI R&D (though there may be other differences between the hypothetical research projects and RE-bench scores that forecasters view as important).5
Other conditionals see more disagreement, with experts believing that consensus among a panel of experts that AI can replace human researchers would make three-fold acceleration more likely than not, whereas some superforecasters are much more skeptical.
Probability of extreme societal events
Experts and superforecasters also strongly disagree about the likelihood of all four extreme societal events that we asked about, with superforecasters giving a median risk estimate below 0.5% for all outcomes (compared to a median risk estimate of over 18% for all outcomes from the experts).
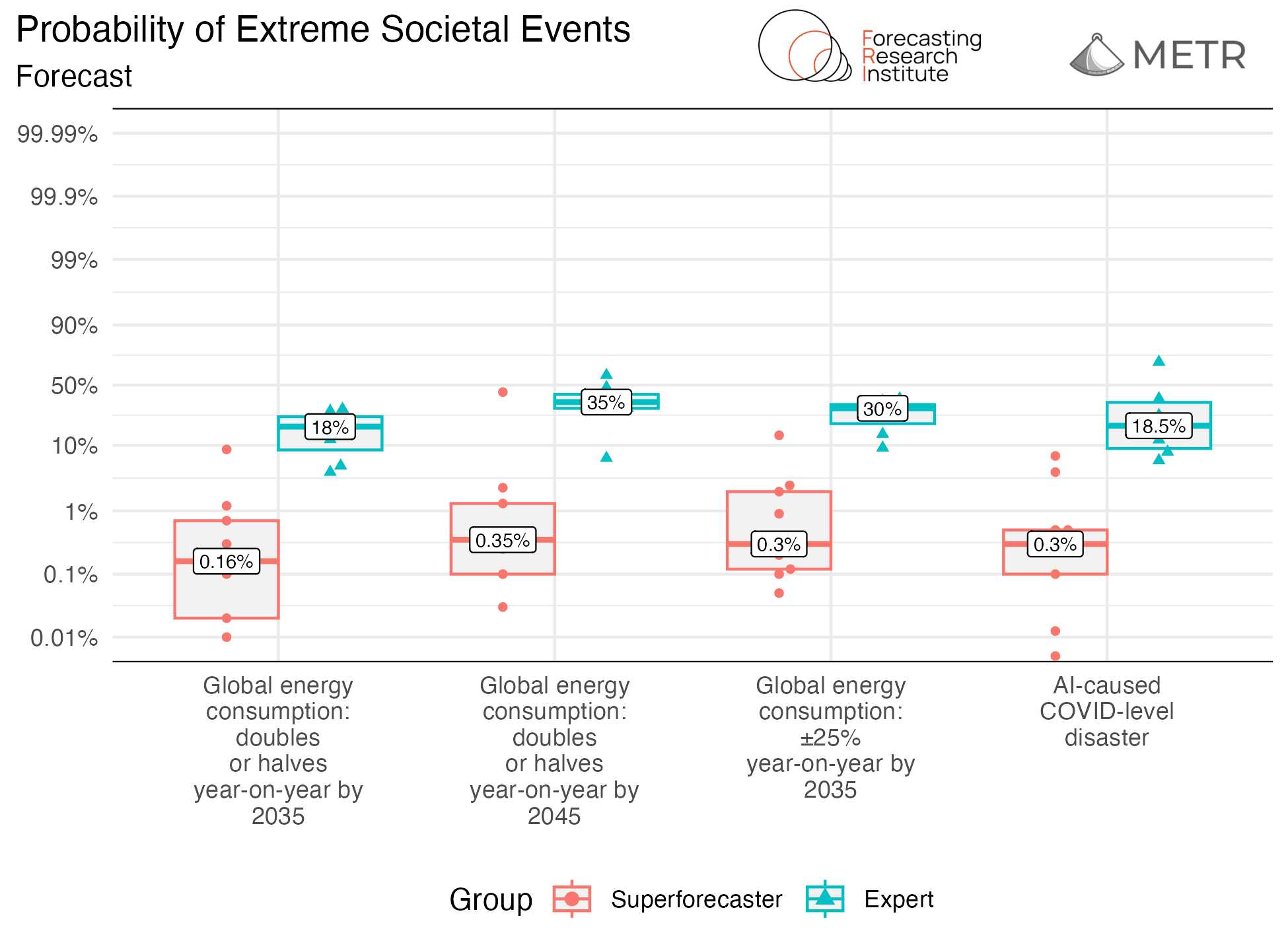
Conditioning on a three-fold (or even ten-fold) acceleration does not close this gap in the predictions of the two groups, though both groups forecast significantly higher probabilities of extreme societal events. The relative changes in risk were similar for the two groups, though given the superforecasters’ baseline level of risks were so low, their relative change was minimal in absolute terms.
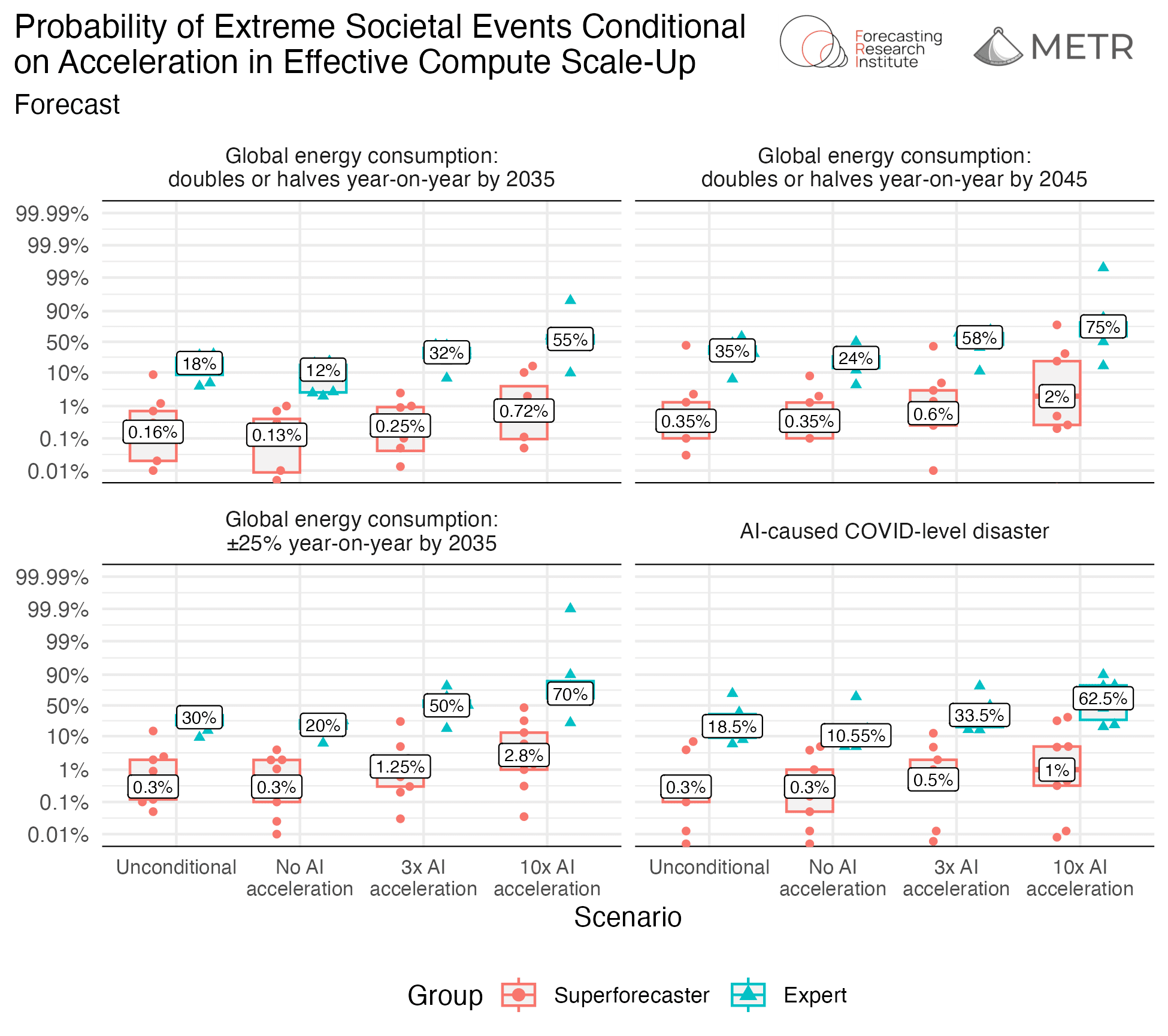
Rationales show that experts generally took a threefold effective compute acceleration to imply artificial general intelligence (AGI), and predicted AGI causing massive change in energy consumption. Superforecasters are split on what the condition implies about AGI and skeptical about AGI being likely to cause energy consumption change or COVID-level disasters, due to technical and physical barriers and human intervention. For more about participant rationales, see the full write-up.
Conclusion
We found that experts and superforecasters broadly agree that dramatic acceleration of AI progress could result from automation of AI R&D, and that observing whether AI systems end up competitive with humans on month-long, open-ended research projects resolves most of their disagreement on this question. However, the two groups disagree strongly about how likely this is to lead to unprecedented societal impacts. We think it is worth more deeply exploring the source of this disagreement before expanding this pilot to a larger and more representative survey.
As this is a pilot study with only a small sample of participants, and relies on subjective judgment-based forecasts, these results should only be taken as suggestive evidence of the likely impacts of AI R&D capabilities and acceleration in effective compute scale-up. In particular, some of our aggregate statistics are fragile as participants disagree by several orders of magnitude on several questions.
Several of the “extreme societal events” considered are unprecedented, and may require intense societal preparation to handle appropriately, if they come to pass. Resolving disagreements in this area (by building longer-horizon AI R&D evaluations or tracking other acceleration metrics, and by more carefully modeling the potential impacts of such automation) is crucial for future work.
The full write-up from FRI covers these forecast results in much more detail, including:
- Detailed operationalizations of these questions
- Participants’ individual update profiles on the likelihood of a threefold acceleration in effective compute scale-up conditional on various AI R&D scenarios and discussions of their rationales.
- How forecasts vary by accuracy on a set of unrelated, general knowledge probability questions.
-
AI forecasting domain experts were invited based on either having 1) technical research experience in AI/ML, or 2) experience forecasting AI progress. Out of the 8 experts, 1 had a doctorate in computer science, 1 had a masters degree in an AI-relevant area, and a further 3 had research experience in machine learning. All experts had some level of experience with forecasting trends in AI. This sample is not representative of general domain experts in AI, which is a limitation of this pilot survey. ↩
-
Non-expert forecasters in this study are all technically “superforecasters™”, which is a term used to denote someone who either were in the top 2% of forecasters in the IARPA ACE tournament, in one of the four years it was conducted, or achieved high accuracy on Good Judgment Open, a forecasting platform, run by Good Judgment Inc. ↩
-
Participant rationale: “This [Score of 1.4 on RE-Bench] seems very likely to happen, as 1.4 is roughly the average of the best humans scores across these tasks, and I think “superhuman coding” is essentially the baseline scenario at this point, barring some broader systemtic disruption.” ↩
-
Participant rationale: “My impression, with not a lot of time looking at this, is at least 50% chance of achieving this result [Score of 1.4 on RE-Bench]. While the authors of the tasks talk about them being novel, they still appear to be static and there aren’t that many tasks (yet). That means there will be some training to the test that takes place, even if unintentional, I think. As with teaching to the test, you can achieve results without achieving broad transfer of skills.” ↩
-
Participant rationale: “How much of AI R&D does this benchmark [RE-Bench] capture? Novelty and open-ended planning seem important to accelerating AI R&D a lot (some evidence from https://epoch.ai/blog/interviewing-ai-researchers-on-automation-of-ai-rnd), and these skills do not seem captured well by this benchmark. Compared to the Large Novel ML Research Project tasks I considered before [the month-long open ended research projects], RE-Bench appears to be shorter-horizon and less difficult overall…An easier benchmark, and it’s only just outperforming the best humans.” ↩


