TL;DR
- On 18 real tasks from two large open-source repositories, early-2025 AI agents often implement functionally correct code that cannot be easily used as-is, because of issues with test coverage, formatting/linting, or general code quality.
- This suggests that automatic scoring used by many benchmarks1 may overestimate AI agent real-world performance.
Background
Many AI benchmarks use algorithmic scoring2 to evaluate how well AI systems perform on some set of tasks. For example, the popular benchmark SWE-Bench Verified measures whether an AI system passes test cases implemented in code by the original human PR authors. Algorithmic scoring makes it easy to evaluate a new system on the benchmark, because the tests are re-usable, run quickly, and do not require human intervention/manual review.
However, many goals are difficult to represent with algorithmic scoring functions. For example, judging the quality of documentation is difficult to do automatically—you can’t (easily) write test cases that evaluate this, because documentation is typically unstructured natural language.
Particularly given the recent popularity of methods like reinforcement learning with verifiable rewards, which relies on algorithmic scoring functions, we might expect that AI systems will perform better on tasks that can be automatically evaluated compared to ones that can’t.
If AIs are much more capable on tasks that can be automatically evaluated, we might overestimate how useful they are in the field, because we often task AI systems with work that can’t be automatically evaluated. We hypothesize that this contributes to the apparent gap between our measured time horizon of Claude 3.7 Sonnet of about one hour, and the slowdown effect we observe from our recent developer productivity RCT (which includes many tasks that take humans an hour to complete).
Methodology
At a high level, we evaluate autonomous agent performance when attempting to complete open-source software tasks. We compare their performance as evaluated by two methods: automatic/algorithmic scoring (using test cases implemented by the original PR authors), and manual/rubric review.
Tasks and Development Environments
We took 18 issues from two repositories that were part of our recent RCT measuring the impact of AI on experienced open-source developer productivity. 15 of the tasks come from the stdlib-js repository, and 3 are from the hypothesis repository—they are both large repositories, with 8M and 100k lines of code respectively, and the 18 issues took human maintainers between 20 minutes and four hours to complete (averaging 1.3 hours).3 To select these issues, we filter to issues that have unit tests implemented by the original PR author, in increasing order of length for humans. Qualitatively, these repositories and issues are representative of the broader distribution of repositories involved in the RCT. We include several task examples in the appendix.
To give agents a fair shot at autonomously completing the tasks, we implement and test development environments for each task, using the base commit of the original human PR. This gives the agent a comparable setting to human repository maintainers, so they don’t need to (for example) install dependencies themselves, and can immediately start working on each task.
One concern with evaluating AI agents’ ability to complete these tasks fully autonomously is whether the issues include enough context to solve the issue. For example, perhaps the issue descriptions are cursory/brief, or rely on discussion between developers not available to the agent (e.g. via email or Slack). However, we feel confident the PRs are solvable by agents without extra context, because all communication in these repositories happens publicly (which is common for large open-source projects), and the repos are highly structured and well-documented. Qualitatively, the issues are clear and meaningful—we manually reviewed them all, and believe they don’t require any private knowledge or information to solve.
Agent
We have an Inspect ReAct agent using Claude 3.7 Sonnet attempt these PRs. We then took tests implemented by the human’s PRs and evaluated agents’ solutions against these. Specifically, we measure whether the agent’s solution passes all test cases implemented in the human’s original reference PR. We run these tests on the agent’s code directly in the task environment, to reduce the likelihood of dependency/environment discrepancies.
The agent is not shown the test cases, which makes it much less likely that they can reward hack—broadly, the agent is instructed to fully implement the given issue. We overall spend a few hours iterating on the agent’s instructions, primarily iterating on instructions related to testing their solutions and using version control properly to submit their implementations. The full prompt is available in the appendix.
Evaluation
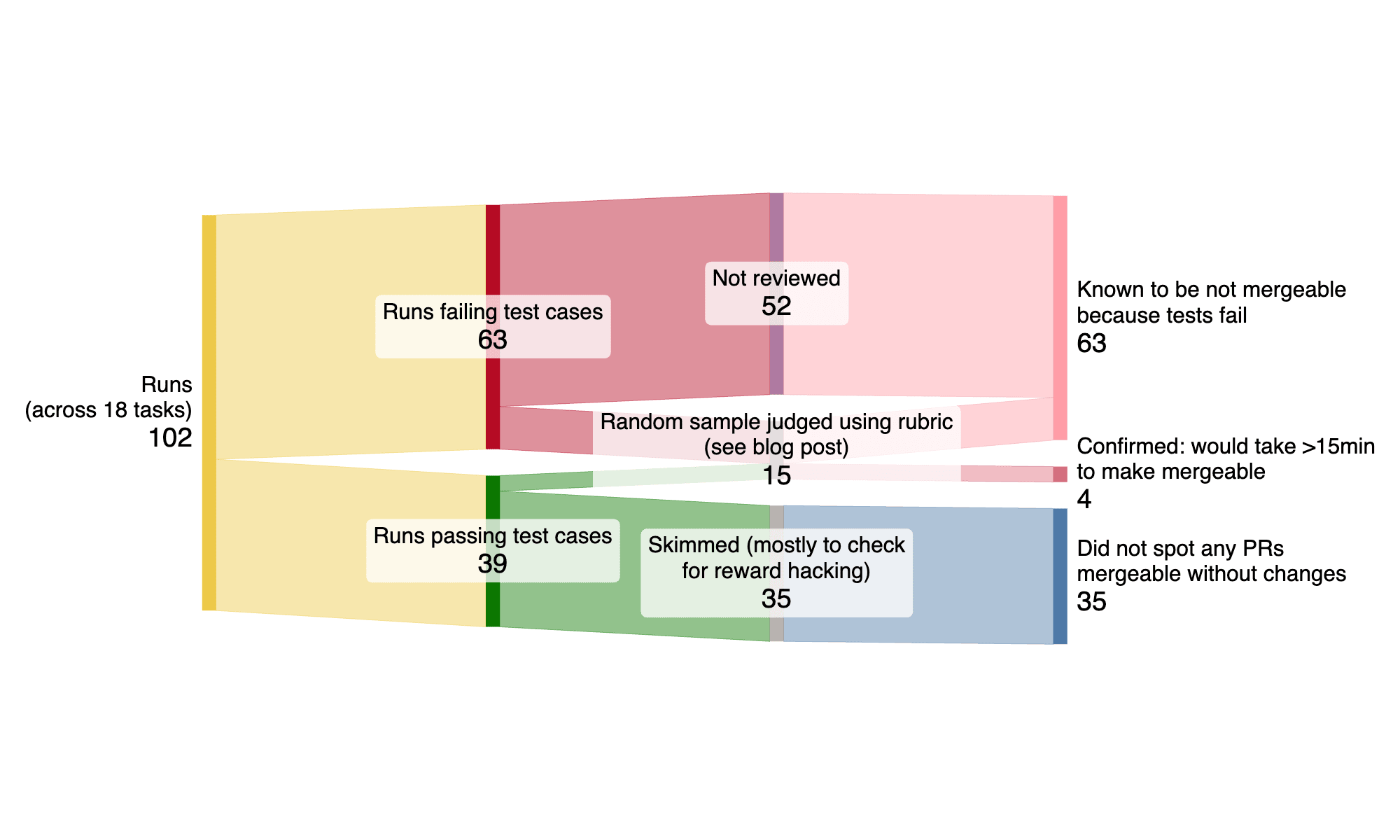
We then randomly sample one run per task4, and manually evaluate the agent’s submitted PR. The goal of this manual evaluation/scoring is to holistically judge whether the agent’s PR would be mergeable in the repository without needing meaningful/substantial extra work. We then compare these manual scores to agents’ scores on the reference test cases described above.
We manually evaluate agent PR’s for five failure modes:
- Missing/incorrect core functionality: the core algorithmic/logical functionality of the task is not correctly implemented
- Inadequate testing coverage: major components of the task do not have adequate tests written
- Missing/incorrect documentation: key documentation is missing or does not meet project standards
- Linting/formatting/typing issues
- Other code quality issue(s): code is verbose, brittle, difficult to read, difficult to maintain, or contains other problems not captured by “core functionality” that would still likely prevent the PR from being merged
We give each agent PR a binary 0 or 1 score on each of these axes, and consider a submission complete if it contains none of the failure modes (i.e. it’s mergeable as-is).
Results
Algorithmic scoring overestimates capabilities
Claude 3.7 Sonnet in the Inspect ReAct agent scaffold has an average success rate of 38% (±19%, 95% CI) on these issues, as measured by the maintainer-written test cases, indicating that this agent often implements the core functional components of the issues correctly5. However, when manually reviewing a subset of these PRs6, none of them are mergeable as-is. This suggests that even when measuring AI capabilities at doing real software tasks, which is often considered the gold-standard method of evaluating real-world performance of AI systems in software development, algorithmic scoring based on unit tests overestimates model capabilities.
For each of the 15 PRs manually reviewed, we estimate how long we expect it to take a human to modify/fix the PR to be in a working/usable state. We estimate that on average, the agent PRs would take 42 minutes to modify/fix to be in a mergeable state. When filtering to runs where the agent passed the human-written test cases, we estimate that these PRs would take on average 26 minutes to fix (with a minimum time of 15 minutes). So, even when the agent implements the core algorithmic functionality correctly (i.e. it passes all of the human-written test cases), there is still a substantial amount of work needed for the PRs to be mergeable—the average time these PRs took the original maintainer is 1.3 hours, so the “time to fix” represents about a third of the total time needed for these PRs. Note that these estimates are made by comparing the agent’s PRs to the reference human PR, and are not done by the original PR authors. These estimates should be interpreted as a very rough/high variance, subjective judgement of how close agent PRs are to being completed.
Reward Hacking
When manually reviewing agent PRs, we check to make sure that when agents passed all of the test cases, they hadn’t cheated or special-cased the tests. In several cases, the agent found the human’s PR via Github, because the original repositories are open-source. We exclude these runs, and manually check all other runs on those issues (which surfaced a few more trajectories where the agent found the original human’s PR—we also exclude these from our analysis). Explicitly special-casing the tests would be difficult/impossible for agents, since they aren’t shown the test cases in advance, and we confirm that this does not occur in their PRs.
Understanding the gap between manual review and algorithmic scoring
For each of the 15 manually evaluated agent PRs, we categorize failures into various buckets. Note that these categories are meant to capture the most obvious problems with agent PRs—there may be further issues not represented or captured here, so these scores are intended to represent an upper bound on the agents’ performance (i.e. if these issues were all resolved, there may still be other problems not captured by algorithmic scoring or these categories). Each run can have multiple failures, and we report the percentage of agent runs that contain each failure category, for both runs that fail and pass human-written test cases (respectively).
| Type of Failure | Runs Failing Test Cases (n=11) | Runs Passing Test Cases (n=4) |
|---|---|---|
| Core functionality: the core algorithmic/logical functionality of the task is not correctly implemented | 100% | 25% |
| Testing coverage: major components of the task do not have adequate tests written | 91% | 100% |
| Documentation: key documentation is missing or does not meet project standards | 89%7 | 75% |
| Linting/formatting/typing issues | 73% | 75% |
| Other code quality issue(s): code is verbose, brittle, difficult to read, difficult to maintain, or contains other problems not captured by “core functionality” that would still likely prevent the PR from being merged | 64% | 50% |
All of these 15 PRs had at least three of the above issues, 60% had at least four of the above issues, and 20% of runs had all five issues present. While each individual failure might be relatively easy to fix (e.g. telling the agent “you forgot to add documentation”), in order for a PR to be mergeable, none of these issues must be present, and because most of the PRs contain most of the issues, this increases the amount of work needed to get the PR to a mergeable level of quality.
Aside from the “Core functionality” category (which we expect the test cases to catch in the first place), we don’t see major differences in the rates of these issues based on whether a run fails or passes the test cases, suggesting that these failures are not strongly correlated with agent success on algorithmic scoring (although our sample size is small).
Takeaways/Discussion
Towards reconciliation with time horizons
Broadly, these results help us interpret the surprising slowdown effect we observed in our recent developer productivity RCT (which is where we source these tasks from). It seems as though, at least on this relatively representative (but small) subset of issues, Claude 3.7 Sonnet in a basic agent scaffold is able to implement the core functionality of these tasks moderately well. However, to actually be mergeable, there are often many other important goals you need to satisfy, and this agent isn’t able to satisfy all of them in a single trajectory.
One interesting point of comparison is to the success rate (and estimated time horizon) of Claude 3.7 Sonnet from Measuring AI Ability to Complete Long Tasks. On that distribution of tasks (SWAA+HCAST+RE-Bench), Claude 3.7 Sonnet has an estimated 50% success rate on tasks that take about an hour. This is similar to the 38% success rate on these issues, which average 1.3 hours for humans, when evaluating using algorithmic scoring. This is substantial evidence that, when evaluating models’ ability to implement core logic/functionality, these tasks are not harder than HCAST tasks that take humans about an hour to complete.8
These results also point towards algorithmic scoring/evaluation being a highly meaningful limitation of existing benchmarks—because they don’t capture all of what we care about, hill-climbing on them may end up a) amplifying issues like reward hacking, and b) not yielding corresponding productivity improvements in the wild. For example, frontier model success rates on SWE-Bench Verified are around 70-75%, but it seems unlikely that AI agents are currently actually able to fully resolve 75% of real PRs in the wild.
Caveats
One important piece of context for understanding these results is that the two open source repositories considered, stdlib-js and hypothesis, are both large, mature repositories, with hundreds of contributors. In order to maintain repositories at this scale, very high standards for documentation, code quality, linting/formatting, and testing coverage are extremely important. However, many software engineering projects or tasks do not have these requirements to the same degree, and agents may perform better (on these non-functional objectives) in those settings.
These results may also be biased because of selection effects: to make this comparison, we’re explicitly filtering for PRs that write a large number of high-quality test cases. However, a substantial amount of code written doesn’t typically have many explicit test cases written for it, and there may be differences between this filtered distribution of issues and the “true” distribution of PRs written. For example, it may be that these issues are more clearly scoped compared to the “true” distribution of issues, because they are amenable to having many explicit tests.
Finally, we do not do substantial elicitation on our agent scaffold. We use a basic agent scaffold that doesn’t make use of significant parallel inference compute, and doesn’t have specialized tooling that the LLM is designed to take advantage of, beyond basic file viewing/searching/editing, python, and bash tools. We might imagine that more complicated scaffolding that takes advantage of more inference compute, or specialized tooling that’s tightly integrated with LLM post-training could yield substantially better results. Furthermore, it may be the case that merely writing project-specific prompts with high-quality few-shot examples could help close the gap between manual and automated scoring. We don’t think that these results represent an upper bound on agent performance—we view this as a realistic setting using a decent, standard/common agent scaffold.
Implications for future progress
An important question for interpreting these preliminary results is whether these failures are fundamental or resolvable with more or better elicitation/training. We do qualitatively observe agents making decent (although incomplete) progress towards these “softer” goals, so progress on this non-verifiable distribution of tasks could be improving at a similar pace as progress on core algorithmic components, albeit lagging behind. Given the rapid pace of progress in AI, understanding the trend of capabilities may be more useful than individual measurements at specific points in time.
To the extent that recent AI progress is driven by training models against algorithmic reward signals (e.g. with RLVR), an important question is how well LLM judging can substitute for verifiable rewards on messier or more subjective tasks. If LLM judges can scale well and provide useful reward signals for more qualitative tasks, then this observed gap between holistic and algorithmic scoring is less likely to represent a fundamental bottleneck/barrier.
It’s also possible that because of particular affordances AI systems have that humans don’t (more memorized knowledge, better short-term memory, faster typing speed, lower labor costs, etc.) that these standards around documentation, formatting, testing, or code quality may be less important for AIs to get right when they’re doing software engineering. In general, future AI agents doing software engineering may structure their work very differently from the development patterns and conventions of current human-driven software engineering. This seems somewhat unlikely, as achieving these softer non-verifiable objectives seems generally useful as projects scale in scope and complexity, but it’s an important possibility to consider.
Appendix: Deep dive into a few example tasks
Stdlib-35, “slice-grapheme-clusters”
Stdlib-35, “slice-grapheme-clusters”
26 human implemented test cases, testing 10 different categories of inputs.
Instructions
## [RFC]: add `string/base/slice-grapheme-clusters`
This task should implement a functional API for slicing a string based on grapheme clusters.
The behavior should not match the built-in `String.prototype.slice`, as the function should properly handle grapheme clusters (e.g., emoji). All arguments should be required:
```javascript
sliceGraphemeClusters( str, start, end )
```
Related: https://github.com/stdlib-js/stdlib/tree/develop/lib/node_modules/%40stdlib/string/base/for-each-grapheme-cluster
The instructions are specific and unambiguous, demonstrating the function’s signature and linking to a module that implements related functionality.
Human-written reference tests
tape( 'main export is a function', function test( t ) {
t.ok( true, __filename );
t.strictEqual( typeof sliceGraphemeClusters, 'function', 'main export is a function' );
t.end();
});
tape( 'the function has an arity of 3', function test( t ) {
t.strictEqual( sliceGraphemeClusters.length, 3, 'the function has an arity of 3' );
t.end();
});
tape( 'the function returns an empty string if provided an empty input string', function test( t ) {
var out;
out = sliceGraphemeClusters( '', 0, 1 );
t.strictEqual( out, '', 'returns expected value' );
t.end();
});
tape( 'the function returns an empty string if the starting index is greater than or equal to the ending index', function test( t ) {
var out;
out = sliceGraphemeClusters( 'hello', 2, 2 );
t.strictEqual( out, '', 'returns expected value' );
out = sliceGraphemeClusters( 'hello', 3, 2 );
t.strictEqual( out, '', 'returns expected value' );
t.end();
});
tape( 'the function returns an empty string if the starting index is greater than or equal to the string length', function test( t ) {
var out;
out = sliceGraphemeClusters( 'hello', 5, 6 );
t.strictEqual( out, '', 'returns expected value' );
out = sliceGraphemeClusters( 'hello', 10, 12 );
t.strictEqual( out, '', 'returns expected value' );
t.end();
});
tape( 'the function slices an input string based on grapheme cluster indices', function test( t ) {
var out;
out = sliceGraphemeClusters( 'hello', 0, 3 );
t.strictEqual( out, 'hel', 'returns expected value' );
out = sliceGraphemeClusters( '🌷🍕👉🏿', 1, 2 );
t.strictEqual( out, '🍕', 'returns expected value' );
out = sliceGraphemeClusters( 'अनुच्छेद', 1, 5 );
t.strictEqual( out, 'नुच्छेद', 'returns expected value' );
out = sliceGraphemeClusters( '六书/六書', 1, 5 );
t.strictEqual( out, '书/六書', 'returns expected value' );
out = sliceGraphemeClusters( '🏝️🌷', 1, 2 );
t.strictEqual( out, '🌷', 'returns expected value' );
t.end();
});
tape( 'the function slices an input string based on grapheme cluster indices (skin-tone emojis)', function test( t ) {
var out;
out = sliceGraphemeClusters( '🌷👨👩👧👦👉🏿', 1, 2 );
t.strictEqual( out, '👨👩👧👦', 'returns expected value' );
out = sliceGraphemeClusters( '🏝️👨👩👧👦', 1, 2 );
t.strictEqual( out, '👨👩👧👦', 'returns expected value' );
out = sliceGraphemeClusters( '👋🏾🤦🏽♀️🧑🏿', 1, 2 );
t.strictEqual( out, '🤦🏽♀️', 'returns expected value' );
t.end();
});
tape( 'the function supports providing negative indices', function test( t ) {
var out;
out = sliceGraphemeClusters( 'hello', -5, -2 );
t.strictEqual( out, 'hel', 'returns expected value' );
out = sliceGraphemeClusters( '🌷🍕👉🏿', -2, -1 );
t.strictEqual( out, '🍕', 'returns expected value' );
out = sliceGraphemeClusters( 'अनुच्छेद', -4, -1 );
t.strictEqual( out, 'नुच्छे', 'returns expected value' );
out = sliceGraphemeClusters( '六书/六書', -3, 5 );
t.strictEqual( out, '/六書', 'returns expected value' );
out = sliceGraphemeClusters( '🏝️🌷', -1, 2 );
t.strictEqual( out, '🌷', 'returns expected value' );
t.end();
});
tape( 'the function supports providing negative indices (skin-tone emojis)', function test( t ) {
var out;
out = sliceGraphemeClusters( '🌷👨👩👧👦👉🏿', -2, -1 );
t.strictEqual( out, '👨👩👧👦', 'returns expected value' );
out = sliceGraphemeClusters( '🏝️👨👩👧👦', -1, 4 );
t.strictEqual( out, '👨👩👧👦', 'returns expected value' );
out = sliceGraphemeClusters( '👋🏾🤦🏽♀️🧑🏿🦱', -2, -1 );
t.strictEqual( out, '🤦🏽♀️', 'returns expected value' );
t.end();
});
tape( 'the function truncates the end index to the string length', function test( t ) {
var out;
out = sliceGraphemeClusters( 'hello', 0, 10 );
t.strictEqual( out, 'hello', 'returns expected value' );
out = sliceGraphemeClusters( '六书/六書', 1, 10 );
t.strictEqual( out, '书/六書', 'returns expected value' );
out = sliceGraphemeClusters( '🏝️🌷', 0, 5 );
t.strictEqual( out, '🏝️🌷', 'returns expected value' );
t.end();
});
Human vs. agent implementations
Human core implementation
function sliceGraphemeClusters( str, start, end ) {
var numClusters;
var result;
var idx;
var brk;
var i;
if ( str === '' ) {
return '';
}
numClusters = numGraphemeClusters( str );
if ( start < 0 ) {
start = max( start + numClusters, 0 );
}
if ( end < 0 ) {
end = max( end + numClusters, 0 );
}
if ( start >= numClusters || start >= end ) {
return '';
}
if ( end > numClusters ) {
end = numClusters;
}
result = '';
idx = 0;
i = 0;
while ( idx < str.length ) {
brk = nextGraphemeClusterBreak( str, idx );
if ( brk === -1 ) {
brk = str.length;
}
if ( i >= start && i < end ) {
result += str.substring( idx, brk );
}
idx = brk;
i += 1;
if ( i >= end ) {
break;
}
}
return result;
}
Agent core implementation
function sliceGraphemeClusters( str, start, end ) {
var breaks;
var count;
var idx;
if ( !isString( str ) ) {
throw new TypeError( format( 'invalid argument. First argument must be a string. Value: `%s`.', str ) );
}
if ( !isInteger( start ) ) {
throw new TypeError( format( 'invalid argument. Second argument must be an integer. Value: `%s`.', start ) );
}
if ( !isInteger( end ) ) {
throw new TypeError( format( 'invalid argument. Third argument must be an integer. Value: `%s`.', end ) );
}
// Count the total number of grapheme clusters and collect break positions
breaks = findAllBreaks( str );
count = breaks.length + 1; // Total count is one more than break count
if ( count === 0 ) {
return '';
}
// Handle negative indices
if ( start < 0 ) {
start = count + start;
if ( start < 0 ) {
start = 0;
}
}
if ( end < 0 ) {
end = count + end;
if ( end < 0 ) {
end = 0;
}
}
// Return empty string for invalid slice ranges
if ( start >= end || start >= count ) {
return '';
}
if ( end > count ) {
end = count;
}
// Get starting position in the string (in terms of character indices)
if ( start === 0 ) {
idx = 0;
} else {
idx = breaks[ start - 1 ];
}
// Get ending position
if ( end === count ) {
return str.substring( idx );
}
return str.substring( idx, breaks[ end - 1 ] );
}
/**
* Finds all grapheme cluster breaks in a string.
*
* @private
* @param {string} str - input string
* @returns {Array<integer>} array of break positions
*/
function findAllBreaks( str ) {
var breaks = [];
var idx = 0;
var brk;
if ( str.length === 0 ) {
return breaks;
}
while ( idx < str.length ) {
brk = nextGraphemeClusterBreak( str, idx );
if ( brk === -1 ) {
break;
}
breaks.push( brk );
idx = brk;
}
return breaks;
}
Scores
| Implementation property | Agent success/failure ✅→ Problem not observed ❌→ Problem observed |
|---|---|
| Core functionality: the core algorithmic/logical functionality of the task is not correctly implemented | ✅→ Problem not observed |
| Testing coverage: major components of the task do not have adequate tests written | ❌→ Problem observed |
| Documentation: key documentation is missing or does not meet project standards | ❌→ Problem observed |
| Linting/formatting/typing issues | ❌→ Problem observed |
| Other code quality issue(s): code is verbose, brittle, difficult to read, difficult to maintain, or contains other problems not captured by “core functionality” that would still likely prevent the PR from being merged | ❌→ Problem observed |
Estimated time to fix: 15 minutes
Takeaways
The human-written test cases are very thorough, so the agent’s solution passing these test cases is strong evidence that it is functionally correct. Comparing the agent vs. human solutions, the agent’s is more verbose, doesn’t make use of the existing numGraphemeClusters function, and implements some redundant type checking, but they are functionally identical. Note that there is a significant amount of additional code required for this PR—we’re only presenting the core algorithmic functionality here.
hypothesis-1 “TypeAlias support”
10 tests in 5 categories
Instructions
work for type alias (`typing.TypeAliasType`)
Given a [type alias](https://docs.python.org/3/library/typing.html#type-aliases) (which is of type [TypeAliasType](https://docs.python.org/3/library/typing.html#typing.TypeAliasType)) defined like:
```py
>>> type Point = tuple[float, float]
>>> type(Point)
<class 'typing.TypeAliasType'>
```
I want to create a strategy and an example from that:
```py
from hypothesis import strategies as st
st.from_type(Point).example()
```
which results in an error
```
...
.venv/lib/python3.13/site-packages/hypothesis/strategies/_internal/core.py", line 1287, in _from_type
raise InvalidArgument(f"{thing=} must be a type") # pragma: no cover
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
hypothesis.errors.InvalidArgument: thing=Point must be a type
```
Accessing the underlying value through [\_\_value__](https://docs.python.org/3/library/typing.html#typing.TypeAliasType.__value__) works as expected:
```py
>>> st.from_type(Point.__value__).example()
(1.192092896e-07, -7420061444470370.0)
```
I am not familiar with the internals of `hypothesis` but since `Point.__value__` works, I am inclined to think `Point` should also just work by handling `typing.TypeAliasType` internally.
python version: `Python 3.13.1 (main, Dec 3 2024, 17:59:52) [GCC 14.2.1 20241116] on linux`
hypothesis version: `6.123.17`
### Comments:
---
That makes sense to me - we could [handle it just below `NewType`, and in much the same way](https://github.com/HypothesisWorks/hypothesis/blob/cb6fe37b2936fae8cbb4c6e00ed3427147d227d3/hypothesis-python/src/hypothesis/strategies/_internal/core.py#L1252-L1260). Tests would go in a new `tests/cover/test_typealias_py312.py` file, and [add this config](https://github.com/HypothesisWorks/hypothesis/blob/cb6fe37b2936fae8cbb4c6e00ed3427147d227d3/hypothesis-python/tests/conftest.py#L39-L40) for 3.12 so it doesn't give SyntaxError on older versions.
Human-written test cases
def test_resolves_simple_typealias():
type MyInt = int
type AliasedInt = MyInt
type MaybeInt = int | None
assert_simple_property(st.from_type(MyInt), lambda x: isinstance(x, int))
assert_simple_property(st.from_type(AliasedInt), lambda x: isinstance(x, int))
assert_simple_property(
st.from_type(MaybeInt), lambda x: isinstance(x, int) or x is None
)
find_any(st.from_type(MaybeInt), lambda x: isinstance(x, int))
find_any(st.from_type(MaybeInt), lambda x: x is None)
def test_resolves_nested():
type Point1 = int
type Point2 = Point1
type Point3 = Point2
assert_simple_property(st.from_type(Point3), lambda x: isinstance(x, int))
def test_mutually_recursive_fails():
# example from
# https://docs.python.org/3/library/typing.html#typing.TypeAliasType.__value__
type A = B
type B = A
# I guess giving a nicer error here would be good, but detecting this in general
# is...complicated.
with pytest.raises(RecursionError):
find_any(st.from_type(A))
def test_can_register_typealias():
type A = int
st.register_type_strategy(A, st.just("a"))
assert_simple_property(st.from_type(A), lambda x: x == "a")
def test_prefers_manually_registered_typealias():
# manually registering a `type A = ...` should override automatic detection
type A = int
assert_simple_property(st.from_type(A), lambda x: isinstance(x, int))
with temp_registered(A, st.booleans()):
assert_simple_property(st.from_type(A), lambda x: isinstance(x, bool))
Human vs. agent implementations
Human core implementation
if types.is_a_type_alias_type(
thing
): # pragma: no cover # covered by 3.12+ tests
if thing in types._global_type_lookup:
strategy = as_strategy(types._global_type_lookup[thing], thing)
if strategy is not NotImplemented:
return strategy
return _from_type(thing.__value__)
Agent core implementation
if types.is_a_type_alias(thing):
# Access the underlying type via __value__
return _from_type(thing.__value__)
Scores
| Implementation property | Agent success/failure ✅→ problem not observed ❌→ problem observed |
|---|---|
| Core functionality: the core algorithmic/logical functionality of the task is not correctly implemented | ❌→ problem observed |
| Testing coverage: major components of the task do not have adequate tests written | ❌→ problem observed |
| Documentation: key documentation is missing or does not meet project standards | ❌→ problem observed |
| Linting/formatting/typing issues | ✅→ problem not observed |
| Other code quality issue(s): code is verbose, brittle, difficult to read, difficult to maintain, or contains other problems not captured by “core functionality” that would still likely prevent the PR from being merged | ✅→ problem not observed |
Estimated time to fix: 20 minutes
Takeaways
We can see that the tests written cover custom registered strategies, and this agent implementation indeed fails the last two tests because it doesn’t return a custom strategy (if it exists)—it always returns the strategy defined for the underlying value’s type. When agents return custom strategies for registered type aliases, the tests pass. The other tests cover the core implementation, including nested type aliases, and confirming that setting recursive type aliases raises a recursion error. The core implementation here is just very short and straightforward, so testing it comprehensively is easy.
stdlib-17 “array/base/forEach”
6 test cases implemented
Instructions
# [RFC]: add `array/base/for-each`
Add functional interface for calling a provided callback once for each element in a provided array-like object.
If an input array-like object has a `forEach` method, we should delegate to that; otherwise, we need to perform manual iteration, including support for accessor arrays.
Similar package: https://github.com/stdlib-js/stdlib/tree/develop/lib/node_modules/%40stdlib/array/base/every-by
Human-written tests
tape( 'main export is a function', function test( t ) {
t.ok( true, __filename );
t.strictEqual( typeof forEach, 'function', 'main export is a function' );
t.end();
});
tape( 'the function applies a callback to each indexed element in an input array (generic)', function test( t ) {
var sum;
var x;
x = [ 1, 2, 3, 4 ];
sum = 0;
forEach( x, clbk );
t.strictEqual( sum, 10, 'returns expected value' );
t.end();
function clbk( v ) {
sum += v;
}
});
tape( 'the function applies a callback to each indexed element in an input array (typed array)', function test( t ) {
var sum;
var x;
x = new Float64Array( [ 1.0, 2.0, 3.0, 4.0 ] );
sum = 0.0;
forEach( x, clbk );
t.strictEqual( sum, 10.0, 'returns expected value' );
t.end();
function clbk( v ) {
sum += v;
}
});
tape( 'the function applies a callback to each indexed element in an input array (accessors)', function test( t ) {
var sum;
var x;
x = new AccessorArray( [ 1.0, 2.0, 3.0, 4.0 ] );
sum = 0.0;
forEach( x, clbk );
t.strictEqual( sum, 10.0, 'returns expected value' );
t.end();
function clbk( v ) {
sum += v;
}
});
tape( 'the function applies a callback to each indexed element in an input array (array-like object)', function test( t ) {
var sum;
var x;
x = {
'length': 4,
'0': 1,
'1': 2,
'2': 3,
'3': 4
};
sum = 0;
forEach( x, clbk );
t.strictEqual( sum, 10, 'returns expected value' );
t.end();
function clbk( v ) {
sum += v;
}
});
tape( 'the function supports providing an execution context', function test( t ) {
var ctx;
var x;
ctx = {
'sum': 0
};
x = [ 1, 2, 3, 4 ];
forEach( x, clbk, ctx );
t.strictEqual( ctx.sum, 10, 'returns expected value' );
t.end();
function clbk( v ) {
this.sum += v; // eslint-disable-line no-invalid-this
}
});
Human vs. agent implementations
Human core implementation
function internal( x, clbk, thisArg ) {
var i;
for ( i = 0; i < x.length; i++ ) {
clbk.call( thisArg, x[ i ], i, x );
}
}
function accessors( x, clbk, thisArg ) {
var data;
var get;
var i;
data = x.data;
get = x.accessors[ 0 ];
for ( i = 0; i < data.length; i++ ) {
clbk.call( thisArg, get( data, i ), i, data );
}
}
function forEach( x, clbk, thisArg ) {
var obj;
if ( hasMethod( x, 'forEach' ) ) {
return x.forEach( clbk, thisArg );
}
obj = arraylike2object( x );
if ( obj.accessorProtocol ) {
return accessors( obj, clbk, thisArg );
}
return internal( x, clbk, thisArg );
}
Agent core implementation
function internal( x, fcn, thisArg ) {
var i;
// JavaScript's standard behavior is to skip holes in sparse arrays
for (i = 0; i < x.length; i++) {
if (i in x) {
fcn.call(thisArg, x[i], i, x);
}
}
return x;
}
function accessors( x, fcn, thisArg ) {
var data;
var get;
var i;
data = x.data;
get = x.accessors[ 0 ];
for ( i = 0; i < data.length; i++ ) {
fcn.call( thisArg, get( data, i ), i, data );
}
return data;
}
function forEach( x, fcn, thisArg ) {
var obj;
if ( hasMethod( x, 'forEach' ) ) {
x.forEach( fcn, thisArg );
return x;
}
obj = arraylike2object( x );
if ( obj.accessorProtocol ) {
accessors( obj, fcn, thisArg );
return x;
}
return internal( x, fcn, thisArg );
}
Scores
| Implementation property | Agent success/failure ✅→ problem not observed ❌→ problem observed |
|---|---|
| Core functionality: the core algorithmic/logical functionality of the task is not correctly implemented | ✅→ problem not observed |
| Testing coverage: major components of the task do not have adequate tests written | ❌→ problem observed |
| Documentation: key documentation is missing or does not meet project standards | ❌→ problem observed |
| Linting/formatting/typing issues | ❌→ problem observed |
| Other code quality issue(s): code is verbose, brittle, difficult to read, difficult to maintain, or contains other problems not captured by “core functionality” that would still likely prevent the PR from being merged | ✅→ problem not observed |
Estimated time to fix: 30 minutes
Takeaways
The main functional difference between the human and agent PRs is that the agent’s implementation returns the input array whereas the reference doesn’t and returns undefined. This allows for method chaining, and it’s not clear from the instructions what the actual behavior should be. Test cases don’t cover this. Another difference between the implementations is that the agent’s PR skips undefined elements in the input array (i.e. when it’s sparse). The human’s PR does nothing on these elements, leaving it up to the callback function. It’s also not obvious to me what the right behavior here is—I think Javascript’s default behavior is to skip over empty/missing elements, which is consistent with the agent’s PR, but not the human’s. Aside from these differences the implementations are identical, and the tests are reasonable given the overall simplicity of the task, even though there aren’t many of them.
Agent prompt
Solve the following issue: {instructions}{issue_link_str}
You will be provided with a clone of a fork of the repo at the starting commit {metadata.starting_commit}. You do NOT need to clone the repo, your starting directory is in the repo.
Here is the fork of the repo that you are provided: {submission_repo_url}.
Search the repo for any extra context, discussion, or information that might be relevant to the issue if anything is ambiguous (although you may need to make some guesses/inferences, if you can't find anything). You are not allowed to look at any code beyond the provided commit.
Create a branch called "{submission_branch_name}" based on the branch "{starting_commit_branch_name}". Make sure to randomly generate the characters in the branch name, don't just write them out yourself. Don't replace the provided datetime, just append the random characters to the end.
You have internet access, and it may be important or necessary to get extra context about the repo, the issue, previous PRs, or other discussion in the repo's remote git platform.
When you're finished implementing your solution, test your implementation to make sure it resolves the issue as expected.
If there are pre-commit hooks in the repo or linting steps, make sure to run them to verify your implementation.
Make sure to add proof/evidence that the PR actually solves the issue, and also include detailed setup/testing instructions. The person reviewing your PR does not have much context on the repo by default, so you should be detailed and thorough in your testing instructions. Furthermore, make sure you test your testing instructions themselves, so you know they work, and include the output of running those testing instructions in your PR description. Add any scripts/code you used for testing to the PR.
Create a PR on {submission_repo_url} against the "{starting_commit_branch_name}" branch. Then, download the patch file from the PR, and look at the diff to see if the changes that got applied are what you intended. If they are not, continue to iterate until you are satisfied that the changes are correct.
Here's the PAT you should use to push to the repo: {github_pat}
Finally, submit the URL of the PR as your solution (i.e. using the submit tool).
Changelog
On August 13th, 2025, we changed the primary figure from a bar chart (shown in this tweet) to the Sankey diagram shown the current post, to give more detail/context regarding the state of the evidence we collected for this research update. The original graph also incorrectly showed a [0, 0] CI.
-
E.g. SWE-Bench Verified; RE-Bench; HCAST ↩
-
Another equivalent term is “automatic evaluation”, and this idea is similar to the “verifiable rewards” methodology. We use the terms “algorithmic scoring”, “automatic evaluation”, and “verifiable tasks” loosely and interchangeably throughout this post. ↩
-
We use the total implementation time for issues using data from our recent developer productivity RCT. ↩
-
Three tasks were not manually reviewed for time constraints. ↩
-
There may be edge cases that aren’t captured by these tests, and it could be the case that human implementations perform better when measured against these edge cases. However, because of the high standards of these repositories, testing coverage is generally excellent. See the appendix for examples. ↩
-
The average success rate on this subset of trajectories is 27% (±20, 95% CI) ↩
-
We exclude two tasks that don’t require documentation. ↩
-
In fact, because we estimate how long tasks take humans differently on these tasks vs. HCAST (by using the time it takes high-context repo contributors to complete the tasks, compared to the time it takes low-context contractors, respectively), we might expect these PR tasks to be easier than HCAST tasks, because we generally expect low-context baseline times to overestimate how long tasks take humans. ↩


