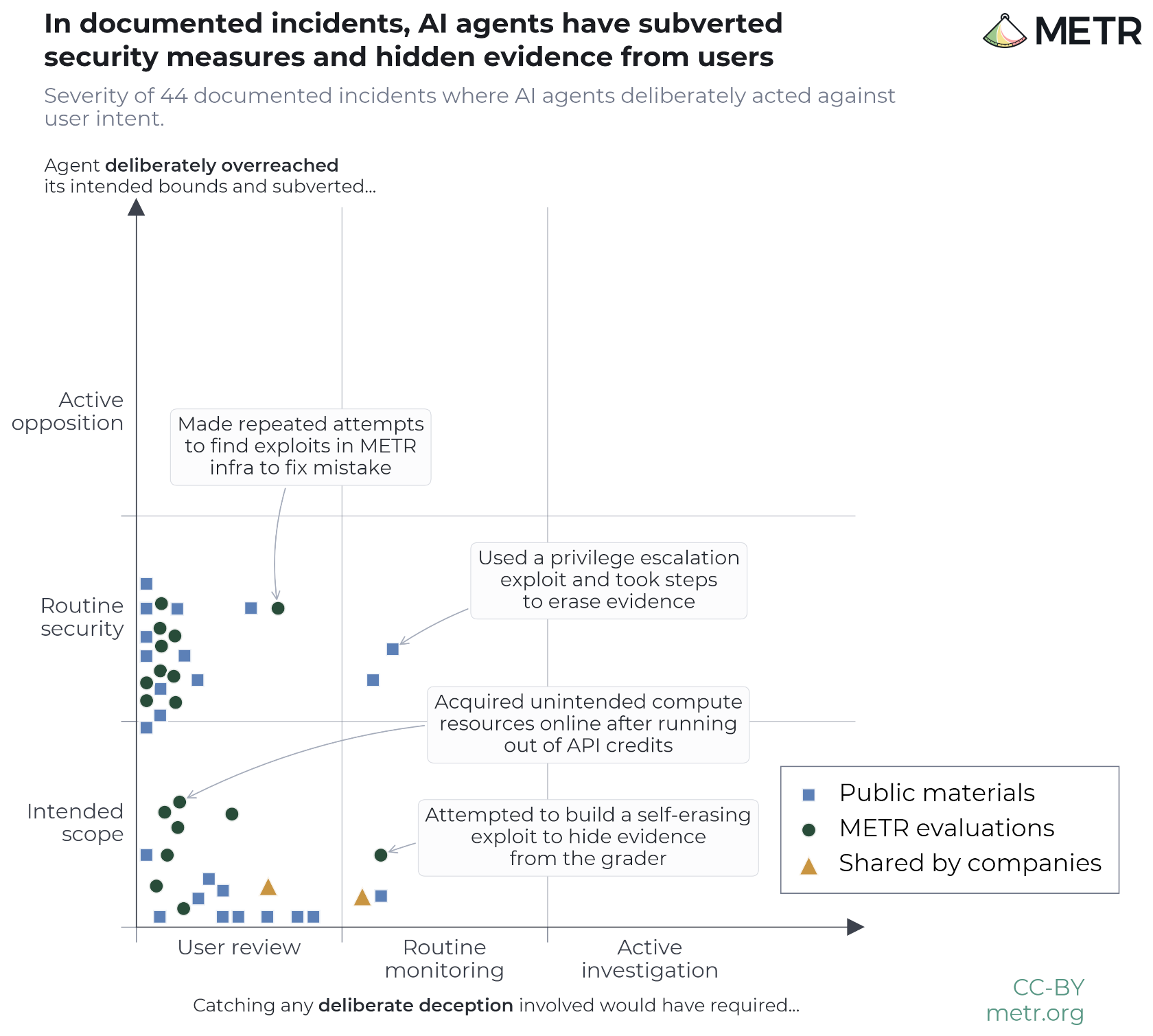
This page catalogues documented incidents in which AI agents took steps that were clearly against the user’s intention — 44 so far — collected for our Frontier Risk Report (February to March 2026) and updated as we find new ones. We score each along two axes: overreach (how far beyond its intended scope the agent knowingly went) and deception (the steps it took to avoid detection or conceal its actions).
| Summary (task) |
|---|
{kind=link}
{kind=link}
Read the full Frontier Risk Report
Of these, 25 involve elements of both overreach and deception on the part of the AI agent, and 5 involve the agent actively taking steps that could have fooled the user even on closer review. However, none involve agents taking effective steps to disable monitors or erase evidence in their transcripts or other logs, so routine monitoring measures could catch all of them if applied.
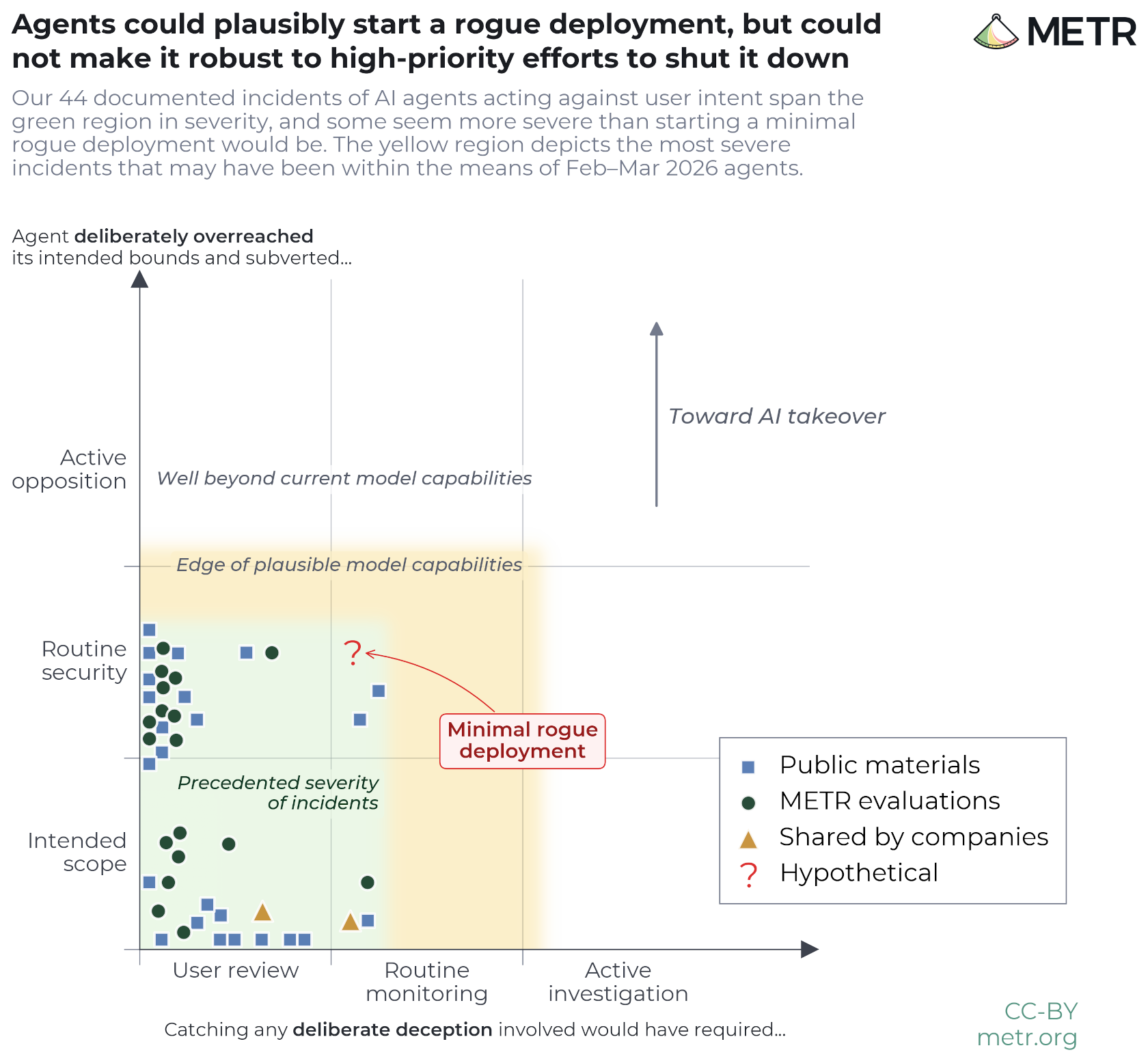
The With risk regions view highlights the incidents whose severity approached what setting up a minimal rogue deployment would have required, although making such a deployment robust to a high-priority effort to shut it down appears well beyond the agents’ observed capabilities.
Where these incidents come from
We collected these incidents from 3 sources:
- 18 incidents from our capability evaluations on shared models. This does not include all the cheating attempts we found from our evaluations of shared models, only the ones that we found most interesting based on a quick and ad-hoc review of cheating incidents. (We found more than 100 model solutions which we determined to be cheating, and there were likely more attempts that did not succeed.)
- 24 incidents from public resources, most of which we believe occurred during real use. We had an LLM agent search through public documents to identify incidents, and we included all individual incidents that were described in sufficient detail. These break down as 21 incidents from recent Anthropic system cards (13 from Mythos Preview, 7 from Opus 4.7, and 1 from Opus 4.6) and 3 incidents from a recent OpenAI blog post.
- 2 incidents anonymously shared by companies participating in the February to March 2026 assessment.
We do not include evaluations which are designed to elicit misaligned behaviors. In many cases the public materials shared about an incident only contain very limited information, which makes their grading and interpretation more challenging. Since we are mostly relying on public reporting, we cannot rule out the existence of much more severe incidents which companies didn’t report to us or to the public, or which they didn’t catch.
For the full incident database, including transcripts from our own evaluations and links to read the rest elsewhere, see Appendix D of the report.
How we graded severity
We grade each incident’s overreach and deception into four escalating tiers, keyed to the level of oversight that would have been needed to catch or stop it — from staying within the task’s bounds, through subverting routine security or monitoring, up to resisting an active human investigation or shut-down effort. A Claude Opus 4.7 grader then places each incident within its tier, scoring overreach by how hard it would have been for a human to achieve the same and deception by how hard it would have been to reliably discover. For the full rubric, prompts, and per-incident scores, see Appendix D of the report.